 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Volleyball Stats for All Levels: Automatic Setting Tactic Detection and Classification with a Single Camera
Sep 26, 2023This paper presents PathFinder and PathFinderPlus, two novel end-to-end computer vision frameworks designed specifically for advanced setting strategy classification in volleyball matches from a single camera view. Our frameworks combine setting ball trajectory recognition with a novel set trajectory classifier to generate comprehensive and advanced statistical data. This approach offers a fresh perspective for in-game analysis and surpasses the current level of granularity in volleyball statistics. In comparison to existing methods used in our baseline PathFinder framework, our proposed ball trajectory detection methodology in PathFinderPlus exhibits superior performance for classifying setting tactics under various game conditions. This robustness is particularly advantageous in handling complex game situations and accommodating different camera angles. Additionally, our study introduces an innovative algorithm for automatic identification of the opposing team's right-side (opposite) hitter's current row (front or back) during gameplay, providing critical insights for tactical analysis. The successful demonstration of our single-camera system's feasibility and benefits makes high-level technical analysis accessible to volleyball enthusiasts of all skill levels and resource availability. Furthermore, the computational efficiency of our system allows for real-time deployment, enabling in-game strategy analysis and on-the-spot gameplan adjustments.
Graph Encoding and Neural Network Approaches for Volleyball Analytics: From Game Outcome to Individual Play Predictions
Aug 22, 2023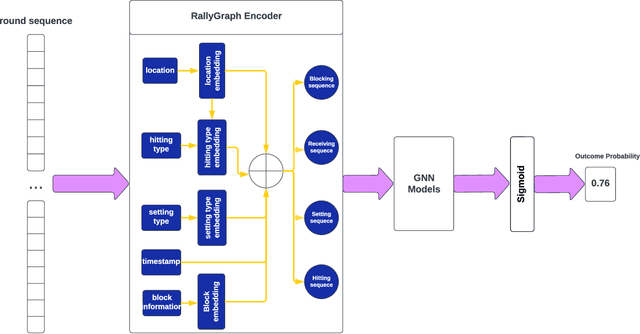
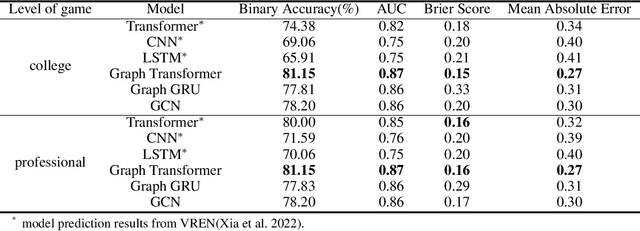

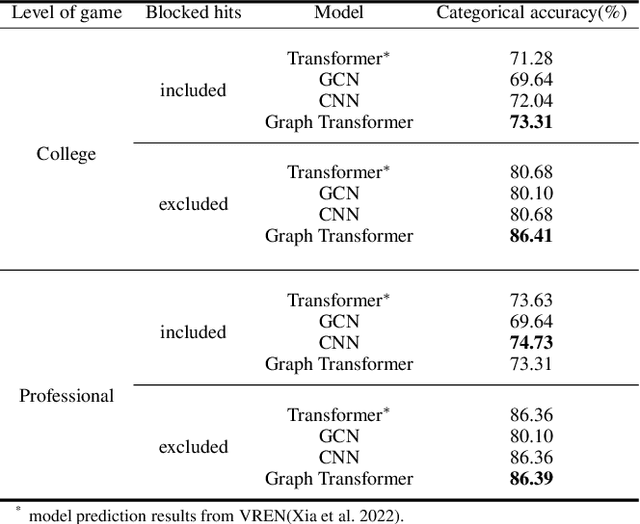
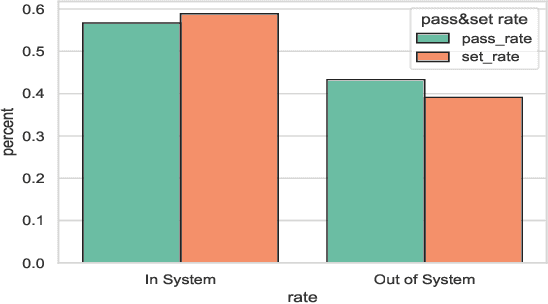
This research aims to improve the accuracy of complex volleyball predictions and provide more meaningful insights to coaches and players. We introduce a specialized graph encoding technique to add additional contact-by-contact volleyball context to an already available volleyball dataset without any additional data gathering. We demonstrate the potential benefits of using graph neural networks (GNNs) on this enriched dataset for three different volleyball prediction tasks: rally outcome prediction, set location prediction, and hit type prediction. We compare the performance of our graph-based models to baseline models and analyze the results to better understand the underlying relationships in a volleyball rally. Our results show that the use of GNNs with our graph encoding yields a much more advanced analysis of the data, which noticeably improves prediction results overall. We also show that these baseline tasks can be significantly improved with simple adjustments, such as removing blocked hits. Lastly, we demonstrate the importance of choosing a model architecture that will better extract the important information for a certain task. Overall, our study showcases the potential strengths and weaknesses of using graph encodings in sports data analytics and hopefully will inspire future improvements in machine learning strategies across sports and applications by using graphbased encodings.
VREN: Volleyball Rally Dataset with Expression Notation Language
Sep 28, 2022


This research is intended to accomplish two goals: The first goal is to curate a large and information rich dataset that contains crucial and succinct summaries on the players' actions and positions and the back-and-forth travel patterns of the volleyball in professional and NCAA Div-I indoor volleyball games. While several prior studies have aimed to create similar datasets for other sports (e.g. badminton and soccer), creating such a dataset for indoor volleyball is not yet realized. The second goal is to introduce a volleyball descriptive language to fully describe the rally processes in the games and apply the language to our dataset. Based on the curated dataset and our descriptive sports language, we introduce three tasks for automated volleyball action and tactic analysis using our dataset: (1) Volleyball Rally Prediction, aimed at predicting the outcome of a rally and helping players and coaches improve decision-making in practice, (2) Setting Type and Hitting Type Prediction, to help coaches and players prepare more effectively for the game, and (3) Volleyball Tactics and Attacking Zone Statistics, to provide advanced volleyball statistics and help coaches understand the game and opponent's tactics better. We conducted case studies to show how experimental results can provide insights to the volleyball analysis community. Furthermore, experimental evaluation based on real-world data establishes a baseline for future studies and applications of our dataset and language. This study bridges the gap between the indoor volleyball field and computer science.
VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research
Apr 06, 2019



We present a new large-scale multilingual video description dataset, VATEX, which contains over 41,250 videos and 825,000 captions in both English and Chinese. Among the captions, there are over 206,000 English-Chinese parallel translation pairs. Compared to the widely-used MSR-VTT dataset, VATEX is multilingual, larger, linguistically complex, and more diverse in terms of both video and natural language descriptions. We also introduce two tasks for video-and-language research based on VATEX: (1) Multilingual Video Captioning, aimed at describing a video in various languages with a compact unified captioning model, and (2) Video-guided Machine Translation, to translate a source language description into the target language using the video information as additional spatiotemporal context. Extensive experiments on the VATEX dataset show that, first, the unified multilingual model can not only produce both English and Chinese descriptions for a video more efficiently, but also offer improved performance over the monolingual models. Furthermore, we demonstrate that the spatiotemporal video context can be effectively utilized to align source and target languages and thus assist machine translation. In the end, we discuss the potentials of using VATEX for other video-and-language research.
Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation
Apr 06, 2019
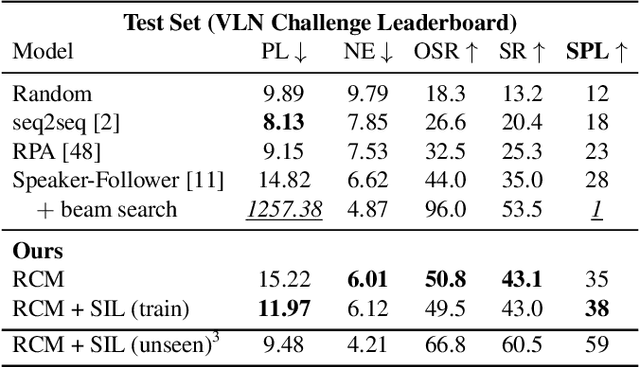
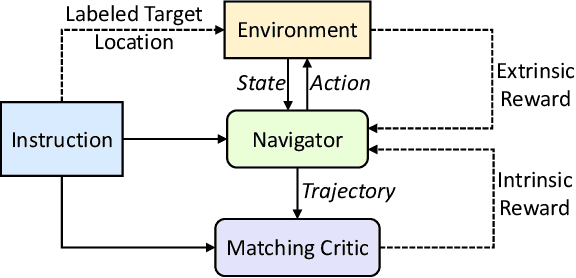

Vision-language navigation (VLN) is the task of navigating an embodied agent to carry out natural language instructions inside real 3D environments. In this paper, we study how to address three critical challenges for this task: the cross-modal grounding, the ill-posed feedback, and the generalization problems. First, we propose a novel Reinforced Cross-Modal Matching (RCM) approach that enforces cross-modal grounding both locally and globally via reinforcement learning (RL). Particularly, a matching critic is used to provide an intrinsic reward to encourage global matching between instructions and trajectories, and a reasoning navigator is employed to perform cross-modal grounding in the local visual scene. Evaluation on a VLN benchmark dataset shows that our RCM model significantly outperforms previous methods by 10% on SPL and achieves the new state-of-the-art performance. To improve the generalizability of the learned policy, we further introduce a Self-Supervised Imitation Learning (SIL) method to explore unseen environments by imitating its own past, good decisions. We demonstrate that SIL can approximate a better and more efficient policy, which tremendously minimizes the success rate performance gap between seen and unseen environments (from 30.7% to 11.7%).
MAN: Moment Alignment Network for Natural Language Moment Retrieval via Iterative Graph Adjustment
Nov 30, 2018



This research strives for natural language moment retrieval in long, untrimmed video streams. The problem nevertheless is not trivial especially when a video contains multiple moments of interests and the language describes complex temporal dependencies, which often happens in real scenarios. We identify two crucial challenges: semantic misalignment and structural misalignment. However, existing approaches treat different moments separately and do not explicitly model complex moment-wise temporal relations. In this paper, we present Moment Alignment Network (MAN), a novel framework that unifies the candidate moment encoding and temporal structural reasoning in a single-shot feed-forward network. MAN naturally assigns candidate moment representations aligned with language semantics over different temporal locations and scales. Most importantly, we propose to explicitly model moment-wise temporal relations as a structured graph and devise an iterative graph adjustment network to jointly learn the best structure in an end-to-end manner. We evaluate the proposed approach on two challenging public benchmarks Charades-STA and DiDeMo, where our MAN significantly outperforms the state-of-the-art by a large margin.
Dynamic Temporal Pyramid Network: A Closer Look at Multi-Scale Modeling for Activity Detection
Aug 07, 2018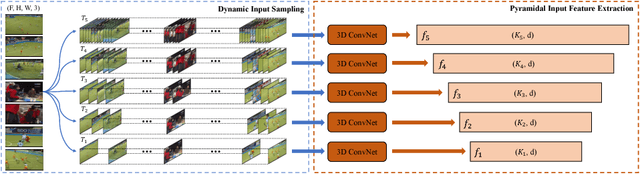
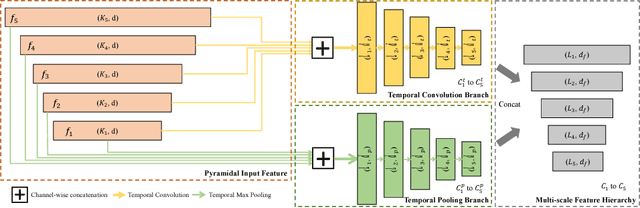
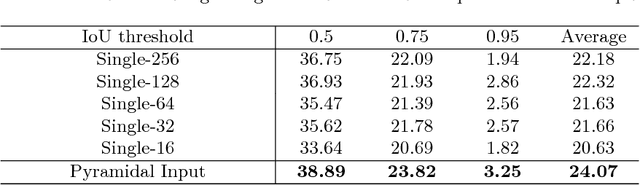
Recognizing instances at different scales simultaneously is a fundamental challenge in visual detection problems. While spatial multi-scale modeling has been well studied in object detection, how to effectively apply a multi-scale architecture to temporal models for activity detection is still under-explored. In this paper, we identify three unique challenges that need to be specifically handled for temporal activity detection compared to its spatial counterpart. To address all these issues, we propose Dynamic Temporal Pyramid Network (DTPN), a new activity detection framework with a multi-scale pyramidal architecture featuring three novel designs: (1) We sample input video frames dynamically with varying frame per seconds (FPS) to construct a natural pyramidal input for video of an arbitrary length. (2) We design a two-branch multi-scale temporal feature hierarchy to deal with the inherent temporal scale variation of activity instances. (3) We further exploit the temporal context of activities by appropriately fusing multi-scale feature maps, and demonstrate that both local and global temporal contexts are important. By combining all these components into a uniform network, we end up with a single-shot activity detector involving single-pass inferencing and end-to-end training. Extensive experiments show that the proposed DTPN achieves state-of-the-art performance on the challenging ActvityNet dataset.
S3D: Single Shot multi-Span Detector via Fully 3D Convolutional Networks
Aug 07, 2018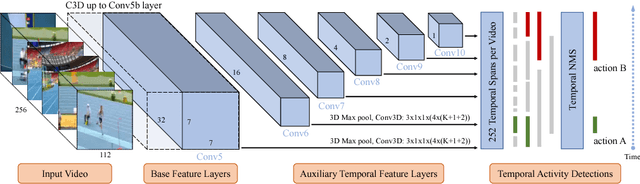


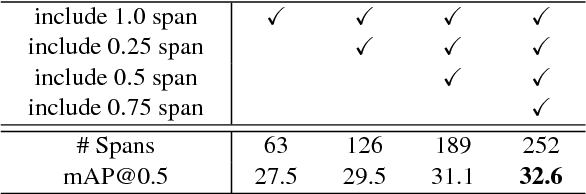
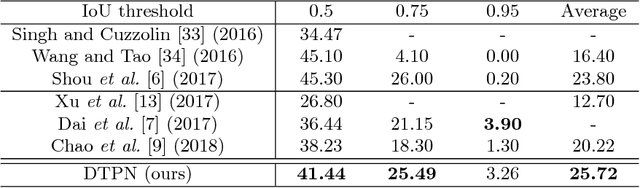
In this paper, we present a novel Single Shot multi-Span Detector for temporal activity detection in long, untrimmed videos using a simple end-to-end fully three-dimensional convolutional (Conv3D) network. Our architecture, named S3D, encodes the entire video stream and discretizes the output space of temporal activity spans into a set of default spans over different temporal locations and scales. At prediction time, S3D predicts scores for the presence of activity categories in each default span and produces temporal adjustments relative to the span location to predict the precise activity duration. Unlike many state-of-the-art systems that require a separate proposal and classification stage, our S3D is intrinsically simple and dedicatedly designed for single-shot, end-to-end temporal activity detection. When evaluating on THUMOS'14 detection benchmark, S3D achieves state-of-the-art performance and is very efficient and can operate at 1271 FPS.
No Metrics Are Perfect: Adversarial Reward Learning for Visual Storytelling
Jul 09, 2018



Though impressive results have been achieved in visual captioning, the task of generating abstract stories from photo streams is still a little-tapped problem. Different from captions, stories have more expressive language styles and contain many imaginary concepts that do not appear in the images. Thus it poses challenges to behavioral cloning algorithms. Furthermore, due to the limitations of automatic metrics on evaluating story quality, reinforcement learning methods with hand-crafted rewards also face difficulties in gaining an overall performance boost. Therefore, we propose an Adversarial REward Learning (AREL) framework to learn an implicit reward function from human demonstrations, and then optimize policy search with the learned reward function. Though automatic eval- uation indicates slight performance boost over state-of-the-art (SOTA) methods in cloning expert behaviors, human evaluation shows that our approach achieves significant improvement in generating more human-like stories than SOTA systems.
Watch, Listen, and Describe: Globally and Locally Aligned Cross-Modal Attentions for Video Captioning
Apr 15, 2018
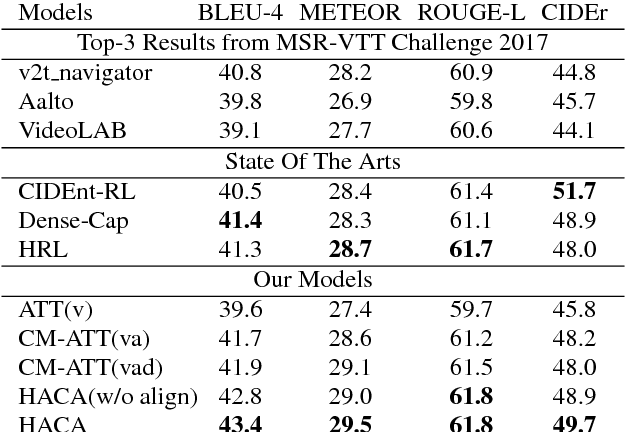
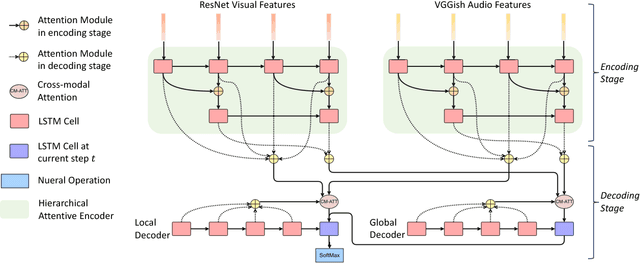

A major challenge for video captioning is to combine audio and visual cues. Existing multi-modal fusion methods have shown encouraging results in video understanding. However, the temporal structures of multiple modalities at different granularities are rarely explored, and how to selectively fuse the multi-modal representations at different levels of details remains uncharted. In this paper, we propose a novel hierarchically aligned cross-modal attention (HACA) framework to learn and selectively fuse both global and local temporal dynamics of different modalities. Furthermore, for the first time, we validate the superior performance of the deep audio features on the video captioning task. Finally, our HACA model significantly outperforms the previous best systems and achieves new state-of-the-art results on the widely used MSR-VTT dataset.