 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modular Algorithm for Non-Stationary Online Convex-Concave Optimization
Sep 09, 2025



This paper investigates the problem of Online Convex-Concave Optimization, which extends Online Convex Optimization to two-player time-varying convex-concave games. The goal is to minimize the dynamic duality gap (D-DGap), a critical performance measure that evaluates players' strategies against arbitrary comparator sequences. Existing algorithms fail to deliver optimal performance, particularly in stationary or predictable environments. To address this, we propose a novel modular algorithm with three core components: an Adaptive Module that dynamically adjusts to varying levels of non-stationarity, a Multi-Predictor Aggregator that identifies the best predictor among multiple candidates, and an Integration Module that effectively combines their strengths. Our algorithm achieves a minimax optimal D-DGap upper bound, up to a logarithmic factor, while also ensuring prediction error-driven D-DGap bounds. The modular design allows for the seamless replacement of components that regulate adaptability to dynamic environments, as well as the incorporation of components that integrate ``side knowledge'' from multiple predictors. Empirical results further demonstrate the effectiveness and adaptability of the proposed method.
Proximal Point Method for Online Saddle Point Problem
Jul 05, 2024This paper focuses on the online saddle point problem, which involves a sequence of two-player time-varying convex-concave games. Considering the nonstationarity of the environment, we adopt the duality gap and the dynamic Nash equilibrium regret as performance metrics for algorithm design. We present three variants of the proximal point method: the Online Proximal Point Method~(OPPM), the Optimistic OPPM~(OptOPPM), and the OptOPPM with multiple predictors. Each algorithm guarantees upper bounds for both the duality gap and dynamic Nash equilibrium regret, achieving near-optimality when measured against the duality gap. Specifically, in certain benign environments, such as sequences of stationary payoff functions, these algorithms maintain a nearly constant metric bound. Experimental results further validate the effectiveness of these algorithms. Lastly, this paper discusses potential reliability concerns associated with using dynamic Nash equilibrium regret as a performance metric.
Online Saddle Point Problem and Online Convex-Concave Optimization
Dec 15, 2023Centered around solving the Online Saddle Point problem, this paper introduces the Online Convex-Concave Optimization (OCCO) framework, which involves a sequence of two-player time-varying convex-concave games. We propose the generalized duality gap (Dual-Gap) as the performance metric and establish the parallel relationship between OCCO with Dual-Gap and Online Convex Optimization (OCO) with regret. To demonstrate the natural extension of OCCO from OCO, we develop two algorithms, the implicit online mirror descent-ascent and its optimistic variant. Analysis reveals that their duality gaps share similar expression forms with the corresponding dynamic regrets arising from implicit updates in OCO. Empirical results further substantiate the effectiveness of our algorithms. Simultaneously, we unveil that the dynamic Nash equilibrium regret, which was initially introduced in a recent paper, has inherent defects.
Online Continual Learning via the Knowledge Invariant and Spread-out Properties
Feb 02, 2023The goal of continual learning is to provide intelligent agents that are capable of learning continually a sequence of tasks using the knowledge obtained from previous tasks while performing well on prior tasks. However, a key challenge in this continual learning paradigm is catastrophic forgetting, namely adapting a model to new tasks often leads to severe performance degradation on prior tasks. Current memory-based approaches show their success in alleviating the catastrophic forgetting problem by replaying examples from past tasks when new tasks are learned. However, these methods are infeasible to transfer the structural knowledge from previous tasks i.e., similarities or dissimilarities between different instances. Furthermore, the learning bias between the current and prior tasks is also an urgent problem that should be solved. In this work, we propose a new method, named Online Continual Learning via the Knowledge Invariant and Spread-out Properties (OCLKISP), in which we constrain the evolution of the embedding features via Knowledge Invariant and Spread-out Properties (KISP). Thus, we can further transfer the inter-instance structural knowledge of previous tasks while alleviating the forgetting due to the learning bias. We empirically evaluate our proposed method on four popular benchmarks for continual learning: Split CIFAR 100, Split SVHN, Split CUB200 and Split Tiny-Image-Net. The experimental results show the efficacy of our proposed method compared to the state-of-the-art continual learning algorithms.
* 30 pages
$β$-CapsNet: Learning Disentangled Representation for CapsNet by Information Bottleneck
Sep 12, 2022We present a framework for learning disentangled representation of CapsNet by information bottleneck constraint that distills information into a compact form and motivates to learn an interpretable factorized capsule. In our $\beta$-CapsNet framework, hyperparameter $\beta$ is utilized to trade-off disentanglement and other tasks, variational inference is utilized to convert the information bottleneck term into a KL divergence that is approximated as a constraint on the mean of the capsule. For supervised learning, class independent mask vector is used for understanding the types of variations synthetically irrespective of the image class, we carry out extensive quantitative and qualitative experiments by tuning the parameter $\beta$ to figure out the relationship between disentanglement, reconstruction and classfication performance. Furthermore, the unsupervised $\beta$-CapsNet and the corresponding dynamic routing algorithm is proposed for learning disentangled capsule in an unsupervised manner, extensive empirical evaluations suggest that our $\beta$-CapsNet achieves state-of-the-art disentanglement performance compared to CapsNet and various baselines on several complex datasets both in supervision and unsupervised scenes.
Online Continual Learning via the Meta-learning Update with Multi-scale Knowledge Distillation and Data Augmentation
Sep 12, 2022



Continual learning aims to rapidly and continually learn the current task from a sequence of tasks. Compared to other kinds of methods, the methods based on experience replay have shown great advantages to overcome catastrophic forgetting. One common limitation of this method is the data imbalance between the previous and current tasks, which would further aggravate forgetting. Moreover, how to effectively address the stability-plasticity dilemma in this setting is also an urgent problem to be solved. In this paper, we overcome these challenges by proposing a novel framework called Meta-learning update via Multi-scale Knowledge Distillation and Data Augmentation (MMKDDA). Specifically, we apply multiscale knowledge distillation to grasp the evolution of long-range and short-range spatial relationships at different feature levels to alleviate the problem of data imbalance. Besides, our method mixes the samples from the episodic memory and current task in the online continual training procedure, thus alleviating the side influence due to the change of probability distribution. Moreover, we optimize our model via the meta-learning update resorting to the number of tasks seen previously, which is helpful to keep a better balance between stability and plasticity. Finally, our experimental evaluation on four benchmark datasets shows the effectiveness of the proposed MMKDDA framework against other popular baselines, and ablation studies are also conducted to further analyze the role of each component in our framework.
Self-supervised Learning for Heterogeneous Graph via Structure Information based on Metapath
Sep 09, 2022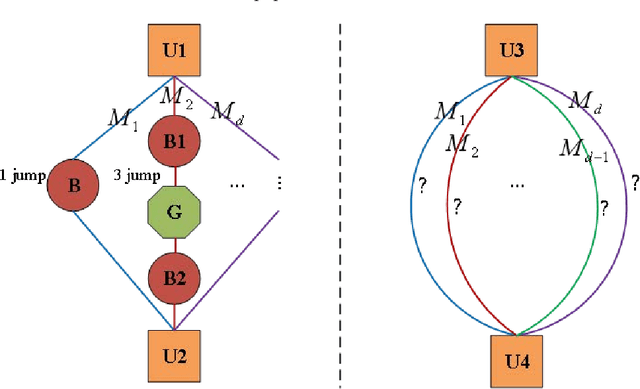
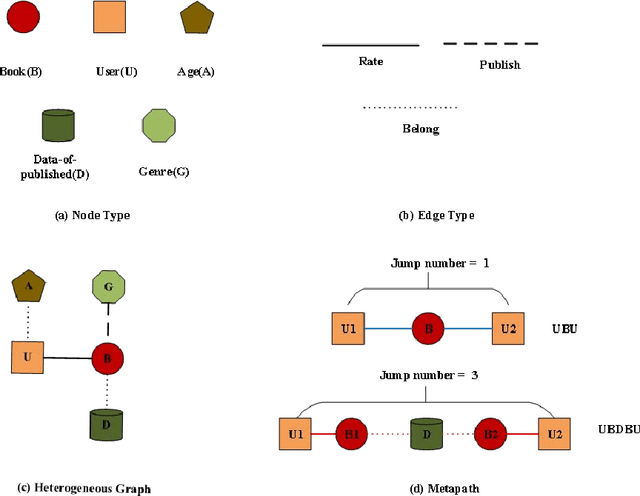
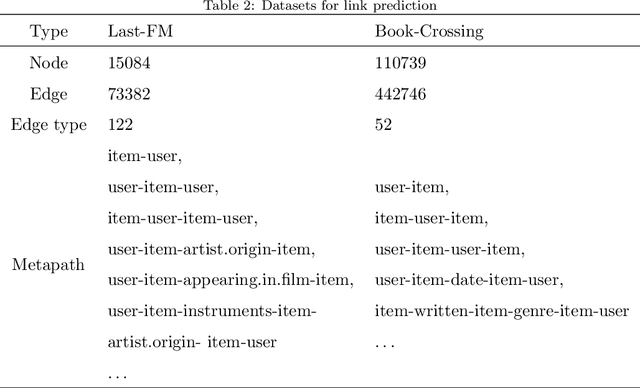
graph neural networks (GNNs) are the dominant paradigm for modeling and handling graph structure data by learning universal node representation. The traditional way of training GNNs depends on a great many labeled data, which results in high requirements on cost and time. In some special scene, it is even unavailable and impracticable. Self-supervised representation learning, which can generate labels by graph structure data itself, is a potential approach to tackle this problem. And turning to research on self-supervised learning problem for heterogeneous graphs is more challenging than dealing with homogeneous graphs, also there are fewer studies about it. In this paper, we propose a SElfsupervised learning method for heterogeneous graph via Structure Information based on Metapath (SESIM). The proposed model can construct pretext tasks by predicting jump number between nodes in each metapath to improve the representation ability of primary task. In order to predict jump number, SESIM uses data itself to generate labels, avoiding time-consuming manual labeling. Moreover, predicting jump number in each metapath can effectively utilize graph structure information, which is the essential property between nodes. Therefore, SESIM deepens the understanding of models for graph structure. At last, we train primary task and pretext tasks jointly, and use meta-learning to balance the contribution of pretext tasks for primary task. Empirical results validate the performance of SESIM method and demonstrate that this method can improve the representation ability of traditional neural networks on link prediction task and node classification task.
Selecting Related Knowledge via Efficient Channel Attention for Online Continual Learning
Sep 09, 2022

Continual learning aims to learn a sequence of tasks by leveraging the knowledge acquired in the past in an online-learning manner while being able to perform well on all previous tasks, this ability is crucial to the artificial intelligence (AI) system, hence continual learning is more suitable for most real-word and complex applicative scenarios compared to the traditional learning pattern. However, the current models usually learn a generic representation base on the class label on each task and an effective strategy is selected to avoid catastrophic forgetting. We postulate that selecting the related and useful parts only from the knowledge obtained to perform each task is more effective than utilizing the whole knowledge. Based on this fact, in this paper we propose a new framework, named Selecting Related Knowledge for Online Continual Learning (SRKOCL), which incorporates an additional efficient channel attention mechanism to pick the particular related knowledge for every task. Our model also combines experience replay and knowledge distillation to circumvent the catastrophic forgetting. Finally, extensive experiments are conducted on different benchmarks and the competitive experimental results demonstrate that our proposed SRKOCL is a promised approach against the state-of-the-art.
Optimistic Online Convex Optimization in Dynamic Environments
Mar 28, 2022In this paper, we study the optimistic online convex optimization problem in dynamic environments. Existing works have shown that Ader enjoys an $O\left(\sqrt{\left(1+P_T\right)T}\right)$ dynamic regret upper bound, where $T$ is the number of rounds, and $P_T$ is the path length of the reference strategy sequence. However, Ader is not environment-adaptive. Based on the fact that optimism provides a framework for implementing environment-adaptive, we replace Greedy Projection (GP) and Normalized Exponentiated Subgradient (NES) in Ader with Optimistic-GP and Optimistic-NES respectively, and name the corresponding algorithm ONES-OGP. We also extend the doubling trick to the adaptive trick, and introduce three characteristic terms naturally arise from optimism, namely $M_T$, $\widetilde{M}_T$ and $V_T+1_{L^2\rho\left(\rho+2 P_T\right)\leqslant\varrho^2 V_T}D_T$, to replace the dependence of the dynamic regret upper bound on $T$. We elaborate ONES-OGP with adaptive trick and its subgradient variation version, all of which are environment-adaptive.
GMM Discriminant Analysis with Noisy Label for Each Class
Jan 25, 2022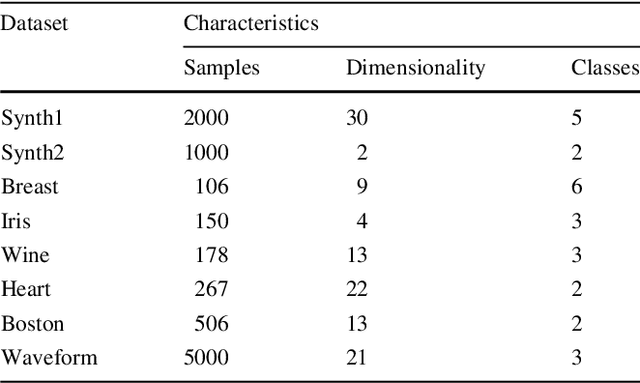
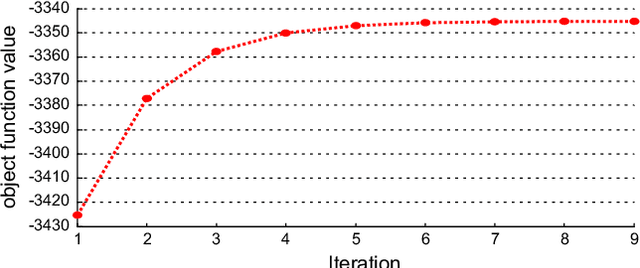

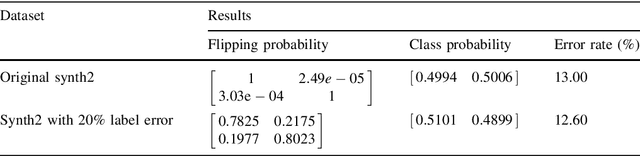
Real world datasets often contain noisy labels, and learning from such datasets using standard classification approaches may not produce the desired performance. In this paper, we propose a Gaussian Mixture Discriminant Analysis (GMDA) with noisy label for each class. We introduce flipping probability and class probability and use EM algorithms to solve the discriminant problem with label noise. We also provide the detail proofs of convergence. Experimental results on synthetic and real-world datasets show that the proposed approach notably outperforms other four state-of-art methods.
* 35 pages