 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-attention Multi-view Representation Learning with Diversity-promoting Complementarity
Paper and Code
Jan 01, 2022
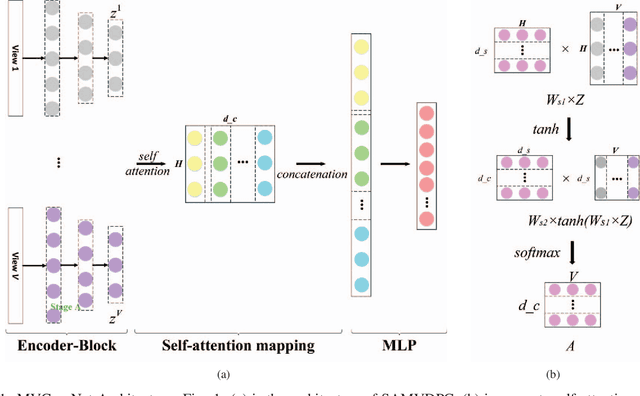
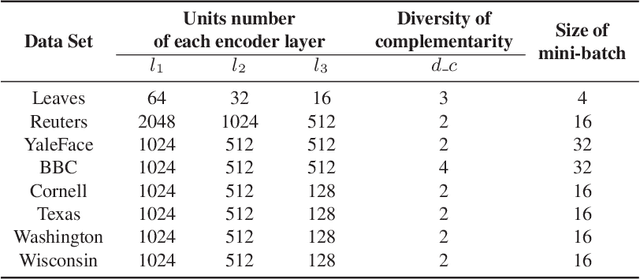
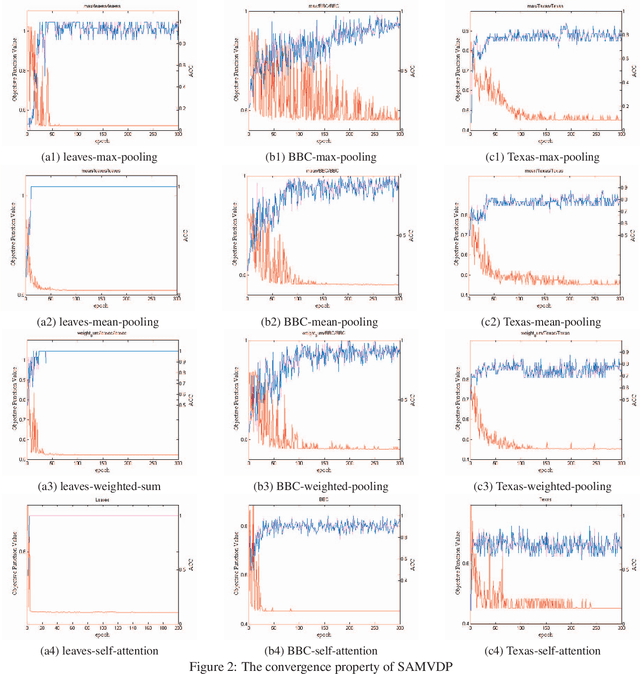
Multi-view learning attempts to generate a model with a better performance by exploiting the consensus and/or complementarity among multi-view data. However, in terms of complementarity, most existing approaches only can find representations with single complementarity rather than complementary information with diversity. In this paper, to utilize both complementarity and consistency simultaneously, give free rein to the potential of deep learning in grasping diversity-promoting complementarity for multi-view representation learning, we propose a novel supervised multi-view representation learning algorithm, called Self-Attention Multi-View network with Diversity-Promoting Complementarity (SAMVDPC), which exploits the consistency by a group of encoders, uses self-attention to find complementary information entailing diversity. Extensive experiments conducted on eight real-world datasets have demonstrated the effectiveness of our proposed method, and show its superiority over several baseline methods, which only consider single complementary information.