 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFFR: Spatial-Frequency Feature Reconstruction for Multispectral Aerial Object Detection
Nov 17, 2025Recent multispectral object detection methods have primarily focused on spatial-domain feature fusion based on CNNs or Transformers, while the potential of frequency-domain feature remains underexplored. In this work, we propose a novel Spatial and Frequency Feature Reconstruction method (SFFR) method, which leverages the spatial-frequency feature representation mechanisms of the Kolmogorov-Arnold Network (KAN) to reconstruct complementary representations in both spatial and frequency domains prior to feature fusion. The core components of SFFR are the proposed Frequency Component Exchange KAN (FCEKAN) module and Multi-Scale Gaussian KAN (MSGKAN) module. The FCEKAN introduces an innovative selective frequency component exchange strategy that effectively enhances the complementarity and consistency of cross-modal features based on the frequency feature of RGB and IR images. The MSGKAN module demonstrates excellent nonlinear feature modeling capability in the spatial domain. By leveraging multi-scale Gaussian basis functions, it effectively captures the feature variations caused by scale changes at different UAV flight altitudes, significantly enhancing the model's adaptability and robustness to scale variations. It is experimentally validated that our proposed FCEKAN and MSGKAN modules are complementary and can effectively capture the frequency and spatial semantic features respectively for better feature fusion. Extensive experiments on the SeaDroneSee, DroneVehicle and DVTOD datasets demonstrate the superior performance and significant advantages of the proposed method in UAV multispectral object perception task. Code will be available at https://github.com/qchenyu1027/SFFR.
IRDFusion: Iterative Relation-Map Difference guided Feature Fusion for Multispectral Object Detection
Sep 11, 2025Current multispectral object detection methods often retain extraneous background or noise during feature fusion, limiting perceptual performance.To address this, we propose an innovative feature fusion framework based on cross-modal feature contrastive and screening strategy, diverging from conventional approaches. The proposed method adaptively enhances salient structures by fusing object-aware complementary cross-modal features while suppressing shared background interference.Our solution centers on two novel, specially designed modules: the Mutual Feature Refinement Module (MFRM) and the Differential Feature Feedback Module (DFFM). The MFRM enhances intra- and inter-modal feature representations by modeling their relationships, thereby improving cross-modal alignment and discriminative power.Inspired by feedback differential amplifiers, the DFFM dynamically computes inter-modal differential features as guidance signals and feeds them back to the MFRM, enabling adaptive fusion of complementary information while suppressing common-mode noise across modalities. To enable robust feature learning, the MFRM and DFFM are integrated into a unified framework, which is formally formulated as an Iterative Relation-Map Differential Guided Feature Fusion mechanism, termed IRDFusion. IRDFusion enables high-quality cross-modal fusion by progressively amplifying salient relational signals through iterative feedback, while suppressing feature noise, leading to significant performance gains.In extensive experiments on FLIR, LLVIP and M$^3$FD datasets, IRDFusion achieves state-of-the-art performance and consistently outperforms existing methods across diverse challenging scenarios, demonstrating its robustness and effectiveness. Code will be available at https://github.com/61s61min/IRDFusion.git.
Improving underwater semantic segmentation with underwater image quality attention and muti-scale aggregation attention
Mar 30, 2025Underwater image understanding is crucial for both submarine navigation and seabed exploration. However, the low illumination in underwater environments degrades the imaging quality, which in turn seriously deteriorates the performance of underwater semantic segmentation, particularly for outlining the object region boundaries. To tackle this issue, we present UnderWater SegFormer (UWSegFormer), a transformer-based framework for semantic segmentation of low-quality underwater images. Firstly, we propose the Underwater Image Quality Attention (UIQA) module. This module enhances the representation of highquality semantic information in underwater image feature channels through a channel self-attention mechanism. In order to address the issue of loss of imaging details due to the underwater environment, the Multi-scale Aggregation Attention(MAA) module is proposed. This module aggregates sets of semantic features at different scales by extracting discriminative information from high-level features,thus compensating for the semantic loss of detail in underwater objects. Finally, during training, we introduce Edge Learning Loss (ELL) in order to enhance the model's learning of underwater object edges and improve the model's prediction accuracy. Experiments conducted on the SUIM and DUT-USEG (DUT) datasets have demonstrated that the proposed method has advantages in terms of segmentation completeness, boundary clarity, and subjective perceptual details when compared to SOTA methods. In addition, the proposed method achieves the highest mIoU of 82.12 and 71.41 on the SUIM and DUT datasets, respectively. Code will be available at https://github.com/SAWRJJ/UWSegFormer.
Topology-aware Mamba for Crack Segmentation in Structures
Oct 25, 2024
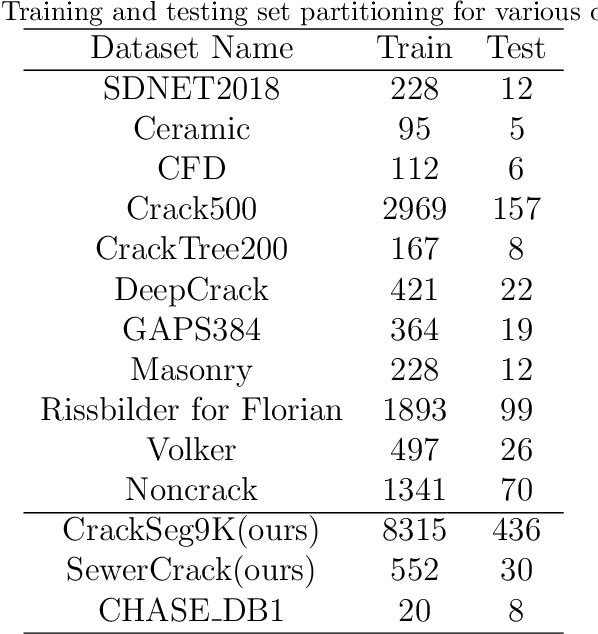
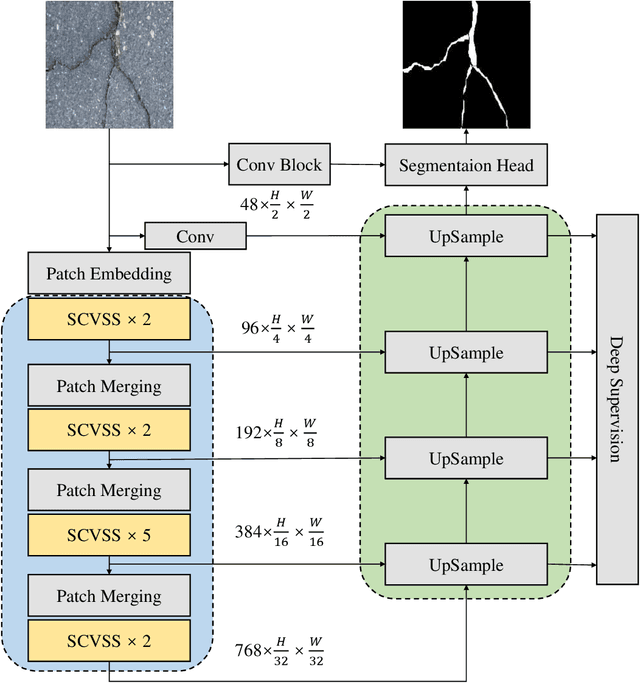
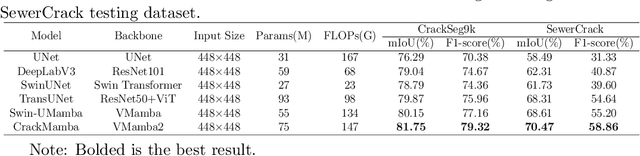
CrackMamba, a Mamba-based model, is designed for efficient and accurate crack segmentation for monitoring the structural health of infrastructure. Traditional Convolutional Neural Network (CNN) models struggle with limited receptive fields, and while Vision Transformers (ViT) improve segmentation accuracy, they are computationally intensive. CrackMamba addresses these challenges by utilizing the VMambaV2 with pre-trained ImageNet-1k weights as the encoder and a newly designed decoder for better performance. To handle the random and complex nature of crack development, a Snake Scan module is proposed to reshape crack feature sequences, enhancing feature extraction. Additionally, the three-branch Snake Conv VSS (SCVSS) block is proposed to target cracks more effectively. Experiments show that CrackMamba achieves state-of-the-art (SOTA) performance on the CrackSeg9k and SewerCrack datasets, and demonstrates competitive performance on the retinal vessel segmentation dataset CHASE\underline{~}DB1, highlighting its generalization capability. The code is publicly available at: {https://github.com/shengyu27/CrackMamba.}
Multi-label Sewer Pipe Defect Recognition with Mask Attention Feature Enhancement and Label Correlation Learning
Aug 01, 2024



The coexistence of multiple defect categories as well as the substantial class imbalance problem significantly impair the detection of sewer pipeline defects. To solve this problem, a multi-label pipe defect recognition method is proposed based on mask attention guided feature enhancement and label correlation learning. The proposed method can achieve current approximate state-of-the-art classification performance using just 1/16 of the Sewer-ML training dataset and exceeds the current best method by 11.87\% in terms of F2 metric on the full dataset, while also proving the superiority of the model. The major contribution of this study is the development of a more efficient model for identifying and locating multiple defects in sewer pipe images for a more accurate sewer pipeline condition assessment. Moreover, by employing class activation maps, our method can accurately pinpoint multiple defect categories in the image which demonstrates a strong model interpretability. Our code is available at \href{https://github.com/shengyu27/MA-Q2L}{\textcolor{black}{https://github.com/shengyu27/MA-Q2L.}
SSPNet: Scale and Spatial Priors Guided Generalizable and Interpretable Pedestrian Attribute Recognition
Dec 11, 2023



Global feature based Pedestrian Attribute Recognition (PAR) models are often poorly localized when using Grad-CAM for attribute response analysis, which has a significant impact on the interpretability, generalizability and performance. Previous researches have attempted to improve generalization and interpretation through meticulous model design, yet they often have neglected or underutilized effective prior information crucial for PAR. To this end, a novel Scale and Spatial Priors Guided Network (SSPNet) is proposed for PAR, which is mainly composed of the Adaptive Feature Scale Selection (AFSS) and Prior Location Extraction (PLE) modules. The AFSS module learns to provide reasonable scale prior information for different attribute groups, allowing the model to focus on different levels of feature maps with varying semantic granularity. The PLE module reveals potential attribute spatial prior information, which avoids unnecessary attention on irrelevant areas and lowers the risk of model over-fitting. More specifically, the scale prior in AFSS is adaptively learned from different layers of feature pyramid with maximum accuracy, while the spatial priors in PLE can be revealed from part feature with different granularity (such as image blocks, human pose keypoint and sparse sampling points). Besides, a novel IoU based attribute localization metric is proposed for Weakly-supervised Pedestrian Attribute Localization (WPAL) based on the improved Grad-CAM for attribute response mask. The experimental results on the intra-dataset and cross-dataset evaluations demonstrate the effectiveness of our proposed method in terms of mean accuracy (mA). Furthermore, it also achieves superior performance on the PCS dataset for attribute localization in terms of IoU. Code will be released at https://github.com/guotengg/SSPNet.
ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection
Aug 15, 2023Effective feature fusion of multispectral images plays a crucial role in multi-spectral object detection. Previous studies have demonstrated the effectiveness of feature fusion using convolutional neural networks, but these methods are sensitive to image misalignment due to the inherent deffciency in local-range feature interaction resulting in the performance degradation. To address this issue, a novel feature fusion framework of dual cross-attention transformers is proposed to model global feature interaction and capture complementary information across modalities simultaneously. This framework enhances the discriminability of object features through the query-guided cross-attention mechanism, leading to improved performance. However, stacking multiple transformer blocks for feature enhancement incurs a large number of parameters and high spatial complexity. To handle this, inspired by the human process of reviewing knowledge, an iterative interaction mechanism is proposed to share parameters among block-wise multimodal transformers, reducing model complexity and computation cost. The proposed method is general and effective to be integrated into different detection frameworks and used with different backbones. Experimental results on KAIST, FLIR, and VEDAI datasets show that the proposed method achieves superior performance and faster inference, making it suitable for various practical scenarios. Code will be available at https://github.com/chanchanchan97/ICAFusion.
Self-supervised Learning for Heterogeneous Graph via Structure Information based on Metapath
Sep 09, 2022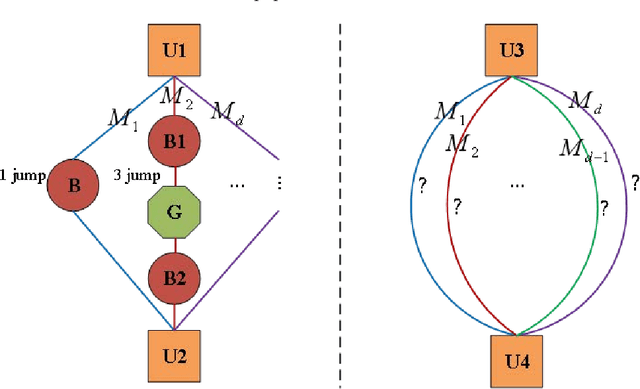
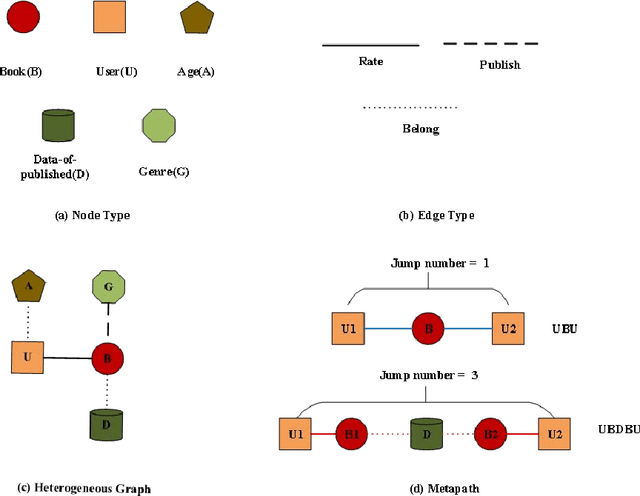
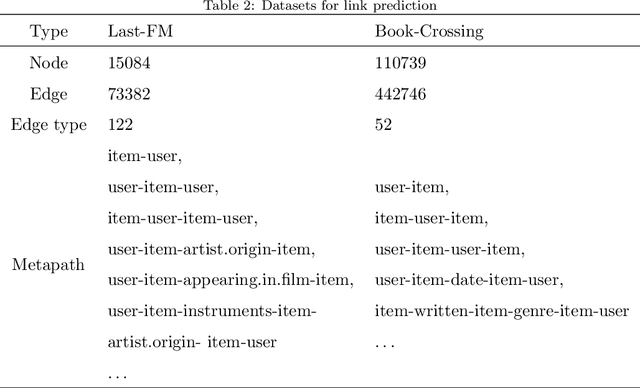
graph neural networks (GNNs) are the dominant paradigm for modeling and handling graph structure data by learning universal node representation. The traditional way of training GNNs depends on a great many labeled data, which results in high requirements on cost and time. In some special scene, it is even unavailable and impracticable. Self-supervised representation learning, which can generate labels by graph structure data itself, is a potential approach to tackle this problem. And turning to research on self-supervised learning problem for heterogeneous graphs is more challenging than dealing with homogeneous graphs, also there are fewer studies about it. In this paper, we propose a SElfsupervised learning method for heterogeneous graph via Structure Information based on Metapath (SESIM). The proposed model can construct pretext tasks by predicting jump number between nodes in each metapath to improve the representation ability of primary task. In order to predict jump number, SESIM uses data itself to generate labels, avoiding time-consuming manual labeling. Moreover, predicting jump number in each metapath can effectively utilize graph structure information, which is the essential property between nodes. Therefore, SESIM deepens the understanding of models for graph structure. At last, we train primary task and pretext tasks jointly, and use meta-learning to balance the contribution of pretext tasks for primary task. Empirical results validate the performance of SESIM method and demonstrate that this method can improve the representation ability of traditional neural networks on link prediction task and node classification task.
Multi-Scale Iterative Refinement Network for RGB-D Salient Object Detection
Jan 24, 2022


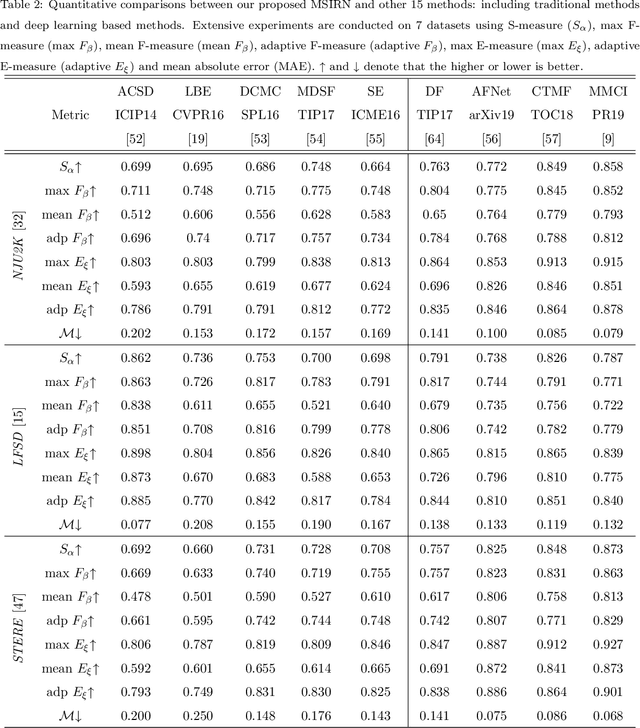
The extensive research leveraging RGB-D information has been exploited in salient object detection. However, salient visual cues appear in various scales and resolutions of RGB images due to semantic gaps at different feature levels. Meanwhile, similar salient patterns are available in cross-modal depth images as well as multi-scale versions. Cross-modal fusion and multi-scale refinement are still an open problem in RGB-D salient object detection task. In this paper, we begin by introducing top-down and bottom-up iterative refinement architecture to leverage multi-scale features, and then devise attention based fusion module (ABF) to address on cross-modal correlation. We conduct extensive experiments on seven public datasets. The experimental results show the effectiveness of our devised method
* 40 pages
Online Deep Learning based on Auto-Encoder
Jan 19, 2022Online learning is an important technical means for sketching massive real-time and high-speed data. Although this direction has attracted intensive attention, most of the literature in this area ignore the following three issues: (1) they think little of the underlying abstract hierarchical latent information existing in examples, even if extracting these abstract hierarchical latent representations is useful to better predict the class labels of examples; (2) the idea of preassigned model on unseen datapoints is not suitable for modeling streaming data with evolving probability distribution. This challenge is referred as model flexibility. And so, with this in minds, the online deep learning model we need to design should have a variable underlying structure; (3) moreover, it is of utmost importance to fusion these abstract hierarchical latent representations to achieve better classification performance, and we should give different weights to different levels of implicit representation information when dealing with the data streaming where the data distribution changes. To address these issues, we propose a two-phase Online Deep Learning based on Auto-Encoder (ODLAE). Based on auto-encoder, considering reconstruction loss, we extract abstract hierarchical latent representations of instances; Based on predictive loss, we devise two fusion strategies: the output-level fusion strategy, which is obtained by fusing the classification results of encoder each hidden layer; and feature-level fusion strategy, which is leveraged self-attention mechanism to fusion every hidden layer output. Finally, in order to improve the robustness of the algorithm, we also try to utilize the denoising auto-encoder to yield hierarchical latent representations. Experimental results on different datasets are presented to verify the validity of our proposed algorithm (ODLAE) outperforms several baselines.
* 30 pages