 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sparse R-CNN
May 04, 2022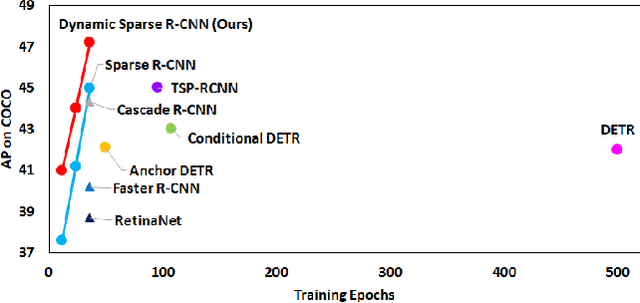
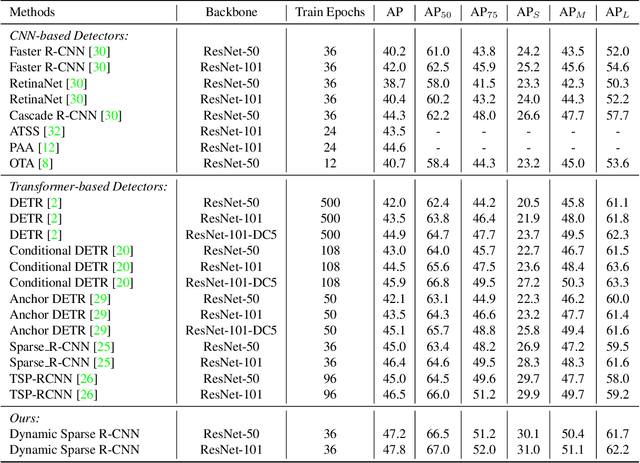
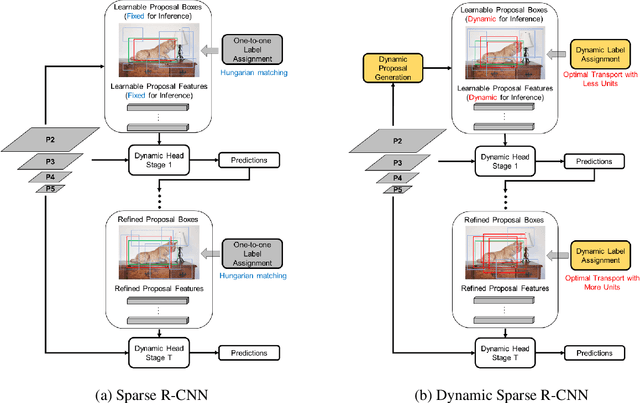

Sparse R-CNN is a recent strong object detection baseline by set prediction on sparse, learnable proposal boxes and proposal features. In this work, we propose to improve Sparse R-CNN with two dynamic designs. First, Sparse R-CNN adopts a one-to-one label assignment scheme, where the Hungarian algorithm is applied to match only one positive sample for each ground truth. Such one-to-one assignment may not be optimal for the matching between the learned proposal boxes and ground truths. To address this problem, we propose dynamic label assignment (DLA) based on the optimal transport algorithm to assign increasing positive samples in the iterative training stages of Sparse R-CNN. We constrain the matching to be gradually looser in the sequential stages as the later stage produces the refined proposals with improved precision. Second, the learned proposal boxes and features remain fixed for different images in the inference process of Sparse R-CNN. Motivated by dynamic convolution, we propose dynamic proposal generation (DPG) to assemble multiple proposal experts dynamically for providing better initial proposal boxes and features for the consecutive training stages. DPG thereby can derive sample-dependent proposal boxes and features for inference. Experiments demonstrate that our method, named Dynamic Sparse R-CNN, can boost the strong Sparse R-CNN baseline with different backbones for object detection. Particularly, Dynamic Sparse R-CNN reaches the state-of-the-art 47.2% AP on the COCO 2017 validation set, surpassing Sparse R-CNN by 2.2% AP with the same ResNet-50 backbone.
Empirical Quantitative Analysis of COVID-19 Forecasting Models
Oct 01, 2021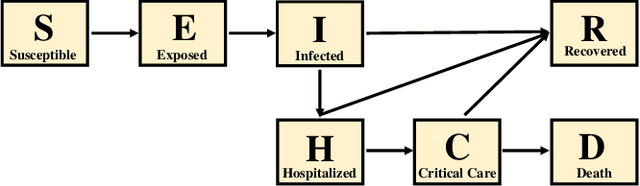
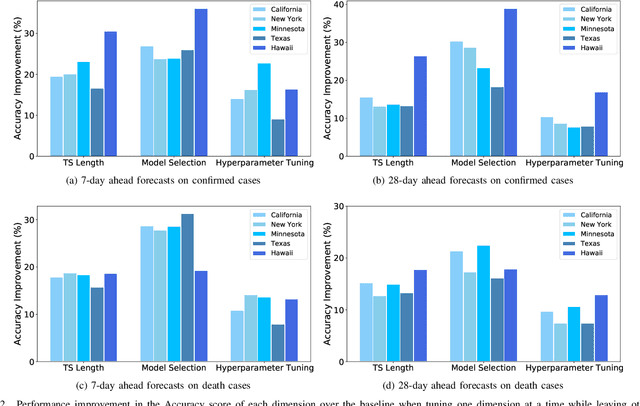
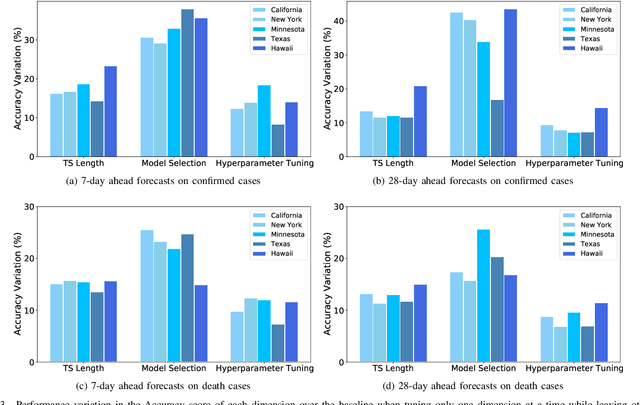
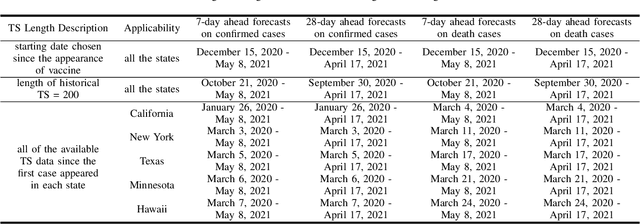
COVID-19 has been a public health emergency of international concern since early 2020. Reliable forecasting is critical to diminish the impact of this disease. To date, a large number of different forecasting models have been proposed, mainly including statistical models, compartmental models, and deep learning models. However, due to various uncertain factors across different regions such as economics and government policy, no forecasting model appears to be the best for all scenarios. In this paper, we perform quantitative analysis of COVID-19 forecasting of confirmed cases and deaths across different regions in the United States with different forecasting horizons, and evaluate the relative impacts of the following three dimensions on the predictive performance (improvement and variation) through different evaluation metrics: model selection, hyperparameter tuning, and the length of time series required for training. We find that if a dimension brings about higher performance gains, if not well-tuned, it may also lead to harsher performance penalties. Furthermore, model selection is the dominant factor in determining the predictive performance. It is responsible for both the largest improvement and the largest variation in performance in all prediction tasks across different regions. While practitioners may perform more complicated time series analysis in practice, they should be able to achieve reasonable results if they have adequate insight into key decisions like model selection.
BERTSurv: BERT-Based Survival Models for Predicting Outcomes of Trauma Patients
Mar 19, 2021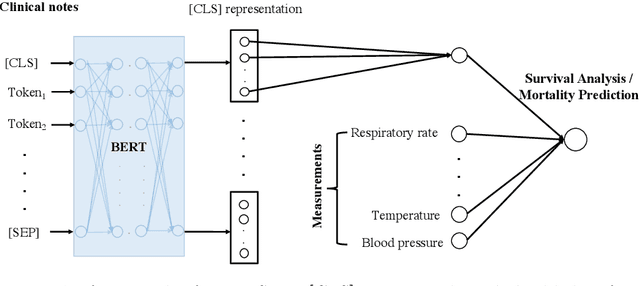
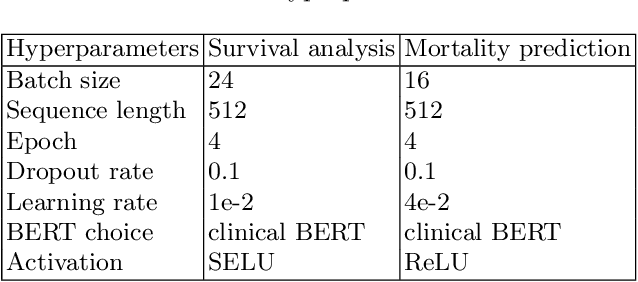
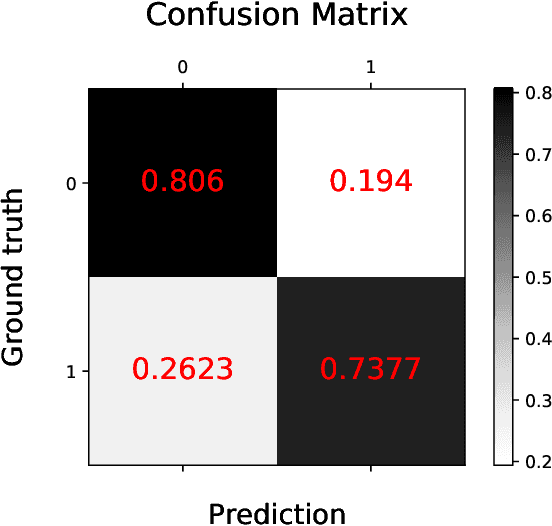
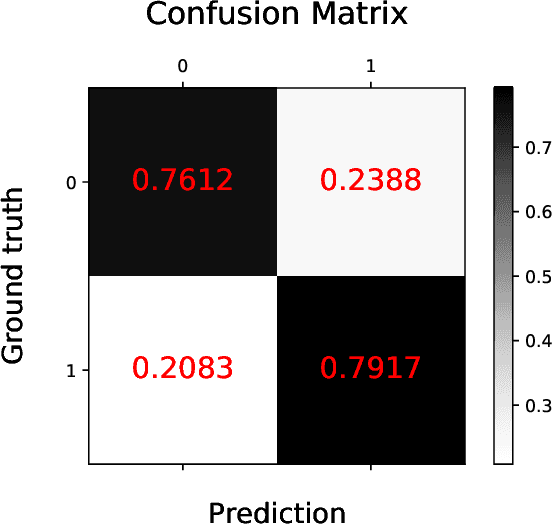
Survival analysis is a technique to predict the times of specific outcomes, and is widely used in predicting the outcomes for intensive care unit (ICU) trauma patients. Recently, deep learning models have drawn increasing attention in healthcare. However, there is a lack of deep learning methods that can model the relationship between measurements, clinical notes and mortality outcomes. In this paper we introduce BERTSurv, a deep learning survival framework which applies Bidirectional Encoder Representations from Transformers (BERT) as a language representation model on unstructured clinical notes, for mortality prediction and survival analysis. We also incorporate clinical measurements in BERTSurv. With binary cross-entropy (BCE) loss, BERTSurv can predict mortality as a binary outcome (mortality prediction). With partial log-likelihood (PLL) loss, BERTSurv predicts the probability of mortality as a time-to-event outcome (survival analysis). We apply BERTSurv on Medical Information Mart for Intensive Care III (MIMIC III) trauma patient data. For mortality prediction, BERTSurv obtained an area under the curve of receiver operating characteristic curve (AUC-ROC) of 0.86, which is an improvement of 3.6% over baseline of multilayer perceptron (MLP) without notes. For survival analysis, BERTSurv achieved a concordance index (C-index) of 0.7. In addition, visualizations of BERT's attention heads help to extract patterns in clinical notes and improve model interpretability by showing how the model assigns weights to different inputs.
How Much Does It Hurt: A Deep Learning Framework for Chronic Pain Score Assessment
Sep 22, 2020
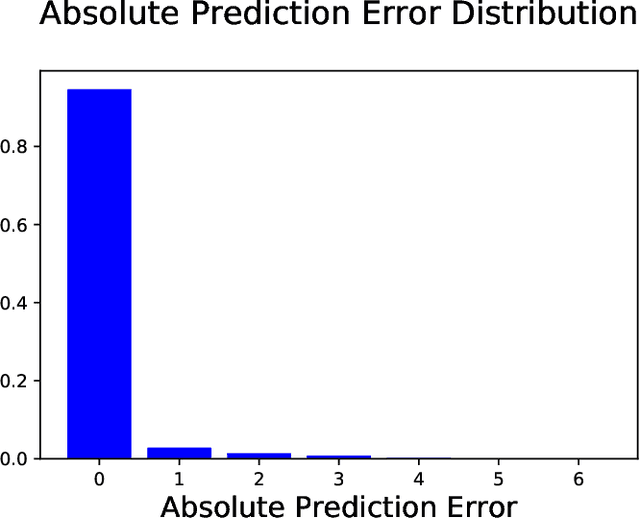
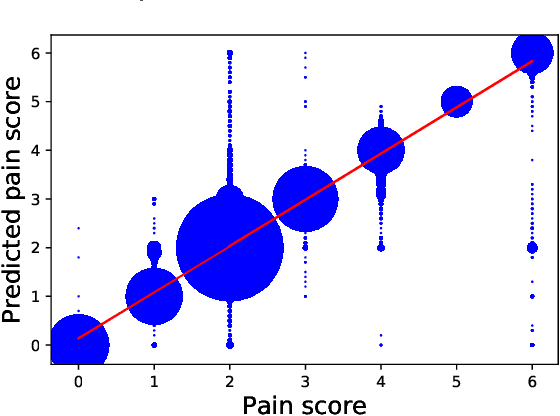
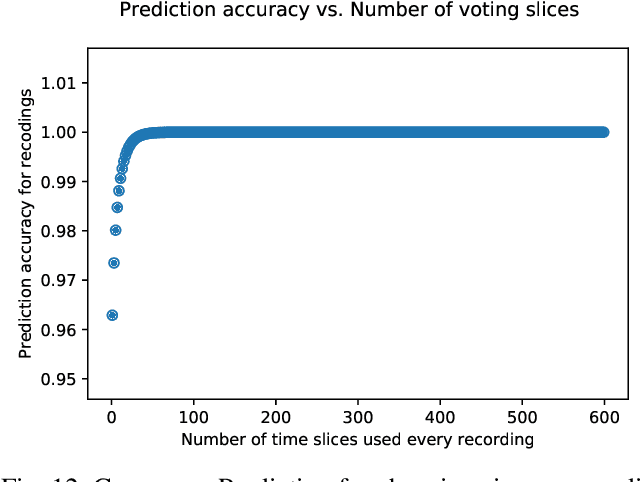
Chronic pain is defined as pain that lasts or recurs for more than 3 to 6 months, often long after the injury or illness that initially caused the pain has healed. The "gold standard" for chronic pain assessment remains self report and clinical assessment via a biopsychosocial interview, since there has been no device that can measure it. A device to measure pain would be useful not only for clinical assessment, but potentially also as a biofeedback device leading to pain reduction. In this paper we propose an end-to-end deep learning framework for chronic pain score assessment. Our deep learning framework splits the long time-course data samples into shorter sequences, and uses Consensus Prediction to classify the results. We evaluate the performance of our framework on two chronic pain score datasets collected from two iterations of prototype Pain Meters that we have developed to help chronic pain subjects better understand their health condition.