 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSportR: A Benchmark for Multimodal Large Language Model Reasoning in Sports
Nov 17, 2025Deeply understanding sports requires an intricate blend of fine-grained visual perception and rule-based reasoning - a challenge that pushes the limits of current multimodal models. To succeed, models must master three critical capabilities: perceiving nuanced visual details, applying abstract sport rule knowledge, and grounding that knowledge in specific visual evidence. Current sports benchmarks either cover single sports or lack the detailed reasoning chains and precise visual grounding needed to robustly evaluate these core capabilities in a multi-sport context. To address this gap, we introduce SportR, the first multi-sports large-scale benchmark designed to train and evaluate MLLMs on the fundamental reasoning required for sports intelligence. Our benchmark provides a dataset of 5,017 images and 2,101 videos. To enable granular evaluation, we structure our benchmark around a progressive hierarchy of question-answer (QA) pairs designed to probe reasoning at increasing depths - from simple infraction identification to complex penalty prediction. For the most advanced tasks requiring multi-step reasoning, such as determining penalties or explaining tactics, we provide 7,118 high-quality, human-authored Chain of Thought (CoT) annotations. In addition, our benchmark incorporates both image and video modalities and provides manual bounding box annotations to test visual grounding in the image part directly. Extensive experiments demonstrate the profound difficulty of our benchmark. State-of-the-art baseline models perform poorly on our most challenging tasks. While training on our data via Supervised Fine-Tuning and Reinforcement Learning improves these scores, they remain relatively low, highlighting a significant gap in current model capabilities. SportR presents a new challenge for the community, providing a critical resource to drive future research in multimodal sports reasoning.
DeepSport: A Multimodal Large Language Model for Comprehensive Sports Video Reasoning via Agentic Reinforcement Learning
Nov 17, 2025Sports video understanding presents unique challenges, requiring models to perceive high-speed dynamics, comprehend complex rules, and reason over long temporal contexts. While Multimodal Large Language Models (MLLMs) have shown promise in genral domains, the current state of research in sports remains narrowly focused: existing approaches are either single-sport centric, limited to specific tasks, or rely on training-free paradigms that lack robust, learned reasoning process. To address this gap, we introduce DeepSport, the first end-to-end trained MLLM framework designed for multi-task, multi-sport video understanding. DeepSport shifts the paradigm from passive frame processing to active, iterative reasoning, empowering the model to ``think with videos'' by dynamically interrogating content via a specialized frame-extraction tool. To enable this, we propose a data distillation pipeline that synthesizes high-quality Chain-of-Thought (CoT) trajectories from 10 diverse data source, creating a unified resource of 78k training data. We then employ a two-stage training strategy, Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) with a novel gated tool-use reward, to optimize the model's reasoning process. Extensive experiments on the testing benchmark of 6.7k questions demonstrate that DeepSport achieves state-of-the-art performance, significantly outperforming baselines of both proprietary model and open-source models. Our work establishes a new foundation for domain-specific video reasoning to address the complexities of diverse sports.
FACTS: Fine-Grained Action Classification for Tactical Sports
Dec 21, 2024Classifying fine-grained actions in fast-paced, close-combat sports such as fencing and boxing presents unique challenges due to the complexity, speed, and nuance of movements. Traditional methods reliant on pose estimation or fancy sensor data often struggle to capture these dynamics accurately. We introduce FACTS, a novel transformer-based approach for fine-grained action recognition that processes raw video data directly, eliminating the need for pose estimation and the use of cumbersome body markers and sensors. FACTS achieves state-of-the-art performance, with 90% accuracy on fencing actions and 83.25% on boxing actions. Additionally, we present a new publicly available dataset featuring 8 detailed fencing actions, addressing critical gaps in sports analytics resources. Our findings enhance training, performance analysis, and spectator engagement, setting a new benchmark for action classification in tactical sports.
SPORTU: A Comprehensive Sports Understanding Benchmark for Multimodal Large Language Models
Oct 11, 2024



Multimodal Large Language Models (MLLMs) are advancing the ability to reason about complex sports scenarios by integrating textual and visual information. To comprehensively evaluate their capabilities, we introduce SPORTU, a benchmark designed to assess MLLMs across multi-level sports reasoning tasks. SPORTU comprises two key components: SPORTU-text, featuring 900 multiple-choice questions with human-annotated explanations for rule comprehension and strategy understanding. This component focuses on testing models' ability to reason about sports solely through question-answering (QA), without requiring visual inputs; SPORTU-video, consisting of 1,701 slow-motion video clips across 7 different sports and 12,048 QA pairs, designed to assess multi-level reasoning, from simple sports recognition to complex tasks like foul detection and rule application. We evaluate four prevalent LLMs mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting on the SPORTU-text part. We evaluate four LLMs using few-shot learning and chain-of-thought (CoT) prompting on SPORTU-text. GPT-4o achieves the highest accuracy of 71%, but still falls short of human-level performance, highlighting room for improvement in rule comprehension and reasoning. The evaluation for the SPORTU-video part includes 7 proprietary and 6 open-source MLLMs. Experiments show that models fall short on hard tasks that require deep reasoning and rule-based understanding. Claude-3.5-Sonnet performs the best with only 52.6% accuracy on the hard task, showing large room for improvement. We hope that SPORTU will serve as a critical step toward evaluating models' capabilities in sports understanding and reasoning.
Sports Intelligence: Assessing the Sports Understanding Capabilities of Language Models through Question Answering from Text to Video
Jun 21, 2024Understanding sports is crucial for the advancement of Natural Language Processing (NLP) due to its intricate and dynamic nature. Reasoning over complex sports scenarios has posed significant challenges to current NLP technologies which require advanced cognitive capabilities. Toward addressing the limitations of existing benchmarks on sports understanding in the NLP field, we extensively evaluated mainstream large language models for various sports tasks. Our evaluation spans from simple queries on basic rules and historical facts to complex, context-specific reasoning, leveraging strategies from zero-shot to few-shot learning, and chain-of-thought techniques. In addition to unimodal analysis, we further assessed the sports reasoning capabilities of mainstream video language models to bridge the gap in multimodal sports understanding benchmarking. Our findings highlighted the critical challenges of sports understanding for NLP. We proposed a new benchmark based on a comprehensive overview of existing sports datasets and provided extensive error analysis which we hope can help identify future research priorities in this field.
Language and Multimodal Models in Sports: A Survey of Datasets and Applications
Jun 18, 2024

Recent integration of Natural Language Processing (NLP) and multimodal models has advanced the field of sports analytics. This survey presents a comprehensive review of the datasets and applications driving these innovations post-2020. We overviewed and categorized datasets into three primary types: language-based, multimodal, and convertible datasets. Language-based and multimodal datasets are for tasks involving text or multimodality (e.g., text, video, audio), respectively. Convertible datasets, initially single-modal (video), can be enriched with additional annotations, such as explanations of actions and video descriptions, to become multimodal, offering future potential for richer and more diverse applications. Our study highlights the contributions of these datasets to various applications, from improving fan experiences to supporting tactical analysis and medical diagnostics. We also discuss the challenges and future directions in dataset development, emphasizing the need for diverse, high-quality data to support real-time processing and personalized user experiences. This survey provides a foundational resource for researchers and practitioners aiming to leverage NLP and multimodal models in sports, offering insights into current trends and future opportunities in the field.
SportQA: A Benchmark for Sports Understanding in Large Language Models
Feb 24, 2024



A deep understanding of sports, a field rich in strategic and dynamic content, is crucial for advancing Natural Language Processing (NLP). This holds particular significance in the context of evaluating and advancing Large Language Models (LLMs), given the existing gap in specialized benchmarks. To bridge this gap, we introduce SportQA, a novel benchmark specifically designed for evaluating LLMs in the context of sports understanding. SportQA encompasses over 70,000 multiple-choice questions across three distinct difficulty levels, each targeting different aspects of sports knowledge from basic historical facts to intricate, scenario-based reasoning tasks. We conducted a thorough evaluation of prevalent LLMs, mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting. Our results reveal that while LLMs exhibit competent performance in basic sports knowledge, they struggle with more complex, scenario-based sports reasoning, lagging behind human expertise. The introduction of SportQA marks a significant step forward in NLP, offering a tool for assessing and enhancing sports understanding in LLMs.
Advanced Volleyball Stats for All Levels: Automatic Setting Tactic Detection and Classification with a Single Camera
Sep 26, 2023This paper presents PathFinder and PathFinderPlus, two novel end-to-end computer vision frameworks designed specifically for advanced setting strategy classification in volleyball matches from a single camera view. Our frameworks combine setting ball trajectory recognition with a novel set trajectory classifier to generate comprehensive and advanced statistical data. This approach offers a fresh perspective for in-game analysis and surpasses the current level of granularity in volleyball statistics. In comparison to existing methods used in our baseline PathFinder framework, our proposed ball trajectory detection methodology in PathFinderPlus exhibits superior performance for classifying setting tactics under various game conditions. This robustness is particularly advantageous in handling complex game situations and accommodating different camera angles. Additionally, our study introduces an innovative algorithm for automatic identification of the opposing team's right-side (opposite) hitter's current row (front or back) during gameplay, providing critical insights for tactical analysis. The successful demonstration of our single-camera system's feasibility and benefits makes high-level technical analysis accessible to volleyball enthusiasts of all skill levels and resource availability. Furthermore, the computational efficiency of our system allows for real-time deployment, enabling in-game strategy analysis and on-the-spot gameplan adjustments.
Graph Encoding and Neural Network Approaches for Volleyball Analytics: From Game Outcome to Individual Play Predictions
Aug 22, 2023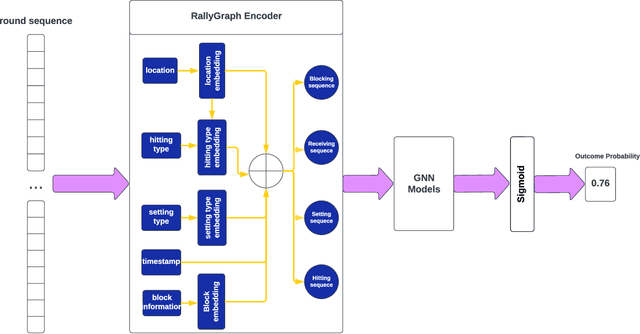
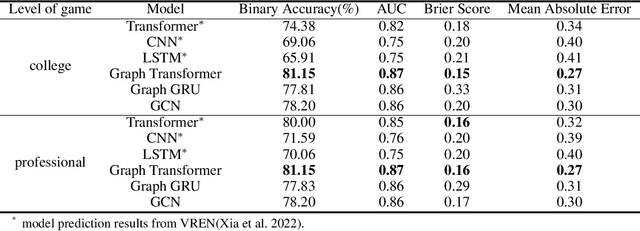

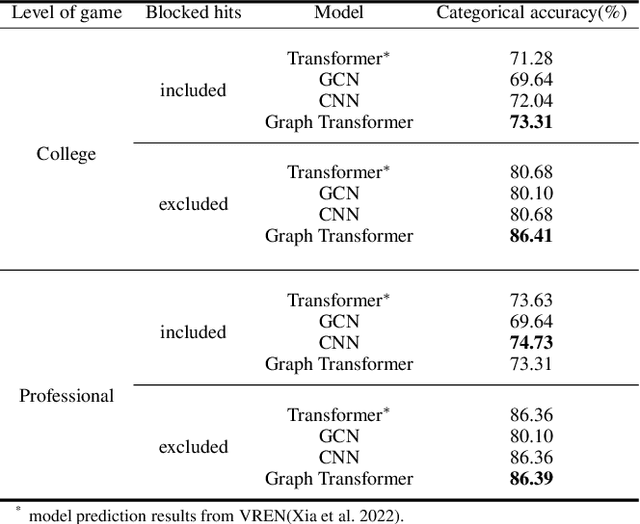
This research aims to improve the accuracy of complex volleyball predictions and provide more meaningful insights to coaches and players. We introduce a specialized graph encoding technique to add additional contact-by-contact volleyball context to an already available volleyball dataset without any additional data gathering. We demonstrate the potential benefits of using graph neural networks (GNNs) on this enriched dataset for three different volleyball prediction tasks: rally outcome prediction, set location prediction, and hit type prediction. We compare the performance of our graph-based models to baseline models and analyze the results to better understand the underlying relationships in a volleyball rally. Our results show that the use of GNNs with our graph encoding yields a much more advanced analysis of the data, which noticeably improves prediction results overall. We also show that these baseline tasks can be significantly improved with simple adjustments, such as removing blocked hits. Lastly, we demonstrate the importance of choosing a model architecture that will better extract the important information for a certain task. Overall, our study showcases the potential strengths and weaknesses of using graph encodings in sports data analytics and hopefully will inspire future improvements in machine learning strategies across sports and applications by using graphbased encodings.
VREN: Volleyball Rally Dataset with Expression Notation Language
Sep 28, 2022


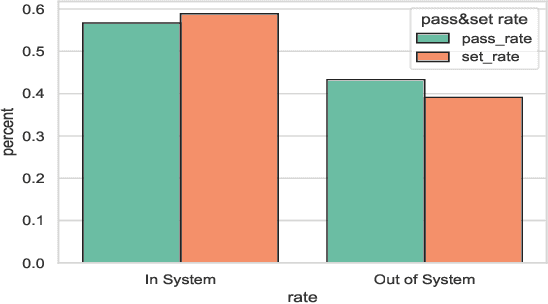
This research is intended to accomplish two goals: The first goal is to curate a large and information rich dataset that contains crucial and succinct summaries on the players' actions and positions and the back-and-forth travel patterns of the volleyball in professional and NCAA Div-I indoor volleyball games. While several prior studies have aimed to create similar datasets for other sports (e.g. badminton and soccer), creating such a dataset for indoor volleyball is not yet realized. The second goal is to introduce a volleyball descriptive language to fully describe the rally processes in the games and apply the language to our dataset. Based on the curated dataset and our descriptive sports language, we introduce three tasks for automated volleyball action and tactic analysis using our dataset: (1) Volleyball Rally Prediction, aimed at predicting the outcome of a rally and helping players and coaches improve decision-making in practice, (2) Setting Type and Hitting Type Prediction, to help coaches and players prepare more effectively for the game, and (3) Volleyball Tactics and Attacking Zone Statistics, to provide advanced volleyball statistics and help coaches understand the game and opponent's tactics better. We conducted case studies to show how experimental results can provide insights to the volleyball analysis community. Furthermore, experimental evaluation based on real-world data establishes a baseline for future studies and applications of our dataset and language. This study bridges the gap between the indoor volleyball field and computer science.