 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Dignity-Aware AI: Next-Generation Elderly Monitoring from Fall Detection to ADL
Nov 12, 2025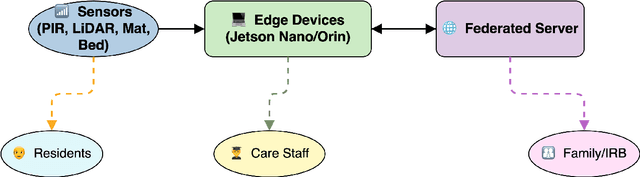



This position paper envisions a next-generation elderly monitoring system that moves beyond fall detection toward the broader goal of Activities of Daily Living (ADL) recognition. Our ultimate aim is to design privacy-preserving, edge-deployed, and federated AI systems that can robustly detect and understand daily routines, supporting independence and dignity in aging societies. At present, ADL-specific datasets are still under collection. As a preliminary step, we demonstrate feasibility through experiments using the SISFall dataset and its GAN-augmented variants, treating fall detection as a proxy task. We report initial results on federated learning with non-IID conditions, and embedded deployment on Jetson Orin Nano devices. We then outline open challenges such as domain shift, data scarcity, and privacy risks, and propose directions toward full ADL monitoring in smart-room environments. This work highlights the transition from single-task detection to comprehensive daily activity recognition, providing both early evidence and a roadmap for sustainable and human-centered elderly care AI.
SPORTU: A Comprehensive Sports Understanding Benchmark for Multimodal Large Language Models
Oct 11, 2024



Multimodal Large Language Models (MLLMs) are advancing the ability to reason about complex sports scenarios by integrating textual and visual information. To comprehensively evaluate their capabilities, we introduce SPORTU, a benchmark designed to assess MLLMs across multi-level sports reasoning tasks. SPORTU comprises two key components: SPORTU-text, featuring 900 multiple-choice questions with human-annotated explanations for rule comprehension and strategy understanding. This component focuses on testing models' ability to reason about sports solely through question-answering (QA), without requiring visual inputs; SPORTU-video, consisting of 1,701 slow-motion video clips across 7 different sports and 12,048 QA pairs, designed to assess multi-level reasoning, from simple sports recognition to complex tasks like foul detection and rule application. We evaluate four prevalent LLMs mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting on the SPORTU-text part. We evaluate four LLMs using few-shot learning and chain-of-thought (CoT) prompting on SPORTU-text. GPT-4o achieves the highest accuracy of 71%, but still falls short of human-level performance, highlighting room for improvement in rule comprehension and reasoning. The evaluation for the SPORTU-video part includes 7 proprietary and 6 open-source MLLMs. Experiments show that models fall short on hard tasks that require deep reasoning and rule-based understanding. Claude-3.5-Sonnet performs the best with only 52.6% accuracy on the hard task, showing large room for improvement. We hope that SPORTU will serve as a critical step toward evaluating models' capabilities in sports understanding and reasoning.