 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACTS: Fine-Grained Action Classification for Tactical Sports
Dec 21, 2024Classifying fine-grained actions in fast-paced, close-combat sports such as fencing and boxing presents unique challenges due to the complexity, speed, and nuance of movements. Traditional methods reliant on pose estimation or fancy sensor data often struggle to capture these dynamics accurately. We introduce FACTS, a novel transformer-based approach for fine-grained action recognition that processes raw video data directly, eliminating the need for pose estimation and the use of cumbersome body markers and sensors. FACTS achieves state-of-the-art performance, with 90% accuracy on fencing actions and 83.25% on boxing actions. Additionally, we present a new publicly available dataset featuring 8 detailed fencing actions, addressing critical gaps in sports analytics resources. Our findings enhance training, performance analysis, and spectator engagement, setting a new benchmark for action classification in tactical sports.
SPORTU: A Comprehensive Sports Understanding Benchmark for Multimodal Large Language Models
Oct 11, 2024



Multimodal Large Language Models (MLLMs) are advancing the ability to reason about complex sports scenarios by integrating textual and visual information. To comprehensively evaluate their capabilities, we introduce SPORTU, a benchmark designed to assess MLLMs across multi-level sports reasoning tasks. SPORTU comprises two key components: SPORTU-text, featuring 900 multiple-choice questions with human-annotated explanations for rule comprehension and strategy understanding. This component focuses on testing models' ability to reason about sports solely through question-answering (QA), without requiring visual inputs; SPORTU-video, consisting of 1,701 slow-motion video clips across 7 different sports and 12,048 QA pairs, designed to assess multi-level reasoning, from simple sports recognition to complex tasks like foul detection and rule application. We evaluate four prevalent LLMs mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting on the SPORTU-text part. We evaluate four LLMs using few-shot learning and chain-of-thought (CoT) prompting on SPORTU-text. GPT-4o achieves the highest accuracy of 71%, but still falls short of human-level performance, highlighting room for improvement in rule comprehension and reasoning. The evaluation for the SPORTU-video part includes 7 proprietary and 6 open-source MLLMs. Experiments show that models fall short on hard tasks that require deep reasoning and rule-based understanding. Claude-3.5-Sonnet performs the best with only 52.6% accuracy on the hard task, showing large room for improvement. We hope that SPORTU will serve as a critical step toward evaluating models' capabilities in sports understanding and reasoning.
Language and Multimodal Models in Sports: A Survey of Datasets and Applications
Jun 18, 2024

Recent integration of Natural Language Processing (NLP) and multimodal models has advanced the field of sports analytics. This survey presents a comprehensive review of the datasets and applications driving these innovations post-2020. We overviewed and categorized datasets into three primary types: language-based, multimodal, and convertible datasets. Language-based and multimodal datasets are for tasks involving text or multimodality (e.g., text, video, audio), respectively. Convertible datasets, initially single-modal (video), can be enriched with additional annotations, such as explanations of actions and video descriptions, to become multimodal, offering future potential for richer and more diverse applications. Our study highlights the contributions of these datasets to various applications, from improving fan experiences to supporting tactical analysis and medical diagnostics. We also discuss the challenges and future directions in dataset development, emphasizing the need for diverse, high-quality data to support real-time processing and personalized user experiences. This survey provides a foundational resource for researchers and practitioners aiming to leverage NLP and multimodal models in sports, offering insights into current trends and future opportunities in the field.
SportQA: A Benchmark for Sports Understanding in Large Language Models
Feb 24, 2024



A deep understanding of sports, a field rich in strategic and dynamic content, is crucial for advancing Natural Language Processing (NLP). This holds particular significance in the context of evaluating and advancing Large Language Models (LLMs), given the existing gap in specialized benchmarks. To bridge this gap, we introduce SportQA, a novel benchmark specifically designed for evaluating LLMs in the context of sports understanding. SportQA encompasses over 70,000 multiple-choice questions across three distinct difficulty levels, each targeting different aspects of sports knowledge from basic historical facts to intricate, scenario-based reasoning tasks. We conducted a thorough evaluation of prevalent LLMs, mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting. Our results reveal that while LLMs exhibit competent performance in basic sports knowledge, they struggle with more complex, scenario-based sports reasoning, lagging behind human expertise. The introduction of SportQA marks a significant step forward in NLP, offering a tool for assessing and enhancing sports understanding in LLMs.
Auto-Encoder based Co-Training Multi-View Representation Learning
Jan 09, 2022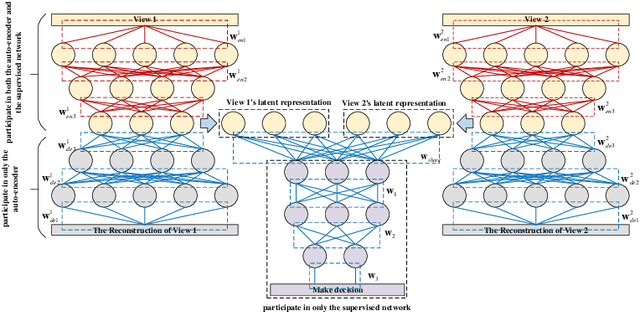

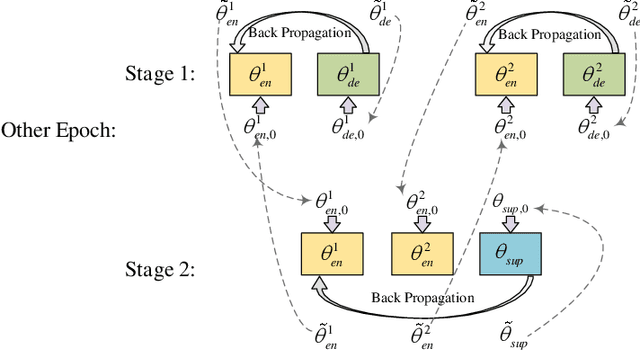
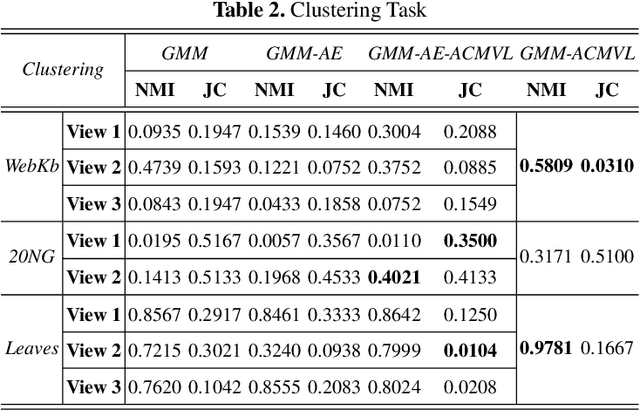
Multi-view learning is a learning problem that utilizes the various representations of an object to mine valuable knowledge and improve the performance of learning algorithm, and one of the significant directions of multi-view learning is sub-space learning. As we known, auto-encoder is a method of deep learning, which can learn the latent feature of raw data by reconstructing the input, and based on this, we propose a novel algorithm called Auto-encoder based Co-training Multi-View Learning (ACMVL), which utilizes both complementarity and consistency and finds a joint latent feature representation of multiple views. The algorithm has two stages, the first is to train auto-encoder of each view, and the second stage is to train a supervised network. Interestingly, the two stages share the weights partly and assist each other by co-training process. According to the experimental result, we can learn a well performed latent feature representation, and auto-encoder of each view has more powerful reconstruction ability than traditional auto-encoder.
Multi-View Non-negative Matrix Factorization Discriminant Learning via Cross Entropy Loss
Jan 08, 2022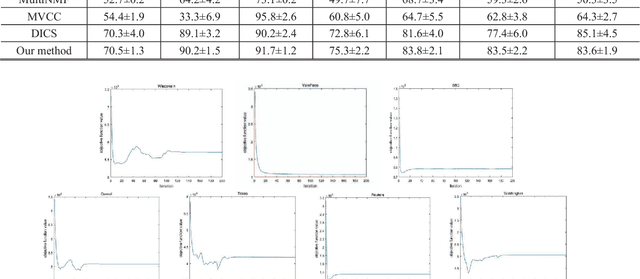
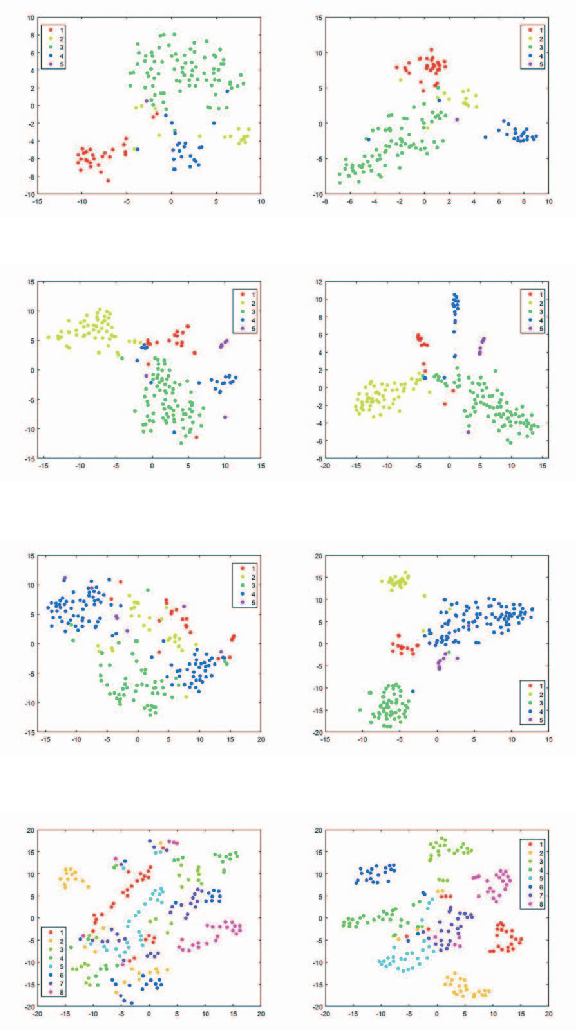
Multi-view learning accomplishes the task objectives of classification by leverag-ing the relationships between different views of the same object. Most existing methods usually focus on consistency and complementarity between multiple views. But not all of this information is useful for classification tasks. Instead, it is the specific discriminating information that plays an important role. Zhong Zhang et al. explore the discriminative and non-discriminative information exist-ing in common and view-specific parts among different views via joint non-negative matrix factorization. In this paper, we improve this algorithm on this ba-sis by using the cross entropy loss function to constrain the objective function better. At last, we implement better classification effect than original on the same data sets and show its superiority over many state-of-the-art algorithms.