 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Regression for Continuous Value Prediction using Residual Quantization
Feb 26, 2026Continuous value prediction plays a crucial role in industrial-scale recommendation systems, including tasks such as predicting users' watch-time and estimating the gross merchandise value (GMV) in e-commerce transactions. However, it remains challenging due to the highly complex and long-tailed nature of the data distributions. Existing generative approaches rely on rigid parametric distribution assumptions, which fundamentally limits their performance when such assumptions misalign with real-world data. Overly simplified forms cannot adequately model real-world complexities, while more intricate assumptions often suffer from poor scalability and generalization. To address these challenges, we propose a residual quantization (RQ)-based sequence learning framework that represents target continuous values as a sum of ordered quantization codes, predicted recursively from coarse to fine granularity with diminishing quantization errors. We introduce a representation learning objective that aligns RQ code embedding space with the ordinal structure of target values, allowing the model to capture continuous representations for quantization codes and further improving prediction accuracy. We perform extensive evaluations on public benchmarks for lifetime value (LTV) and watch-time prediction, alongside a large-scale online experiment for GMV prediction on an industrial short-video recommendation platform. The results consistently show that our approach outperforms state-of-the-art methods, while demonstrating strong generalization across diverse continuous value prediction tasks in recommendation systems.
RecGOAT: Graph Optimal Adaptive Transport for LLM-Enhanced Multimodal Recommendation with Dual Semantic Alignment
Jan 31, 2026Multimodal recommendation systems typically integrates user behavior with multimodal data from items, thereby capturing more accurate user preferences. Concurrently, with the rise of large models (LMs), multimodal recommendation is increasingly leveraging their strengths in semantic understanding and contextual reasoning. However, LM representations are inherently optimized for general semantic tasks, while recommendation models rely heavily on sparse user/item unique identity (ID) features. Existing works overlook the fundamental representational divergence between large models and recommendation systems, resulting in incompatible multimodal representations and suboptimal recommendation performance. To bridge this gap, we propose RecGOAT, a novel yet simple dual semantic alignment framework for LLM-enhanced multimodal recommendation, which offers theoretically guaranteed alignment capability. RecGOAT first employs graph attention networks to enrich collaborative semantics by modeling item-item, user-item, and user-user relationships, leveraging user/item LM representations and interaction history. Furthermore, we design a dual-granularity progressive multimodality-ID alignment framework, which achieves instance-level and distribution-level semantic alignment via cross-modal contrastive learning (CMCL) and optimal adaptive transport (OAT), respectively. Theoretically, we demonstrate that the unified representations derived from our alignment framework exhibit superior semantic consistency and comprehensiveness. Extensive experiments on three public benchmarks show that our RecGOAT achieves state-of-the-art performance, empirically validating our theoretical insights. Additionally, the deployment on a large-scale online advertising platform confirms the model's effectiveness and scalability in industrial recommendation scenarios. Code available at https://github.com/6lyc/RecGOAT-LLM4Rec.
FITMM: Adaptive Frequency-Aware Multimodal Recommendation via Information-Theoretic Representation Learning
Jan 30, 2026Multimodal recommendation aims to enhance user preference modeling by leveraging rich item content such as images and text. Yet dominant systems fuse modalities in the spatial domain, obscuring the frequency structure of signals and amplifying misalignment and redundancy. We adopt a spectral information-theoretic view and show that, under an orthogonal transform that approximately block-diagonalizes bandwise covariances, the Gaussian Information Bottleneck objective decouples across frequency bands, providing a principled basis for separate-then-fuse paradigm. Building on this foundation, we propose FITMM, a Frequency-aware Information-Theoretic framework for multimodal recommendation. FITMM constructs graph-enhanced item representations, performs modality-wise spectral decomposition to obtain orthogonal bands, and forms lightweight within-band multimodal components. A residual, task-adaptive gate aggregates bands into the final representation. To control redundancy and improve generalization, we regularize training with a frequency-domain IB term that allocates capacity across bands (Wiener-like shrinkage with shut-off of weak bands). We further introduce a cross-modal spectral consistency loss that aligns modalities within each band. The model is jointly optimized with the standard recommendation loss. Extensive experiments on three real-world datasets demonstrate that FITMM consistently and significantly outperforms advanced baselines.
R4ec: A Reasoning, Reflection, and Refinement Framework for Recommendation Systems
Jul 23, 2025Harnessing Large Language Models (LLMs) for recommendation systems has emerged as a prominent avenue, drawing substantial research interest. However, existing approaches primarily involve basic prompt techniques for knowledge acquisition, which resemble System-1 thinking. This makes these methods highly sensitive to errors in the reasoning path, where even a small mistake can lead to an incorrect inference. To this end, in this paper, we propose $R^{4}$ec, a reasoning, reflection and refinement framework that evolves the recommendation system into a weak System-2 model. Specifically, we introduce two models: an actor model that engages in reasoning, and a reflection model that judges these responses and provides valuable feedback. Then the actor model will refine its response based on the feedback, ultimately leading to improved responses. We employ an iterative reflection and refinement process, enabling LLMs to facilitate slow and deliberate System-2-like thinking. Ultimately, the final refined knowledge will be incorporated into a recommendation backbone for prediction. We conduct extensive experiments on Amazon-Book and MovieLens-1M datasets to demonstrate the superiority of $R^{4}$ec. We also deploy $R^{4}$ec on a large scale online advertising platform, showing 2.2\% increase of revenue. Furthermore, we investigate the scaling properties of the actor model and reflection model.
Attention-Enhanced Prompt Decision Transformers for UAV-Assisted Communications with AoI
May 28, 2025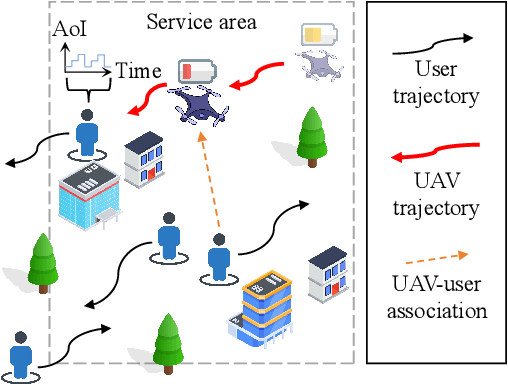
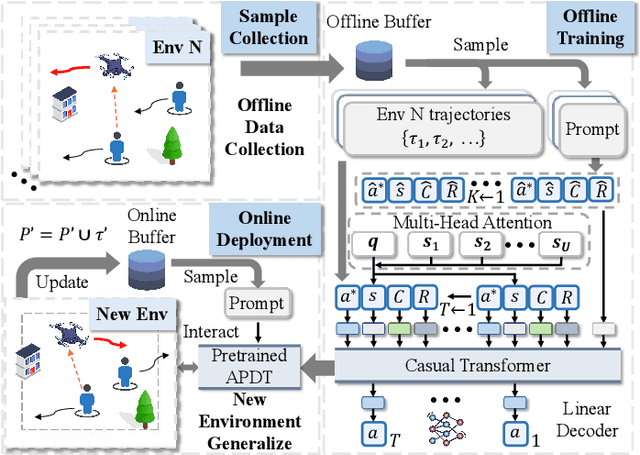
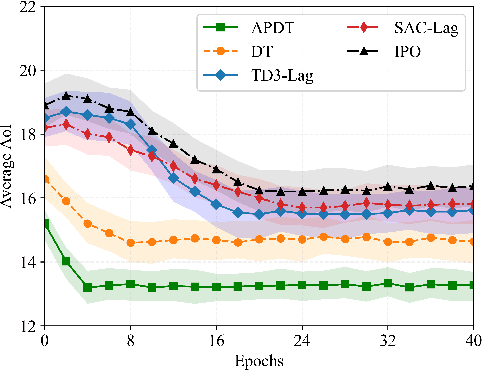
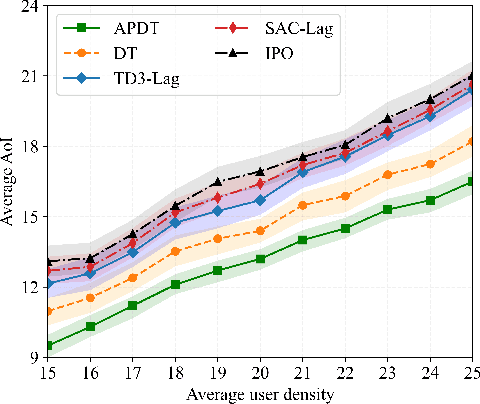
Decision Transformer (DT) has recently demonstrated strong generalizability in dynamic resource allocation within unmanned aerial vehicle (UAV) networks, compared to conventional deep reinforcement learning (DRL). However, its performance is hindered due to zero-padding for varying state dimensions, inability to manage long-term energy constraint, and challenges in acquiring expert samples for few-shot fine-tuning in new scenarios. To overcome these limitations, we propose an attention-enhanced prompt Decision Transformer (APDT) framework to optimize trajectory planning and user scheduling, aiming to minimize the average age of information (AoI) under long-term energy constraint in UAV-assisted Internet of Things (IoT) networks. Specifically, we enhance the convenional DT framework by incorporating an attention mechanism to accommodate varying numbers of terrestrial users, introducing a prompt mechanism based on short trajectory demonstrations for rapid adaptation to new scenarios, and designing a token-assisted method to address the UAV's long-term energy constraint. The APDT framework is first pre-trained on offline datasets and then efficiently generalized to new scenarios. Simulations demonstrate that APDT achieves twice faster in terms of convergence rate and reduces average AoI by $8\%$ compared to conventional DT.
Hierarchical Tree Search-based User Lifelong Behavior Modeling on Large Language Model
May 26, 2025Large Language Models (LLMs) have garnered significant attention in Recommendation Systems (RS) due to their extensive world knowledge and robust reasoning capabilities. However, a critical challenge lies in enabling LLMs to effectively comprehend and extract insights from massive user behaviors. Current approaches that directly leverage LLMs for user interest learning face limitations in handling long sequential behaviors, effectively extracting interest, and applying interest in practical scenarios. To address these issues, we propose a Hierarchical Tree Search-based User Lifelong Behavior Modeling framework (HiT-LBM). HiT-LBM integrates Chunked User Behavior Extraction (CUBE) and Hierarchical Tree Search for Interest (HTS) to capture diverse interests and interest evolution of user. CUBE divides user lifelong behaviors into multiple chunks and learns the interest and interest evolution within each chunk in a cascading manner. HTS generates candidate interests through hierarchical expansion and searches for the optimal interest with process rating model to ensure information gain for each behavior chunk. Additionally, we design Temporal-Ware Interest Fusion (TIF) to integrate interests from multiple behavior chunks, constructing a comprehensive representation of user lifelong interests. The representation can be embedded into any recommendation model to enhance performance. Extensive experiments demonstrate the effectiveness of our approach, showing that it surpasses state-of-the-art methods.
Navigate the Unknown: Enhancing LLM Reasoning with Intrinsic Motivation Guided Exploration
May 23, 2025Reinforcement learning (RL) has emerged as a pivotal method for improving the reasoning capabilities of Large Language Models (LLMs). However, prevalent RL approaches such as Proximal Policy Optimization (PPO) and Group-Regularized Policy Optimization (GRPO) face critical limitations due to their reliance on sparse outcome-based rewards and inadequate mechanisms for incentivizing exploration. These limitations result in inefficient guidance for multi-step reasoning processes. Specifically, sparse reward signals fail to deliver effective or sufficient feedback, particularly for challenging problems. Furthermore, such reward structures induce systematic biases that prioritize exploitation of familiar trajectories over novel solution discovery. These shortcomings critically hinder performance in complex reasoning tasks, which inherently demand iterative refinement across ipntermediate steps. To address these challenges, we propose an Intrinsic Motivation guidEd exploratioN meThOd foR LLM Reasoning (i-MENTOR), a novel method designed to both deliver dense rewards and amplify explorations in the RL-based training paradigm. i-MENTOR introduces three key innovations: trajectory-aware exploration rewards that mitigate bias in token-level strategies while maintaining computational efficiency; dynamic reward scaling to stabilize exploration and exploitation in large action spaces; and advantage-preserving reward implementation that maintains advantage distribution integrity while incorporating exploratory guidance. Experiments across three public datasets demonstrate i-MENTOR's effectiveness with a 22.39% improvement on the difficult dataset Countdown-4.
SPORTU: A Comprehensive Sports Understanding Benchmark for Multimodal Large Language Models
Oct 11, 2024



Multimodal Large Language Models (MLLMs) are advancing the ability to reason about complex sports scenarios by integrating textual and visual information. To comprehensively evaluate their capabilities, we introduce SPORTU, a benchmark designed to assess MLLMs across multi-level sports reasoning tasks. SPORTU comprises two key components: SPORTU-text, featuring 900 multiple-choice questions with human-annotated explanations for rule comprehension and strategy understanding. This component focuses on testing models' ability to reason about sports solely through question-answering (QA), without requiring visual inputs; SPORTU-video, consisting of 1,701 slow-motion video clips across 7 different sports and 12,048 QA pairs, designed to assess multi-level reasoning, from simple sports recognition to complex tasks like foul detection and rule application. We evaluate four prevalent LLMs mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting on the SPORTU-text part. We evaluate four LLMs using few-shot learning and chain-of-thought (CoT) prompting on SPORTU-text. GPT-4o achieves the highest accuracy of 71%, but still falls short of human-level performance, highlighting room for improvement in rule comprehension and reasoning. The evaluation for the SPORTU-video part includes 7 proprietary and 6 open-source MLLMs. Experiments show that models fall short on hard tasks that require deep reasoning and rule-based understanding. Claude-3.5-Sonnet performs the best with only 52.6% accuracy on the hard task, showing large room for improvement. We hope that SPORTU will serve as a critical step toward evaluating models' capabilities in sports understanding and reasoning.
Supervised Deep Hashing for Hierarchical Labeled Data
Sep 12, 2017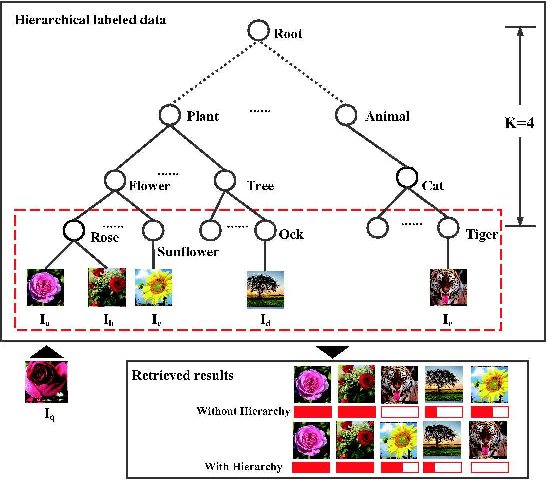
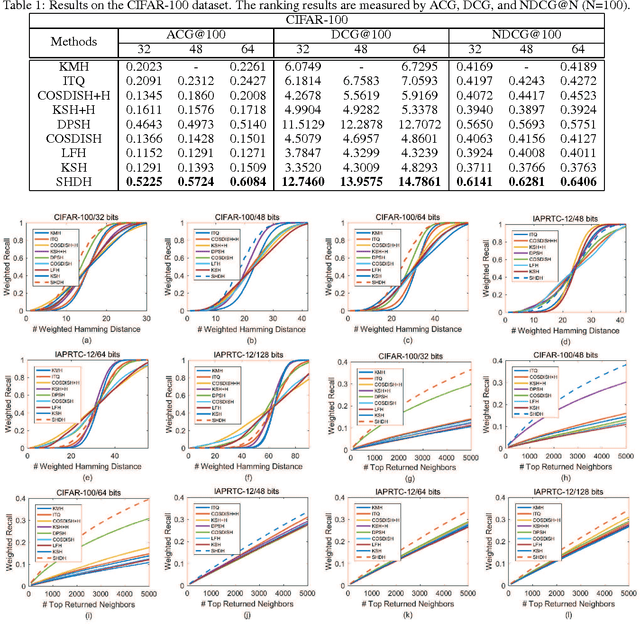
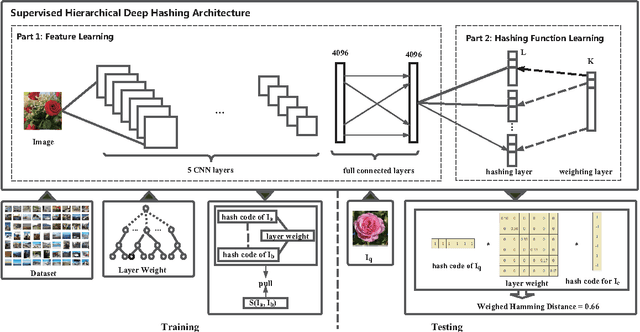
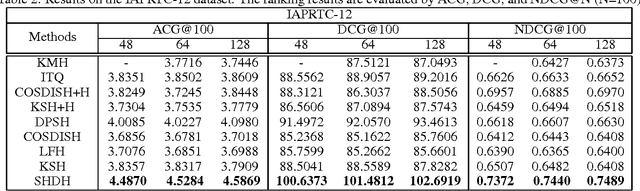
Recently, hashing methods have been widely used in large-scale image retrieval. However, most existing hashing methods did not consider the hierarchical relation of labels, which means that they ignored the rich information stored in the hierarchy. Moreover, most of previous works treat each bit in a hash code equally, which does not meet the scenario of hierarchical labeled data. In this paper, we propose a novel deep hashing method, called supervised hierarchical deep hashing (SHDH), to perform hash code learning for hierarchical labeled data. Specifically, we define a novel similarity formula for hierarchical labeled data by weighting each layer, and design a deep convolutional neural network to obtain a hash code for each data point. Extensive experiments on several real-world public datasets show that the proposed method outperforms the state-of-the-art baselines in the image retrieval task.