 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Encoder based Co-Training Multi-View Representation Learning
Jan 09, 2022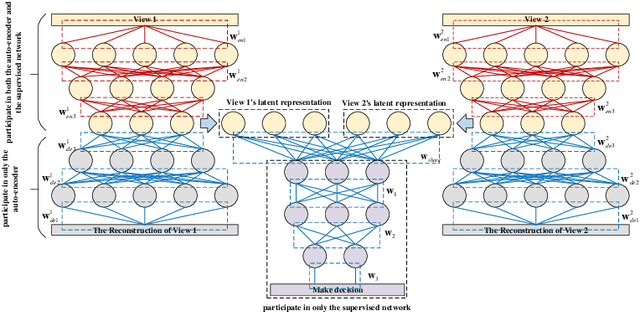

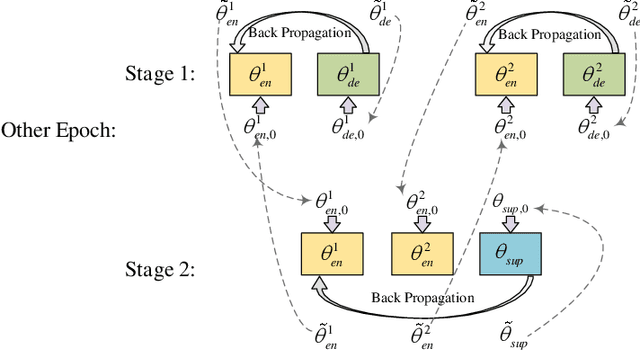
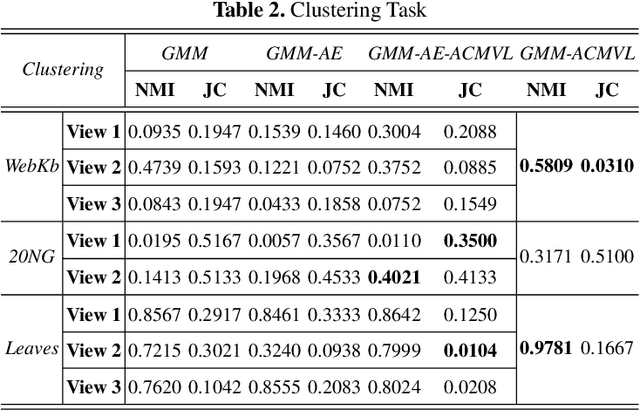
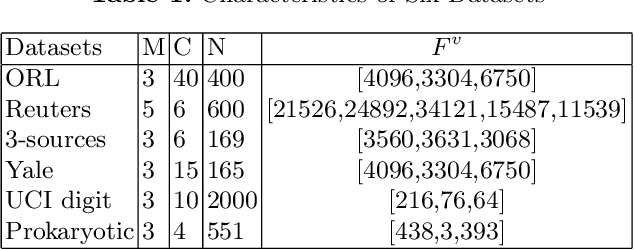
Multi-view learning is a learning problem that utilizes the various representations of an object to mine valuable knowledge and improve the performance of learning algorithm, and one of the significant directions of multi-view learning is sub-space learning. As we known, auto-encoder is a method of deep learning, which can learn the latent feature of raw data by reconstructing the input, and based on this, we propose a novel algorithm called Auto-encoder based Co-training Multi-View Learning (ACMVL), which utilizes both complementarity and consistency and finds a joint latent feature representation of multiple views. The algorithm has two stages, the first is to train auto-encoder of each view, and the second stage is to train a supervised network. Interestingly, the two stages share the weights partly and assist each other by co-training process. According to the experimental result, we can learn a well performed latent feature representation, and auto-encoder of each view has more powerful reconstruction ability than traditional auto-encoder.
Multi-view Subspace Adaptive Learning via Autoencoder and Attention
Jan 01, 2022

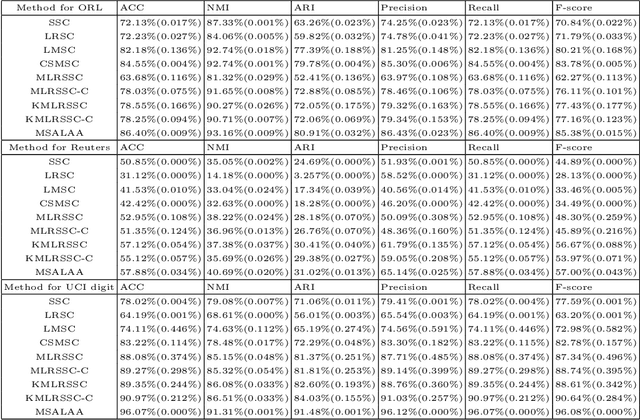
Multi-view learning can cover all features of data samples more comprehensively, so multi-view learning has attracted widespread attention. Traditional subspace clustering methods, such as sparse subspace clustering (SSC) and low-ranking subspace clustering (LRSC), cluster the affinity matrix for a single view, thus ignoring the problem of fusion between views. In our article, we propose a new Multiview Subspace Adaptive Learning based on Attention and Autoencoder (MSALAA). This method combines a deep autoencoder and a method for aligning the self-representations of various views in Multi-view Low-Rank Sparse Subspace Clustering (MLRSSC), which can not only increase the capability to non-linearity fitting, but also can meets the principles of consistency and complementarity of multi-view learning. We empirically observe significant improvement over existing baseline methods on six real-life datasets.