 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Next Useful Location With Context-Awareness: The State-Of-The-Art
Jan 16, 2024Predicting the future location of mobile objects reinforces location-aware services with proactive intelligence and helps businesses and decision-makers with better planning and near real-time scheduling in different applications such as traffic congestion control, location-aware advertisements, and monitoring public health and well-being. The recent developments in the smartphone and location sensors technology and the prevalence of using location-based social networks alongside the improvements in artificial intelligence and machine learning techniques provide an excellent opportunity to exploit massive amounts of historical and real-time contextual information to recognise mobility patterns and achieve more accurate and intelligent predictions. This survey provides a comprehensive overview of the next useful location prediction problem with context-awareness. First, we explain the concepts of context and context-awareness and define the next location prediction problem. Then we analyse nearly thirty studies in this field concerning the prediction method, the challenges addressed, the datasets and metrics used for training and evaluating the model, and the types of context incorporated. Finally, we discuss the advantages and disadvantages of different approaches, focusing on the usefulness of the predicted location and identifying the open challenges and future work on this subject by introducing two potential use cases of next location prediction in the automotive industry.
On Correlated Knowledge Distillation for Monitoring Human Pose with Radios
May 24, 2023In this work, we propose and develop a simple experimental testbed to study the feasibility of a novel idea by coupling radio frequency (RF) sensing technology with Correlated Knowledge Distillation (CKD) theory towards designing lightweight, near real-time and precise human pose monitoring systems. The proposed CKD framework transfers and fuses pose knowledge from a robust "Teacher" model to a parameterized "Student" model, which can be a promising technique for obtaining accurate yet lightweight pose estimates. To assure its efficacy, we implemented CKD for distilling logits in our integrated Software Defined Radio (SDR)-based experimental setup and investigated the RF-visual signal correlation. Our CKD-RF sensing technique is characterized by two modes -- a camera-fed Teacher Class Network (e.g., images, videos) with an SDR-fed Student Class Network (e.g., RF signals). Specifically, our CKD model trains a dual multi-branch teacher and student network by distilling and fusing knowledge bases. The resulting CKD models are then subsequently used to identify the multimodal correlation and teach the student branch in reverse. Instead of simply aggregating their learnings, CKD training comprised multiple parallel transformations with the two domains, i.e., visual images and RF signals. Once trained, our CKD model can efficiently preserve privacy and utilize the multimodal correlated logits from the two different neural networks for estimating poses without using visual signals/video frames (by using only the RF signals).
Reinforcement Learning Based Approaches to Adaptive Context Caching in Distributed Context Management Systems
Dec 22, 2022Performance metrics-driven context caching has a profound impact on throughput and response time in distributed context management systems for real-time context queries. This paper proposes a reinforcement learning based approach to adaptively cache context with the objective of minimizing the cost incurred by context management systems in responding to context queries. Our novel algorithms enable context queries and sub-queries to reuse and repurpose cached context in an efficient manner. This approach is distinctive to traditional data caching approaches by three main features. First, we make selective context cache admissions using no prior knowledge of the context, or the context query load. Secondly, we develop and incorporate innovative heuristic models to calculate expected performance of caching an item when making the decisions. Thirdly, our strategy defines a time-aware continuous cache action space. We present two reinforcement learning agents, a value function estimating actor-critic agent and a policy search agent using deep deterministic policy gradient method. The paper also proposes adaptive policies such as eviction and cache memory scaling to complement our objective. Our method is evaluated using a synthetically generated load of context sub-queries and a synthetic data set inspired from real world data and query samples. We further investigate optimal adaptive caching configurations under different settings. This paper presents, compares, and discusses our findings that the proposed selective caching methods reach short- and long-term cost- and performance-efficiency. The paper demonstrates that the proposed methods outperform other modes of context management such as redirector mode, and database mode, and cache all policy by up to 60% in cost efficiency.
From Traditional Adaptive Data Caching to Adaptive Context Caching: A Survey
Nov 21, 2022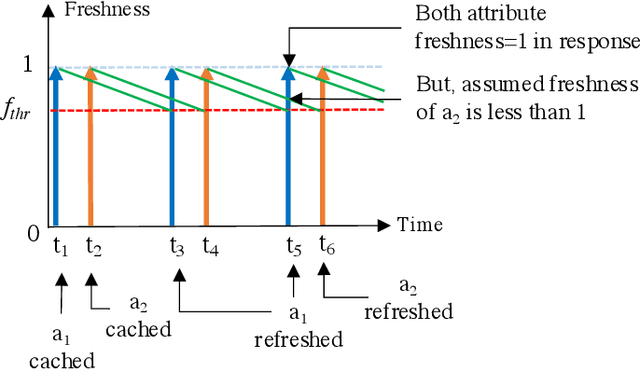
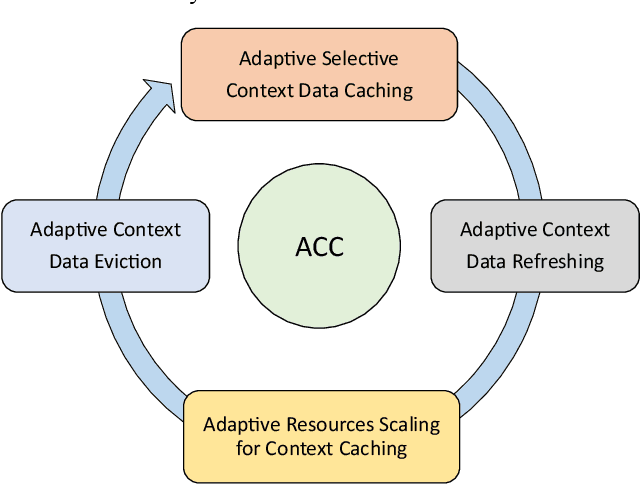
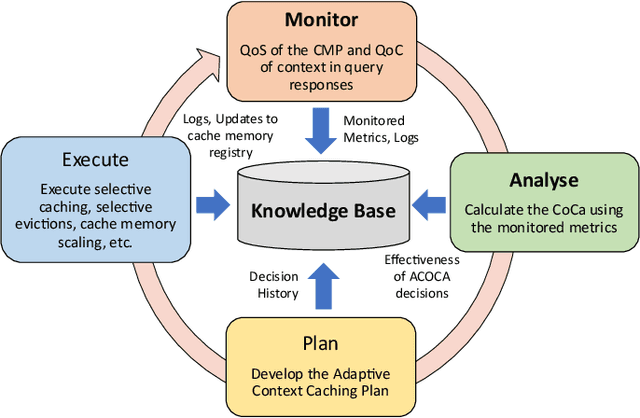
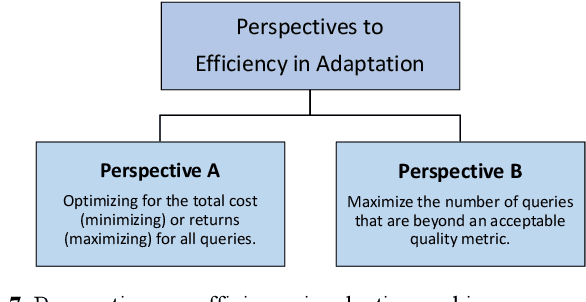
Context data is in demand more than ever with the rapid increase in the development of many context-aware Internet of Things applications. Research in context and context-awareness is being conducted to broaden its applicability in light of many practical and technical challenges. One of the challenges is improving performance when responding to large number of context queries. Context Management Platforms that infer and deliver context to applications measure this problem using Quality of Service (QoS) parameters. Although caching is a proven way to improve QoS, transiency of context and features such as variability, heterogeneity of context queries pose an additional real-time cost management problem. This paper presents a critical survey of state-of-the-art in adaptive data caching with the objective of developing a body of knowledge in cost- and performance-efficient adaptive caching strategies. We comprehensively survey a large number of research publications and evaluate, compare, and contrast different techniques, policies, approaches, and schemes in adaptive caching. Our critical analysis is motivated by the focus on adaptively caching context as a core research problem. A formal definition for adaptive context caching is then proposed, followed by identified features and requirements of a well-designed, objective optimal adaptive context caching strategy.
Adversarial Attacks on Speech Recognition Systems for Mission-Critical Applications: A Survey
Feb 22, 2022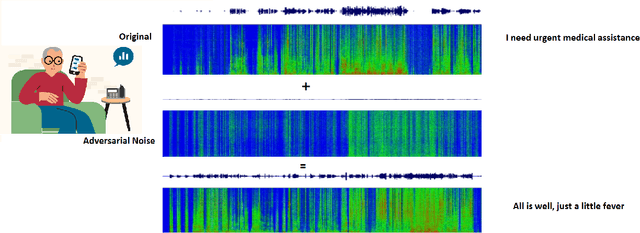
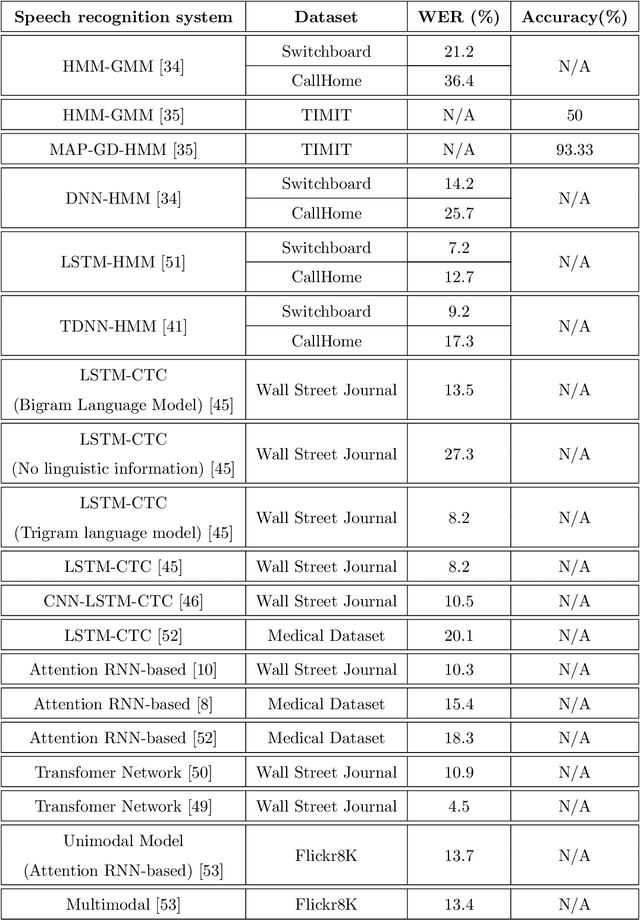
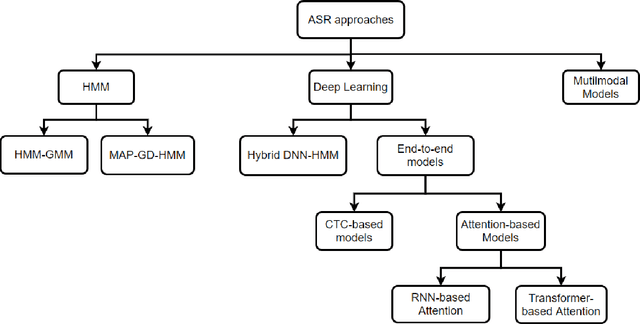
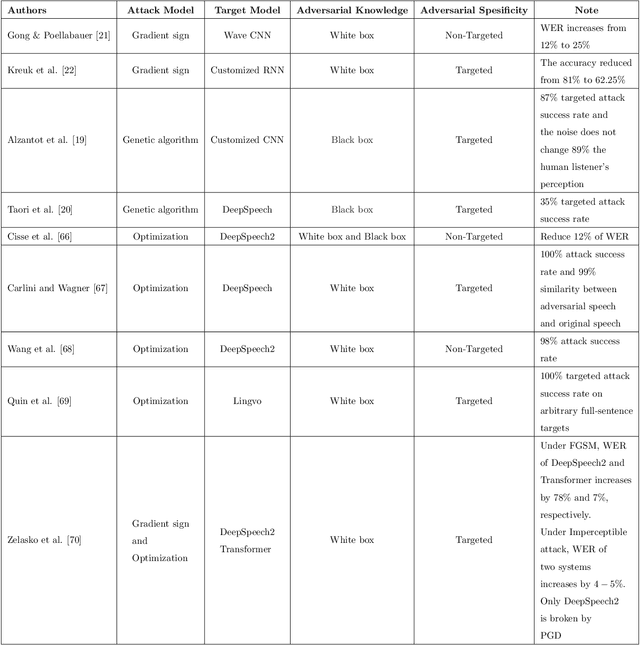
A Machine-Critical Application is a system that is fundamentally necessary to the success of specific and sensitive operations such as search and recovery, rescue, military, and emergency management actions. Recent advances in Machine Learning, Natural Language Processing, voice recognition, and speech processing technologies have naturally allowed the development and deployment of speech-based conversational interfaces to interact with various machine-critical applications. While these conversational interfaces have allowed users to give voice commands to carry out strategic and critical activities, their robustness to adversarial attacks remains uncertain and unclear. Indeed, Adversarial Artificial Intelligence (AI) which refers to a set of techniques that attempt to fool machine learning models with deceptive data, is a growing threat in the AI and machine learning research community, in particular for machine-critical applications. The most common reason of adversarial attacks is to cause a malfunction in a machine learning model. An adversarial attack might entail presenting a model with inaccurate or fabricated samples as it's training data, or introducing maliciously designed data to deceive an already trained model. While focusing on speech recognition for machine-critical applications, in this paper, we first review existing speech recognition techniques, then, we investigate the effectiveness of adversarial attacks and defenses against these systems, before outlining research challenges, defense recommendations, and future work. This paper is expected to serve researchers and practitioners as a reference to help them in understanding the challenges, position themselves and, ultimately, help them to improve existing models of speech recognition for mission-critical applications. Keywords: Mission-Critical Applications, Adversarial AI, Speech Recognition Systems.