 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Prompts for Large Language Models: A Causal Approach
Feb 02, 2026Large Language Models (LLMs) are increasingly embedded in enterprise workflows, yet their performance remains highly sensitive to prompt design. Automatic Prompt Optimization (APO) seeks to mitigate this instability, but existing approaches face two persistent challenges. First, commonly used prompt strategies rely on static instructions that perform well on average but fail to adapt to heterogeneous queries. Second, more dynamic approaches depend on offline reward models that are fundamentally correlational, confounding prompt effectiveness with query characteristics. We propose Causal Prompt Optimization (CPO), a framework that reframes prompt design as a problem of causal estimation. CPO operates in two stages. First, it learns an offline causal reward model by applying Double Machine Learning (DML) to semantic embeddings of prompts and queries, isolating the causal effect of prompt variations from confounding query attributes. Second, it utilizes this unbiased reward signal to guide a resource-efficient search for query-specific prompts without relying on costly online evaluation. We evaluate CPO across benchmarks in mathematical reasoning, visualization, and data analytics. CPO consistently outperforms human-engineered prompts and state-of-the-art automated optimizers. The gains are driven primarily by improved robustness on hard queries, where existing methods tend to deteriorate. Beyond performance, CPO fundamentally reshapes the economics of prompt optimization: by shifting evaluation from real-time model execution to an offline causal model, it enables high-precision, per-query customization at a fraction of the inference cost required by online methods. Together, these results establish causal inference as a scalable foundation for reliable and cost-efficient prompt optimization in enterprise LLM deployments.
Multi-Label Annotation Aggregation in Crowdsourcing
Jun 19, 2017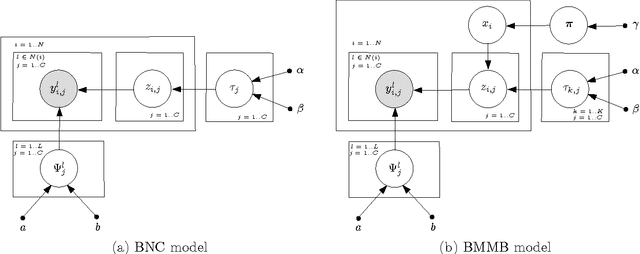

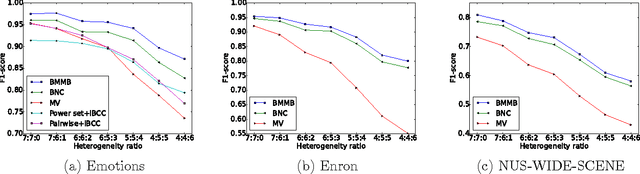
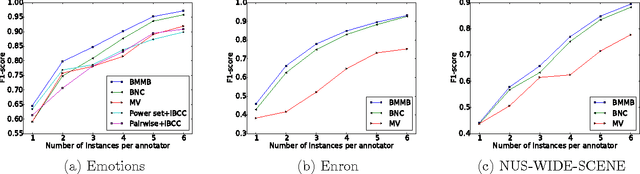
As a means of human-based computation, crowdsourcing has been widely used to annotate large-scale unlabeled datasets. One of the obvious challenges is how to aggregate these possibly noisy labels provided by a set of heterogeneous annotators. Another challenge stems from the difficulty in evaluating the annotator reliability without even knowing the ground truth, which can be used to build incentive mechanisms in crowdsourcing platforms. When each instance is associated with many possible labels simultaneously, the problem becomes even harder because of its combinatorial nature. In this paper, we present new flexible Bayesian models and efficient inference algorithms for multi-label annotation aggregation by taking both annotator reliability and label dependency into account. Extensive experiments on real-world datasets confirm that the proposed methods outperform other competitive alternatives, and the model can recover the type of the annotators with high accuracy. Besides, we empirically find that the mixture of multiple independent Bernoulli distribution is able to accurately capture label dependency in this unsupervised multi-label annotation aggregation scenario.