 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian-Symbolic Integration for Uncertainty-Aware Parking Prediction
Mar 28, 2026Accurate parking availability prediction is critical for intelligent transportation systems, but real-world deployments often face data sparsity, noise, and unpredictable changes. Addressing these challenges requires models that are not only accurate but also uncertainty-aware. In this work, we propose a loosely coupled neuro-symbolic framework that integrates Bayesian Neural Networks (BNNs) with symbolic reasoning to enhance robustness in uncertain environments. BNNs quantify predictive uncertainty, while symbolic knowledge extracted via decision trees and encoded using probabilistic logic programming is leveraged in two hybrid strategies: (1) using symbolic reasoning as a fallback when BNN confidence is low, and (2) refining output classes based on symbolic constraints before reapplying the BNN. We evaluate both strategies on real-world parking data under full, sparse, and noisy conditions. Results demonstrate that both hybrid methods outperform symbolic reasoning alone, and the context-refinement strategy consistently exceeds the performance of Long Short-Term Memory (LSTM) networks and BNN baselines across all prediction windows. Our findings highlight the potential of modular neuro-symbolic integration in real-world, uncertainty-prone prediction tasks.
Toward Dignity-Aware AI: Next-Generation Elderly Monitoring from Fall Detection to ADL
Nov 12, 2025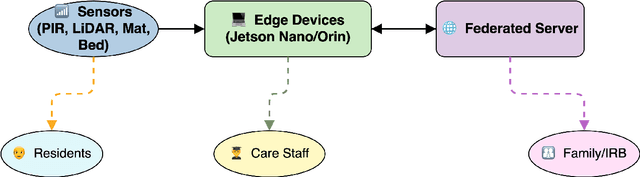



This position paper envisions a next-generation elderly monitoring system that moves beyond fall detection toward the broader goal of Activities of Daily Living (ADL) recognition. Our ultimate aim is to design privacy-preserving, edge-deployed, and federated AI systems that can robustly detect and understand daily routines, supporting independence and dignity in aging societies. At present, ADL-specific datasets are still under collection. As a preliminary step, we demonstrate feasibility through experiments using the SISFall dataset and its GAN-augmented variants, treating fall detection as a proxy task. We report initial results on federated learning with non-IID conditions, and embedded deployment on Jetson Orin Nano devices. We then outline open challenges such as domain shift, data scarcity, and privacy risks, and propose directions toward full ADL monitoring in smart-room environments. This work highlights the transition from single-task detection to comprehensive daily activity recognition, providing both early evidence and a roadmap for sustainable and human-centered elderly care AI.
Virtual Traffic Lights for Multi-Robot Navigation: Decentralized Planning with Centralized Conflict Resolution
Nov 11, 2025We present a hybrid multi-robot coordination framework that combines decentralized path planning with centralized conflict resolution. In our approach, each robot autonomously plans its path and shares this information with a centralized node. The centralized system detects potential conflicts and allows only one of the conflicting robots to proceed at a time, instructing others to stop outside the conflicting area to avoid deadlocks. Unlike traditional centralized planning methods, our system does not dictate robot paths but instead provides stop commands, functioning as a virtual traffic light. In simulation experiments with multiple robots, our approach increased the success rate of robots reaching their goals while reducing deadlocks. Furthermore, we successfully validated the system in real-world experiments with two quadruped robots and separately with wheeled Duckiebots.
Indoor PM2.5 forecasting and the association with outdoor air pollution: a modelling study based on sensor data in Australia
May 13, 2024



Exposure to poor indoor air quality poses significant health risks, necessitating thorough assessment to mitigate associated dangers. This study aims to predict hourly indoor fine particulate matter (PM2.5) concentrations and investigate their correlation with outdoor PM2.5 levels across 24 distinct buildings in Australia. Indoor air quality data were gathered from 91 monitoring sensors in eight Australian cities spanning 2019 to 2022. Employing an innovative three-stage deep ensemble machine learning framework (DEML), comprising three base models (Support Vector Machine, Random Forest, and eXtreme Gradient Boosting) and two meta-models (Random Forest and Generalized Linear Model), hourly indoor PM2.5 concentrations were predicted. The model's accuracy was evaluated using a rolling windows approach, comparing its performance against three benchmark algorithms (SVM, RF, and XGBoost). Additionally, a correlation analysis assessed the relationship between indoor and outdoor PM2.5 concentrations. Results indicate that the DEML model consistently outperformed benchmark models, achieving an R2 ranging from 0.63 to 0.99 and RMSE from 0.01 to 0.663 mg/m3 for most sensors. Notably, outdoor PM2.5 concentrations significantly impacted indoor air quality, particularly evident during events like bushfires. This study underscores the importance of accurate indoor air quality prediction, crucial for developing location-specific early warning systems and informing effective interventions. By promoting protective behaviors, these efforts contribute to enhanced public health outcomes.
Predicting Next Useful Location With Context-Awareness: The State-Of-The-Art
Jan 16, 2024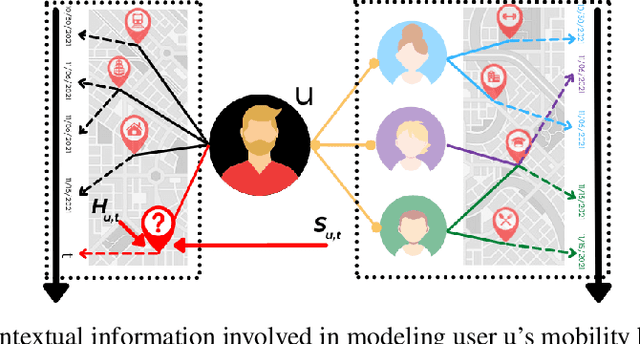
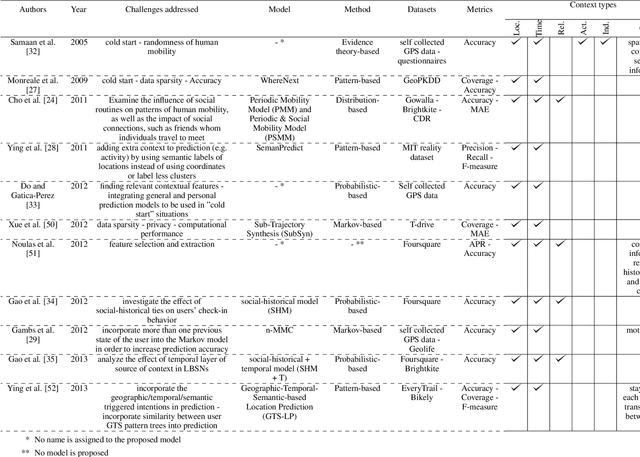


Predicting the future location of mobile objects reinforces location-aware services with proactive intelligence and helps businesses and decision-makers with better planning and near real-time scheduling in different applications such as traffic congestion control, location-aware advertisements, and monitoring public health and well-being. The recent developments in the smartphone and location sensors technology and the prevalence of using location-based social networks alongside the improvements in artificial intelligence and machine learning techniques provide an excellent opportunity to exploit massive amounts of historical and real-time contextual information to recognise mobility patterns and achieve more accurate and intelligent predictions. This survey provides a comprehensive overview of the next useful location prediction problem with context-awareness. First, we explain the concepts of context and context-awareness and define the next location prediction problem. Then we analyse nearly thirty studies in this field concerning the prediction method, the challenges addressed, the datasets and metrics used for training and evaluating the model, and the types of context incorporated. Finally, we discuss the advantages and disadvantages of different approaches, focusing on the usefulness of the predicted location and identifying the open challenges and future work on this subject by introducing two potential use cases of next location prediction in the automotive industry.
Energy-Efficient UAV-Assisted IoT Data Collection via TSP-Based Solution Space Reduction
Jun 02, 2023
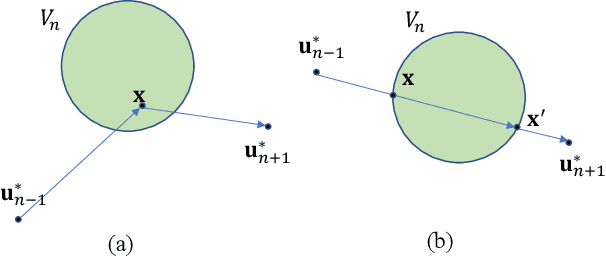
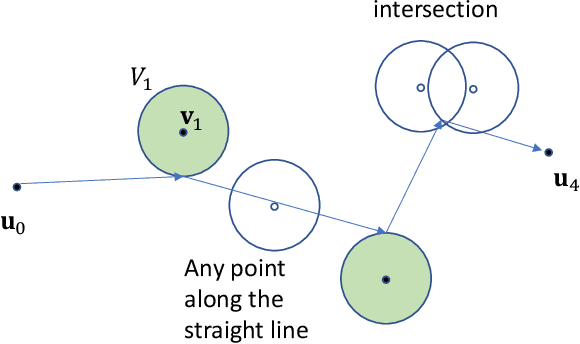
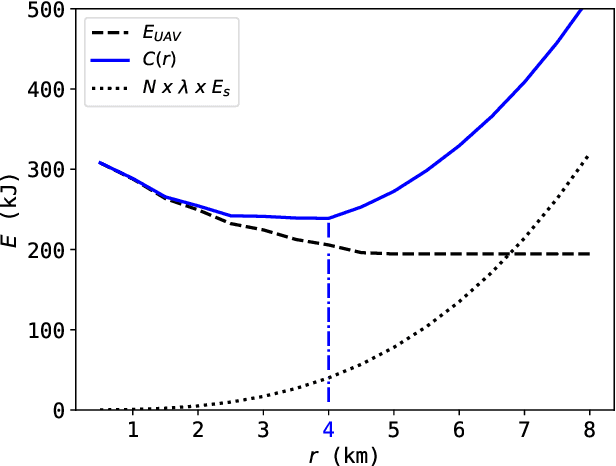
This paper presents a wireless data collection framework that employs an unmanned aerial vehicle (UAV) to efficiently gather data from distributed IoT sensors deployed in a large area. Our approach takes into account the non-zero communication ranges of the sensors to optimize the flight path of the UAV, resulting in a variation of the Traveling Salesman Problem (TSP). We prove mathematically that the optimal waypoints for this TSP-variant problem are restricted to the boundaries of the sensor communication ranges, greatly reducing the solution space. Building on this finding, we develop a low-complexity UAV-assisted sensor data collection algorithm, and demonstrate its effectiveness in a selected use case where we minimize the total energy consumption of the UAV and sensors by jointly optimizing the UAV's travel distance and the sensors' communication ranges.
On Correlated Knowledge Distillation for Monitoring Human Pose with Radios
May 24, 2023



In this work, we propose and develop a simple experimental testbed to study the feasibility of a novel idea by coupling radio frequency (RF) sensing technology with Correlated Knowledge Distillation (CKD) theory towards designing lightweight, near real-time and precise human pose monitoring systems. The proposed CKD framework transfers and fuses pose knowledge from a robust "Teacher" model to a parameterized "Student" model, which can be a promising technique for obtaining accurate yet lightweight pose estimates. To assure its efficacy, we implemented CKD for distilling logits in our integrated Software Defined Radio (SDR)-based experimental setup and investigated the RF-visual signal correlation. Our CKD-RF sensing technique is characterized by two modes -- a camera-fed Teacher Class Network (e.g., images, videos) with an SDR-fed Student Class Network (e.g., RF signals). Specifically, our CKD model trains a dual multi-branch teacher and student network by distilling and fusing knowledge bases. The resulting CKD models are then subsequently used to identify the multimodal correlation and teach the student branch in reverse. Instead of simply aggregating their learnings, CKD training comprised multiple parallel transformations with the two domains, i.e., visual images and RF signals. Once trained, our CKD model can efficiently preserve privacy and utilize the multimodal correlated logits from the two different neural networks for estimating poses without using visual signals/video frames (by using only the RF signals).
Context Query Simulation for Smart Carparking Scenarios in the Melbourne CDB
Feb 13, 2023
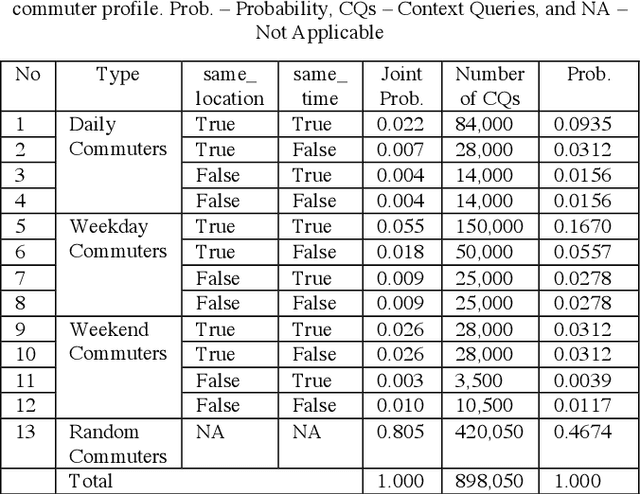
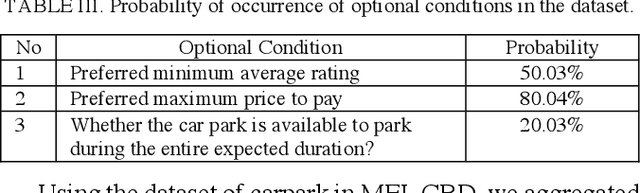

The rapid growth in Internet of Things (IoT) has ushered in the way for better context-awareness enabling more smarter applications. Although for the growth in the number of IoT devices, Context Management Platforms (CMPs) that integrate different domains of IoT to produce context information lacks scalability to cater to a high volume of context queries. Research in scalability and adaptation in CMPs are of significant importance due to this reason. However, there is limited methods to benchmarks and validate research in this area due to the lack of sizable sets of context queries that could simulate real-world situations, scenarios, and scenes. Commercially collected context query logs are not publicly accessible and deploying IoT devices, and context consumers in the real-world at scale is expensive and consumes a significant effort and time. Therefore, there is a need to develop a method to reliably generate and simulate context query loads that resembles real-world scenarios to test CMPs for scale. In this paper, we propose a context query simulator for the context-aware smart car parking scenario in Melbourne Central Business District in Australia. We present the process of generating context queries using multiple real-world datasets and publicly accessible reports, followed by the context query execution process. The context query generator matches the popularity of places with the different profiles of commuters, preferences, and traffic variations to produce a dataset of context query templates containing 898,050 records. The simulator is executable over a seven-day profile which far exceeds the simulation time of any IoT system simulator. The context query generation process is also generic and context query language independent.
Poisoning Attacks and Defenses in Federated Learning: A Survey
Jan 14, 2023Federated learning (FL) enables the training of models among distributed clients without compromising the privacy of training datasets, while the invisibility of clients datasets and the training process poses a variety of security threats. This survey provides the taxonomy of poisoning attacks and experimental evaluation to discuss the need for robust FL.
Reinforcement Learning Based Approaches to Adaptive Context Caching in Distributed Context Management Systems
Dec 22, 2022Performance metrics-driven context caching has a profound impact on throughput and response time in distributed context management systems for real-time context queries. This paper proposes a reinforcement learning based approach to adaptively cache context with the objective of minimizing the cost incurred by context management systems in responding to context queries. Our novel algorithms enable context queries and sub-queries to reuse and repurpose cached context in an efficient manner. This approach is distinctive to traditional data caching approaches by three main features. First, we make selective context cache admissions using no prior knowledge of the context, or the context query load. Secondly, we develop and incorporate innovative heuristic models to calculate expected performance of caching an item when making the decisions. Thirdly, our strategy defines a time-aware continuous cache action space. We present two reinforcement learning agents, a value function estimating actor-critic agent and a policy search agent using deep deterministic policy gradient method. The paper also proposes adaptive policies such as eviction and cache memory scaling to complement our objective. Our method is evaluated using a synthetically generated load of context sub-queries and a synthetic data set inspired from real world data and query samples. We further investigate optimal adaptive caching configurations under different settings. This paper presents, compares, and discusses our findings that the proposed selective caching methods reach short- and long-term cost- and performance-efficiency. The paper demonstrates that the proposed methods outperform other modes of context management such as redirector mode, and database mode, and cache all policy by up to 60% in cost efficiency.