 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Deep Learning based on Auto-Encoder
Jan 19, 2022Online learning is an important technical means for sketching massive real-time and high-speed data. Although this direction has attracted intensive attention, most of the literature in this area ignore the following three issues: (1) they think little of the underlying abstract hierarchical latent information existing in examples, even if extracting these abstract hierarchical latent representations is useful to better predict the class labels of examples; (2) the idea of preassigned model on unseen datapoints is not suitable for modeling streaming data with evolving probability distribution. This challenge is referred as model flexibility. And so, with this in minds, the online deep learning model we need to design should have a variable underlying structure; (3) moreover, it is of utmost importance to fusion these abstract hierarchical latent representations to achieve better classification performance, and we should give different weights to different levels of implicit representation information when dealing with the data streaming where the data distribution changes. To address these issues, we propose a two-phase Online Deep Learning based on Auto-Encoder (ODLAE). Based on auto-encoder, considering reconstruction loss, we extract abstract hierarchical latent representations of instances; Based on predictive loss, we devise two fusion strategies: the output-level fusion strategy, which is obtained by fusing the classification results of encoder each hidden layer; and feature-level fusion strategy, which is leveraged self-attention mechanism to fusion every hidden layer output. Finally, in order to improve the robustness of the algorithm, we also try to utilize the denoising auto-encoder to yield hierarchical latent representations. Experimental results on different datasets are presented to verify the validity of our proposed algorithm (ODLAE) outperforms several baselines.
* 30 pages
Adaptive Online Incremental Learning for Evolving Data Streams
Jan 05, 2022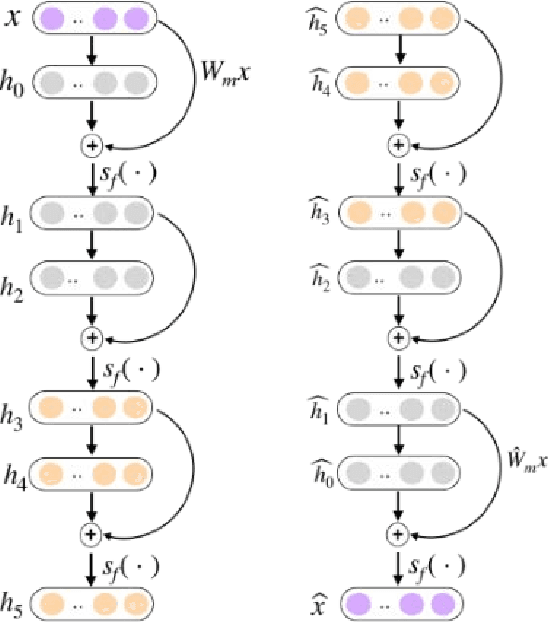
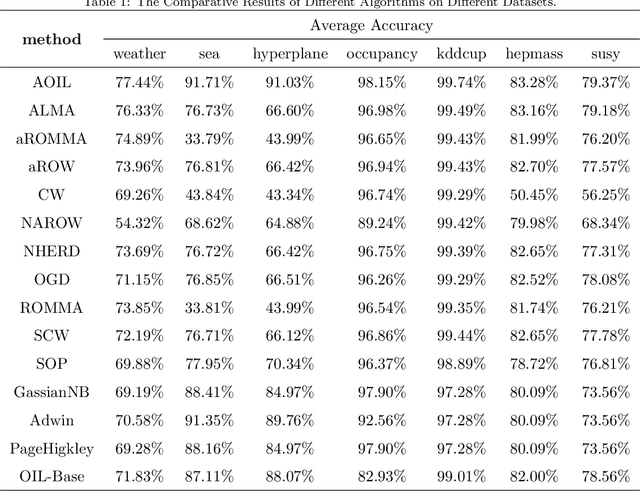
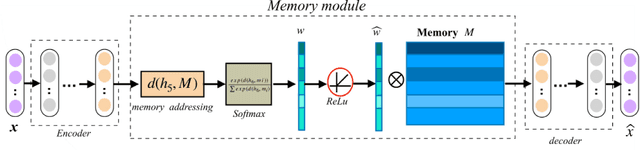
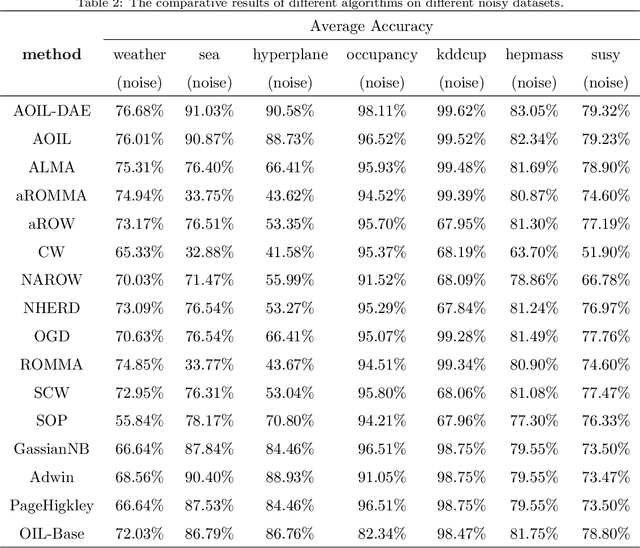
Recent years have witnessed growing interests in online incremental learning. However, there are three major challenges in this area. The first major difficulty is concept drift, that is, the probability distribution in the streaming data would change as the data arrives. The second major difficulty is catastrophic forgetting, that is, forgetting what we have learned before when learning new knowledge. The last one we often ignore is the learning of the latent representation. Only good latent representation can improve the prediction accuracy of the model. Our research builds on this observation and attempts to overcome these difficulties. To this end, we propose an Adaptive Online Incremental Learning for evolving data streams (AOIL). We use auto-encoder with the memory module, on the one hand, we obtained the latent features of the input, on the other hand, according to the reconstruction loss of the auto-encoder with memory module, we could successfully detect the existence of concept drift and trigger the update mechanism, adjust the model parameters in time. In addition, we divide features, which are derived from the activation of the hidden layers, into two parts, which are used to extract the common and private features respectively. By means of this approach, the model could learn the private features of the new coming instances, but do not forget what we have learned in the past (shared features), which reduces the occurrence of catastrophic forgetting. At the same time, to get the fusion feature vector we use the self-attention mechanism to effectively fuse the extracted features, which further improved the latent representation learning.
* 40 pages