 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMM Discriminant Analysis with Noisy Label for Each Class
Jan 25, 2022
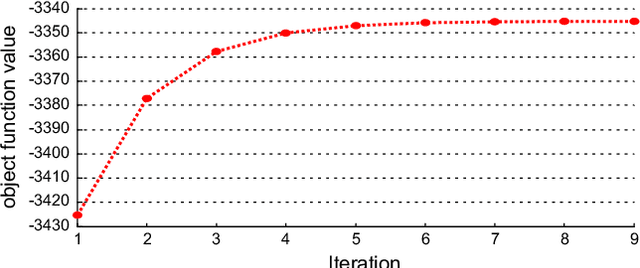

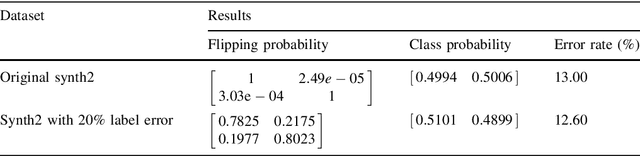
Real world datasets often contain noisy labels, and learning from such datasets using standard classification approaches may not produce the desired performance. In this paper, we propose a Gaussian Mixture Discriminant Analysis (GMDA) with noisy label for each class. We introduce flipping probability and class probability and use EM algorithms to solve the discriminant problem with label noise. We also provide the detail proofs of convergence. Experimental results on synthetic and real-world datasets show that the proposed approach notably outperforms other four state-of-art methods.
* 35 pages
Online Deep Learning based on Auto-Encoder
Jan 19, 2022Online learning is an important technical means for sketching massive real-time and high-speed data. Although this direction has attracted intensive attention, most of the literature in this area ignore the following three issues: (1) they think little of the underlying abstract hierarchical latent information existing in examples, even if extracting these abstract hierarchical latent representations is useful to better predict the class labels of examples; (2) the idea of preassigned model on unseen datapoints is not suitable for modeling streaming data with evolving probability distribution. This challenge is referred as model flexibility. And so, with this in minds, the online deep learning model we need to design should have a variable underlying structure; (3) moreover, it is of utmost importance to fusion these abstract hierarchical latent representations to achieve better classification performance, and we should give different weights to different levels of implicit representation information when dealing with the data streaming where the data distribution changes. To address these issues, we propose a two-phase Online Deep Learning based on Auto-Encoder (ODLAE). Based on auto-encoder, considering reconstruction loss, we extract abstract hierarchical latent representations of instances; Based on predictive loss, we devise two fusion strategies: the output-level fusion strategy, which is obtained by fusing the classification results of encoder each hidden layer; and feature-level fusion strategy, which is leveraged self-attention mechanism to fusion every hidden layer output. Finally, in order to improve the robustness of the algorithm, we also try to utilize the denoising auto-encoder to yield hierarchical latent representations. Experimental results on different datasets are presented to verify the validity of our proposed algorithm (ODLAE) outperforms several baselines.
* 30 pages
Multi-View representation learning in Multi-Task Scene
Jan 15, 2022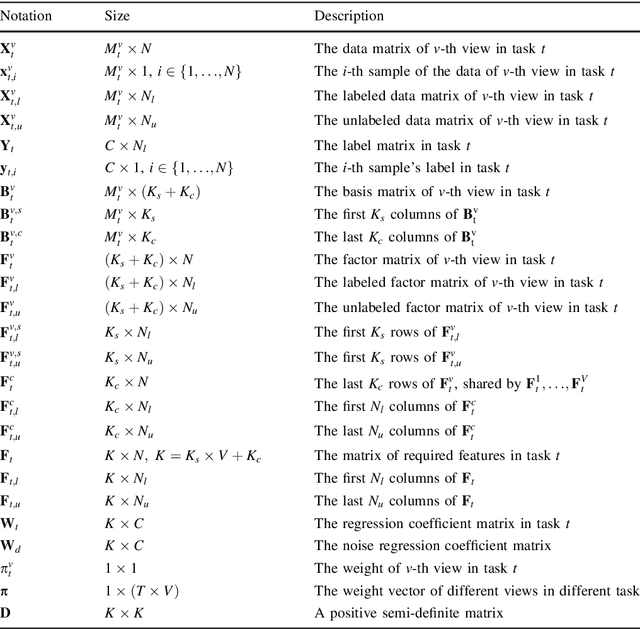
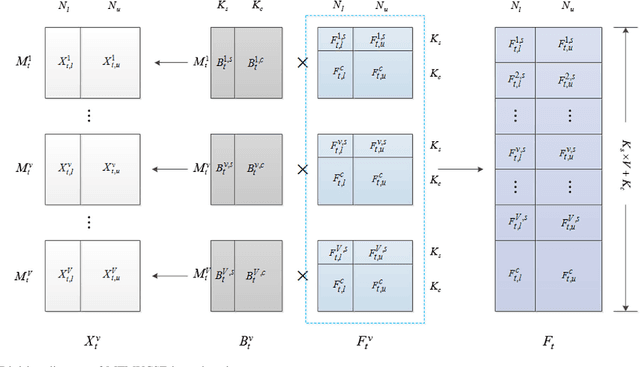
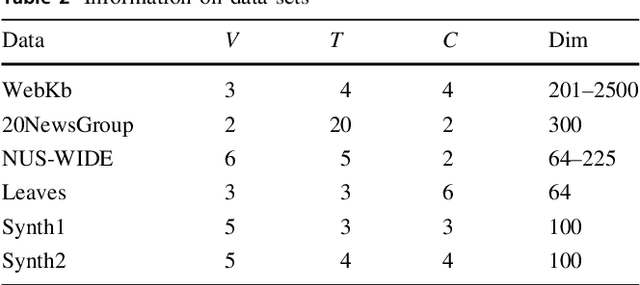
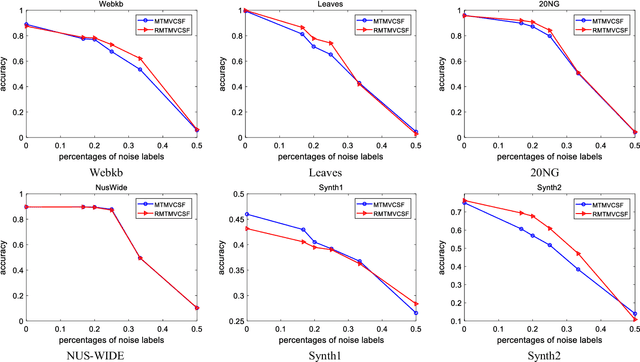
Over recent decades have witnessed considerable progress in whether multi-task learning or multi-view learning, but the situation that consider both learning scenes simultaneously has received not too much attention. How to utilize multiple views latent representation of each single task to improve each learning task performance is a challenge problem. Based on this, we proposed a novel semi-supervised algorithm, termed as Multi-Task Multi-View learning based on Common and Special Features (MTMVCSF). In general, multi-views are the different aspects of an object and every view includes the underlying common or special information of this object. As a consequence, we will mine multiple views jointly latent factor of each learning task which consists of each view special feature and the common feature of all views. By this way, the original multi-task multi-view data has degenerated into multi-task data, and exploring the correlations among multiple tasks enables to make an improvement on the performance of learning algorithm. Another obvious advantage of this approach is that we get latent representation of the set of unlabeled instances by the constraint of regression task with labeled instances. The performance of classification and semi-supervised clustering task in these latent representations perform obviously better than it in raw data. Furthermore, an anti-noise multi-task multi-view algorithm called AN-MTMVCSF is proposed, which has a strong adaptability to noise labels. The effectiveness of these algorithms is proved by a series of well-designed experiments on both real world and synthetic data.
* 32 pages
Auto-Encoder based Co-Training Multi-View Representation Learning
Jan 09, 2022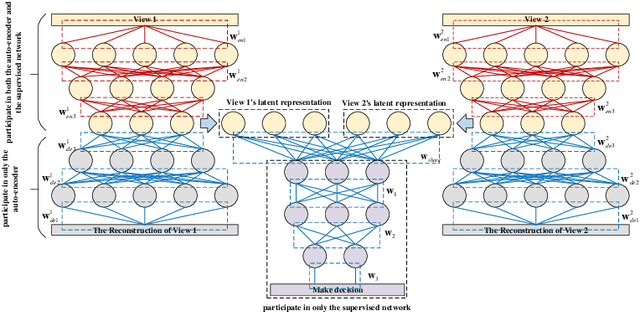

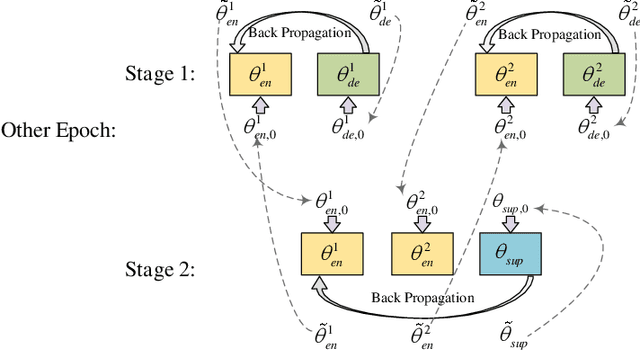
Multi-view learning is a learning problem that utilizes the various representations of an object to mine valuable knowledge and improve the performance of learning algorithm, and one of the significant directions of multi-view learning is sub-space learning. As we known, auto-encoder is a method of deep learning, which can learn the latent feature of raw data by reconstructing the input, and based on this, we propose a novel algorithm called Auto-encoder based Co-training Multi-View Learning (ACMVL), which utilizes both complementarity and consistency and finds a joint latent feature representation of multiple views. The algorithm has two stages, the first is to train auto-encoder of each view, and the second stage is to train a supervised network. Interestingly, the two stages share the weights partly and assist each other by co-training process. According to the experimental result, we can learn a well performed latent feature representation, and auto-encoder of each view has more powerful reconstruction ability than traditional auto-encoder.
Multi-View Non-negative Matrix Factorization Discriminant Learning via Cross Entropy Loss
Jan 08, 2022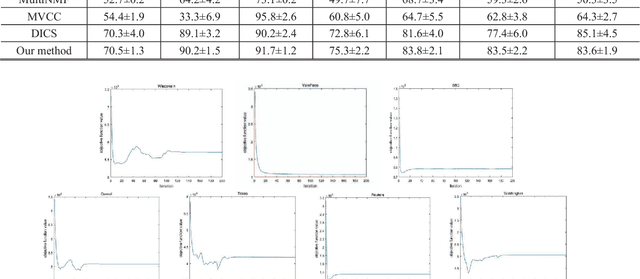
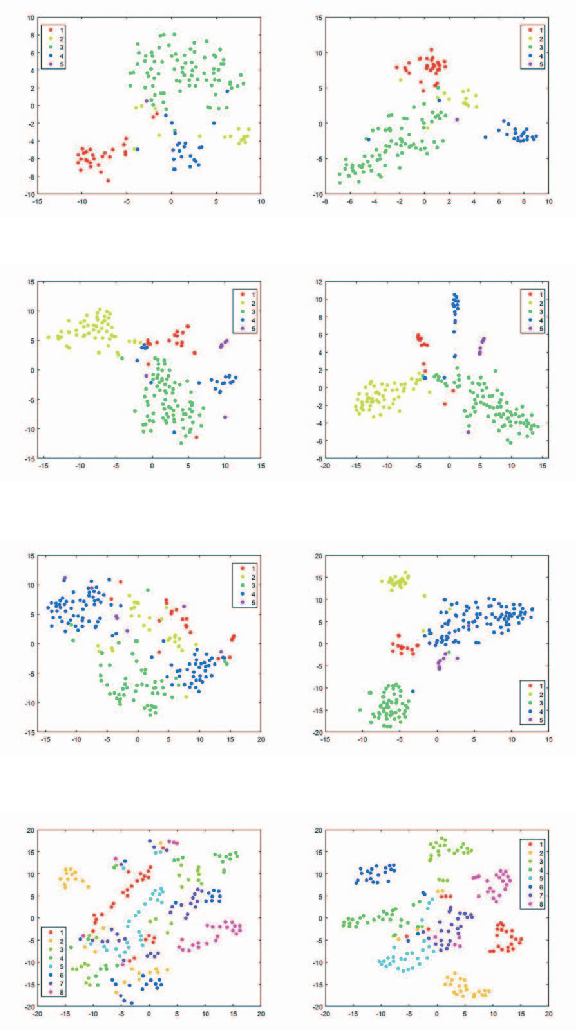
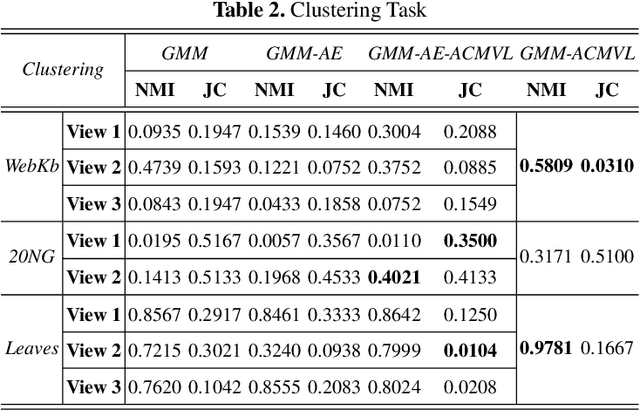
Multi-view learning accomplishes the task objectives of classification by leverag-ing the relationships between different views of the same object. Most existing methods usually focus on consistency and complementarity between multiple views. But not all of this information is useful for classification tasks. Instead, it is the specific discriminating information that plays an important role. Zhong Zhang et al. explore the discriminative and non-discriminative information exist-ing in common and view-specific parts among different views via joint non-negative matrix factorization. In this paper, we improve this algorithm on this ba-sis by using the cross entropy loss function to constrain the objective function better. At last, we implement better classification effect than original on the same data sets and show its superiority over many state-of-the-art algorithms.
Partially latent factors based multi-view subspace learning
Jan 06, 2022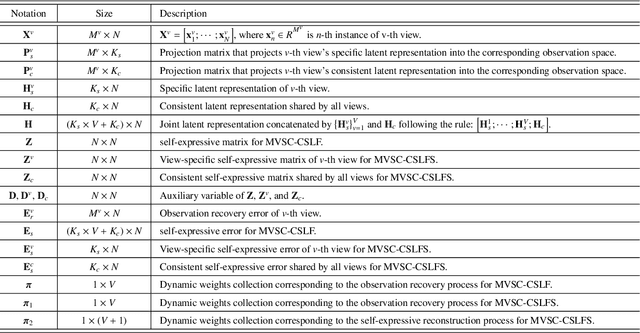
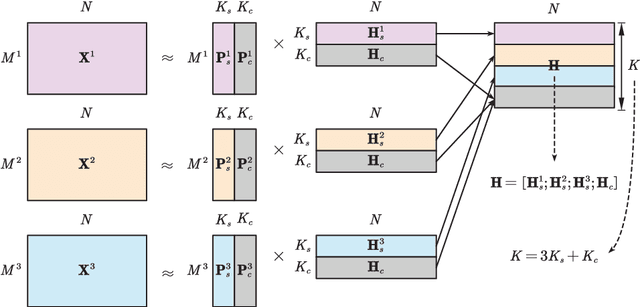
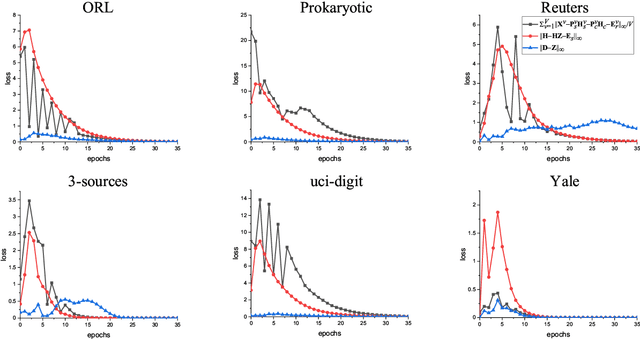
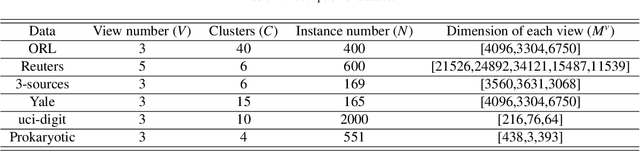
Multi-view subspace clustering always performs well in high-dimensional data analysis, but is sensitive to the quality of data representation. To this end, a two stage fusion strategy is proposed to embed representation learning into the process of multi-view subspace clustering. This paper first propose a novel matrix factorization method that can separate the coupling consistent and complementary information from observations of multiple views. Based on the obtained latent representations, we further propose two subspace clustering strategies: feature-level fusion and subspace-level hierarchical strategy. Feature-level method concatenates all kinds of latent representations from multiple views, and the original problem therefore degenerates to a single-view subspace clustering process. Subspace-level hierarchical method performs different self-expressive reconstruction processes on the corresponding complementary and consistent latent representations coming from each view, i.e. the prior constraints imposed on different types of subspace representations are related to the appropriate input factors. Finally, extensive experimental results on real-world datasets demonstrate the superiority of our proposed methods by comparing against some state-of-the-art subspace clustering algorithms.
Multi-view Subspace Adaptive Learning via Autoencoder and Attention
Jan 01, 2022
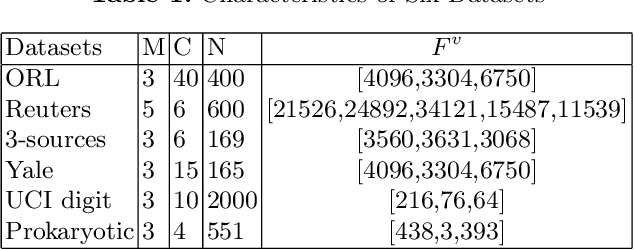

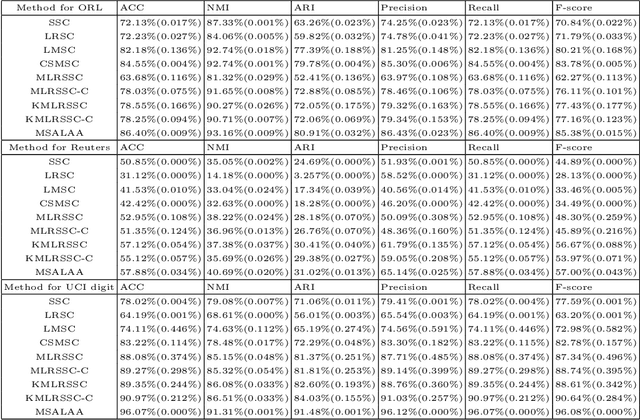
Multi-view learning can cover all features of data samples more comprehensively, so multi-view learning has attracted widespread attention. Traditional subspace clustering methods, such as sparse subspace clustering (SSC) and low-ranking subspace clustering (LRSC), cluster the affinity matrix for a single view, thus ignoring the problem of fusion between views. In our article, we propose a new Multiview Subspace Adaptive Learning based on Attention and Autoencoder (MSALAA). This method combines a deep autoencoder and a method for aligning the self-representations of various views in Multi-view Low-Rank Sparse Subspace Clustering (MLRSSC), which can not only increase the capability to non-linearity fitting, but also can meets the principles of consistency and complementarity of multi-view learning. We empirically observe significant improvement over existing baseline methods on six real-life datasets.
Self-attention Multi-view Representation Learning with Diversity-promoting Complementarity
Jan 01, 2022
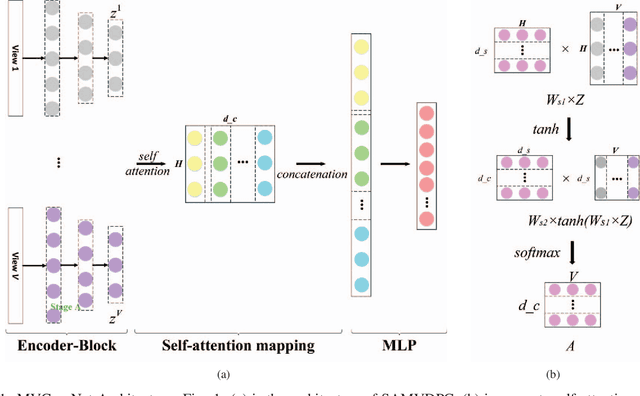
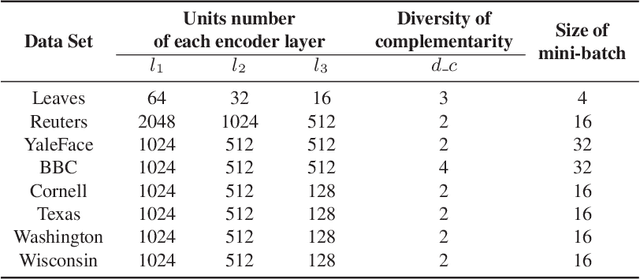
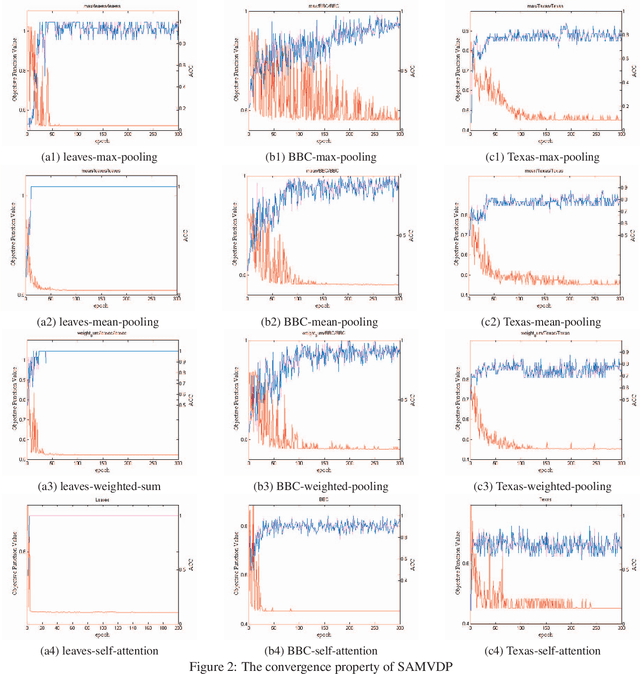
Multi-view learning attempts to generate a model with a better performance by exploiting the consensus and/or complementarity among multi-view data. However, in terms of complementarity, most existing approaches only can find representations with single complementarity rather than complementary information with diversity. In this paper, to utilize both complementarity and consistency simultaneously, give free rein to the potential of deep learning in grasping diversity-promoting complementarity for multi-view representation learning, we propose a novel supervised multi-view representation learning algorithm, called Self-Attention Multi-View network with Diversity-Promoting Complementarity (SAMVDPC), which exploits the consistency by a group of encoders, uses self-attention to find complementary information entailing diversity. Extensive experiments conducted on eight real-world datasets have demonstrated the effectiveness of our proposed method, and show its superiority over several baseline methods, which only consider single complementary information.
Attentive Multi-View Deep Subspace Clustering Net
Dec 23, 2021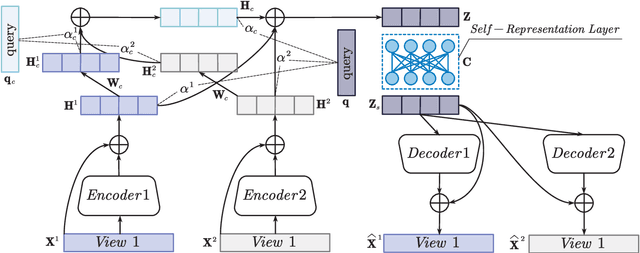
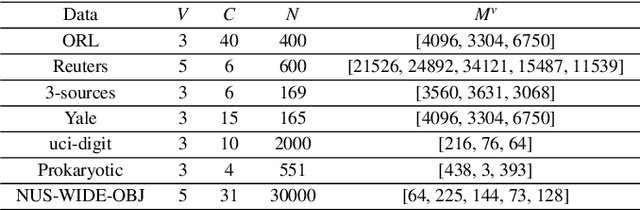
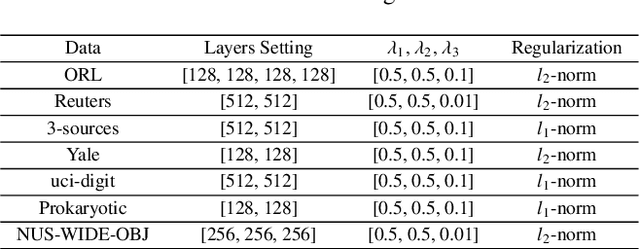
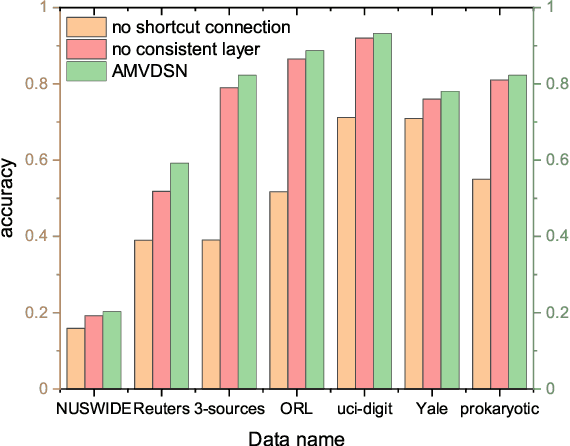
In this paper, we propose a novel Attentive Multi-View Deep Subspace Nets (AMVDSN), which deeply explores underlying consistent and view-specific information from multiple views and fuse them by considering each view's dynamic contribution obtained by attention mechanism. Unlike most multi-view subspace learning methods that they directly reconstruct data points on raw data or only consider consistency or complementarity when learning representation in deep or shallow space, our proposed method seeks to find a joint latent representation that explicitly considers both consensus and view-specific information among multiple views, and then performs subspace clustering on learned joint latent representation.Besides, different views contribute differently to representation learning, we therefore introduce attention mechanism to derive dynamic weight for each view, which performs much better than previous fusion methods in the field of multi-view subspace clustering. The proposed algorithm is intuitive and can be easily optimized just by using Stochastic Gradient Descent (SGD) because of the neural network framework, which also provides strong non-linear characterization capability compared with traditional subspace clustering approaches. The experimental results on seven real-world data sets have demonstrated the effectiveness of our proposed algorithm against some state-of-the-art subspace learning approaches.