 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Deep Learning based on Auto-Encoder
Jan 19, 2022Online learning is an important technical means for sketching massive real-time and high-speed data. Although this direction has attracted intensive attention, most of the literature in this area ignore the following three issues: (1) they think little of the underlying abstract hierarchical latent information existing in examples, even if extracting these abstract hierarchical latent representations is useful to better predict the class labels of examples; (2) the idea of preassigned model on unseen datapoints is not suitable for modeling streaming data with evolving probability distribution. This challenge is referred as model flexibility. And so, with this in minds, the online deep learning model we need to design should have a variable underlying structure; (3) moreover, it is of utmost importance to fusion these abstract hierarchical latent representations to achieve better classification performance, and we should give different weights to different levels of implicit representation information when dealing with the data streaming where the data distribution changes. To address these issues, we propose a two-phase Online Deep Learning based on Auto-Encoder (ODLAE). Based on auto-encoder, considering reconstruction loss, we extract abstract hierarchical latent representations of instances; Based on predictive loss, we devise two fusion strategies: the output-level fusion strategy, which is obtained by fusing the classification results of encoder each hidden layer; and feature-level fusion strategy, which is leveraged self-attention mechanism to fusion every hidden layer output. Finally, in order to improve the robustness of the algorithm, we also try to utilize the denoising auto-encoder to yield hierarchical latent representations. Experimental results on different datasets are presented to verify the validity of our proposed algorithm (ODLAE) outperforms several baselines.
* 30 pages
Multi-View representation learning in Multi-Task Scene
Jan 15, 2022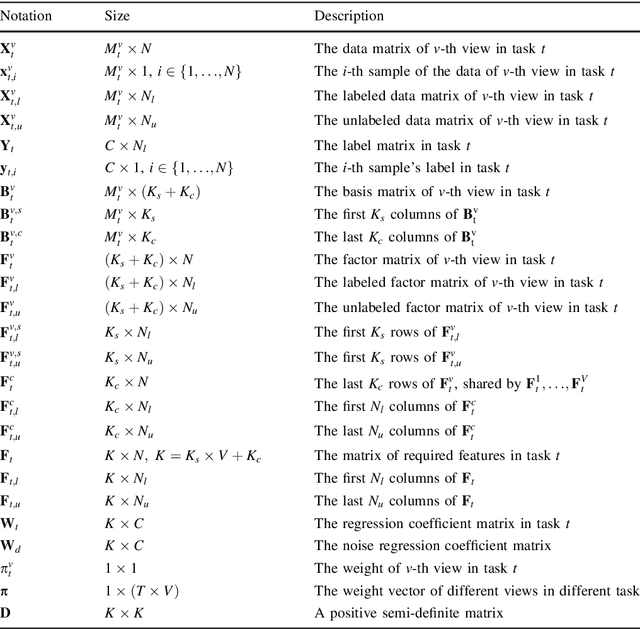
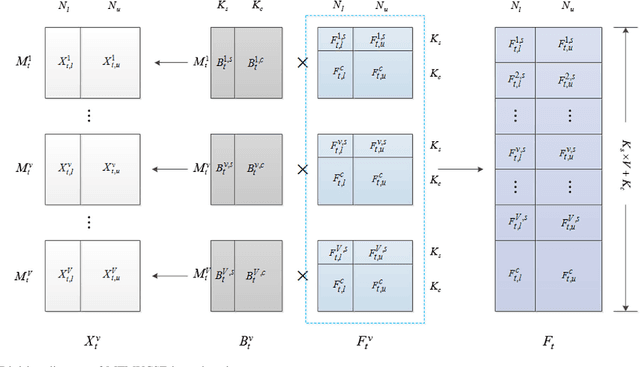
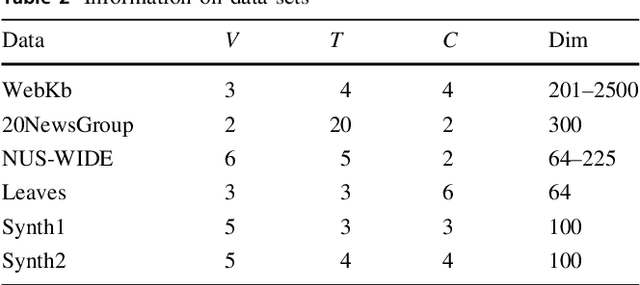
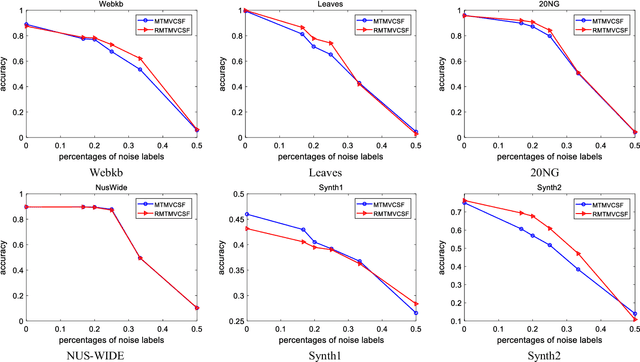
Over recent decades have witnessed considerable progress in whether multi-task learning or multi-view learning, but the situation that consider both learning scenes simultaneously has received not too much attention. How to utilize multiple views latent representation of each single task to improve each learning task performance is a challenge problem. Based on this, we proposed a novel semi-supervised algorithm, termed as Multi-Task Multi-View learning based on Common and Special Features (MTMVCSF). In general, multi-views are the different aspects of an object and every view includes the underlying common or special information of this object. As a consequence, we will mine multiple views jointly latent factor of each learning task which consists of each view special feature and the common feature of all views. By this way, the original multi-task multi-view data has degenerated into multi-task data, and exploring the correlations among multiple tasks enables to make an improvement on the performance of learning algorithm. Another obvious advantage of this approach is that we get latent representation of the set of unlabeled instances by the constraint of regression task with labeled instances. The performance of classification and semi-supervised clustering task in these latent representations perform obviously better than it in raw data. Furthermore, an anti-noise multi-task multi-view algorithm called AN-MTMVCSF is proposed, which has a strong adaptability to noise labels. The effectiveness of these algorithms is proved by a series of well-designed experiments on both real world and synthetic data.
* 32 pages