 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon Perception
Mar 28, 2026Perception-centric systems are typically implemented with a modular encoder-decoder pipeline: a vision backbone for feature extraction and a separate decoder (or late-fusion module) for task prediction. This raises a central question: is this architectural separation essential or can a single early-fusion stack do both perception and task modeling at scale? We introduce Falcon Perception, a unified dense Transformer that processes image patches and text tokens in a shared parameter space from the first layer, using a hybrid attention pattern (bidirectional among image tokens, causal for prediction tokens) to combine global visual context with autoregressive, variable-length instance generation. To keep dense outputs practical, Falcon Perception retains a lightweight token interface and decodes continuous spatial outputs with specialized heads, enabling parallel high-resolution mask prediction. Our design promotes simplicity: we keep a single scalable backbone and shift complexity toward data and training signals, adding only small heads where outputs are continuous and dense. On SA-Co, Falcon Perception improves mask quality to 68.0 Macro-F$_1$ compared to 62.3 of SAM3. We also introduce PBench, a benchmark targeting compositional prompts (OCR, spatial constraints, relations) and dense long-context regimes, where the model shows better gains. Finally, we extend the same early-fusion recipe to Falcon OCR: a compact 300M-parameter model which attains 80.3% on olmOCR and 88.64 on OmniDocBench.
VisRes Bench: On Evaluating the Visual Reasoning Capabilities of VLMs
Dec 24, 2025Vision-Language Models (VLMs) have achieved remarkable progress across tasks such as visual question answering and image captioning. Yet, the extent to which these models perform visual reasoning as opposed to relying on linguistic priors remains unclear. To address this, we introduce VisRes Bench, a benchmark designed to study visual reasoning in naturalistic settings without contextual language supervision. Analyzing model behavior across three levels of complexity, we uncover clear limitations in perceptual and relational visual reasoning capacities. VisRes isolates distinct reasoning abilities across its levels. Level 1 probes perceptual completion and global image matching under perturbations such as blur, texture changes, occlusion, and rotation; Level 2 tests rule-based inference over a single attribute (e.g., color, count, orientation); and Level 3 targets compositional reasoning that requires integrating multiple visual attributes. Across more than 19,000 controlled task images, we find that state-of-the-art VLMs perform near random under subtle perceptual perturbations, revealing limited abstraction beyond pattern recognition. We conclude by discussing how VisRes provides a unified framework for advancing abstract visual reasoning in multimodal research.
AMoE: Agglomerative Mixture-of-Experts Vision Foundation Model
Dec 23, 2025Vision foundation models trained via multi-teacher distillation offer a promising path toward unified visual representations, yet the learning dynamics and data efficiency of such approaches remain underexplored. In this paper, we systematically study multi-teacher distillation for vision foundation models and identify key factors that enable training at lower computational cost. We introduce Agglomerative Mixture-of-Experts Vision Foundation Models (AMoE), which distill knowledge from SigLIP2 and DINOv3 simultaneously into a Mixture-of-Experts student. We show that (1) our Asymmetric Relation-Knowledge Distillation loss preserves the geometric properties of each teacher while enabling effective knowledge transfer, (2) token-balanced batching that packs varying-resolution images into sequences with uniform token budgets stabilizes representation learning across resolutions without sacrificing performance, and (3) hierarchical clustering and sampling of training data--typically reserved for self-supervised learning--substantially improves sample efficiency over random sampling for multi-teacher distillation. By combining these findings, we curate OpenLVD200M, a 200M-image corpus that demonstrates superior efficiency for multi-teacher distillation. Instantiated in a Mixture-of-Experts. We release OpenLVD200M and distilled models.
Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance
Jul 30, 2025In this report, we introduce Falcon-H1, a new series of large language models (LLMs) featuring hybrid architecture designs optimized for both high performance and efficiency across diverse use cases. Unlike earlier Falcon models built solely on Transformer or Mamba architectures, Falcon-H1 adopts a parallel hybrid approach that combines Transformer-based attention with State Space Models (SSMs), known for superior long-context memory and computational efficiency. We systematically revisited model design, data strategy, and training dynamics, challenging conventional practices in the field. Falcon-H1 is released in multiple configurations, including base and instruction-tuned variants at 0.5B, 1.5B, 1.5B-deep, 3B, 7B, and 34B parameters. Quantized instruction-tuned models are also available, totaling over 30 checkpoints on Hugging Face Hub. Falcon-H1 models demonstrate state-of-the-art performance and exceptional parameter and training efficiency. The flagship Falcon-H1-34B matches or outperforms models up to 70B scale, such as Qwen3-32B, Qwen2.5-72B, and Llama3.3-70B, while using fewer parameters and less data. Smaller models show similar trends: the Falcon-H1-1.5B-Deep rivals current leading 7B-10B models, and Falcon-H1-0.5B performs comparably to typical 7B models from 2024. These models excel across reasoning, mathematics, multilingual tasks, instruction following, and scientific knowledge. With support for up to 256K context tokens and 18 languages, Falcon-H1 is suitable for a wide range of applications. All models are released under a permissive open-source license, underscoring our commitment to accessible and impactful AI research.
Visual question answering: from early developments to recent advances -- a survey
Jan 07, 2025
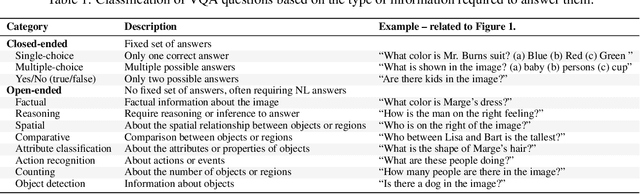


Visual Question Answering (VQA) is an evolving research field aimed at enabling machines to answer questions about visual content by integrating image and language processing techniques such as feature extraction, object detection, text embedding, natural language understanding, and language generation. With the growth of multimodal data research, VQA has gained significant attention due to its broad applications, including interactive educational tools, medical image diagnosis, customer service, entertainment, and social media captioning. Additionally, VQA plays a vital role in assisting visually impaired individuals by generating descriptive content from images. This survey introduces a taxonomy of VQA architectures, categorizing them based on design choices and key components to facilitate comparative analysis and evaluation. We review major VQA approaches, focusing on deep learning-based methods, and explore the emerging field of Large Visual Language Models (LVLMs) that have demonstrated success in multimodal tasks like VQA. The paper further examines available datasets and evaluation metrics essential for measuring VQA system performance, followed by an exploration of real-world VQA applications. Finally, we highlight ongoing challenges and future directions in VQA research, presenting open questions and potential areas for further development. This survey serves as a comprehensive resource for researchers and practitioners interested in the latest advancements and future
SimpsonsVQA: Enhancing Inquiry-Based Learning with a Tailored Dataset
Oct 30, 2024
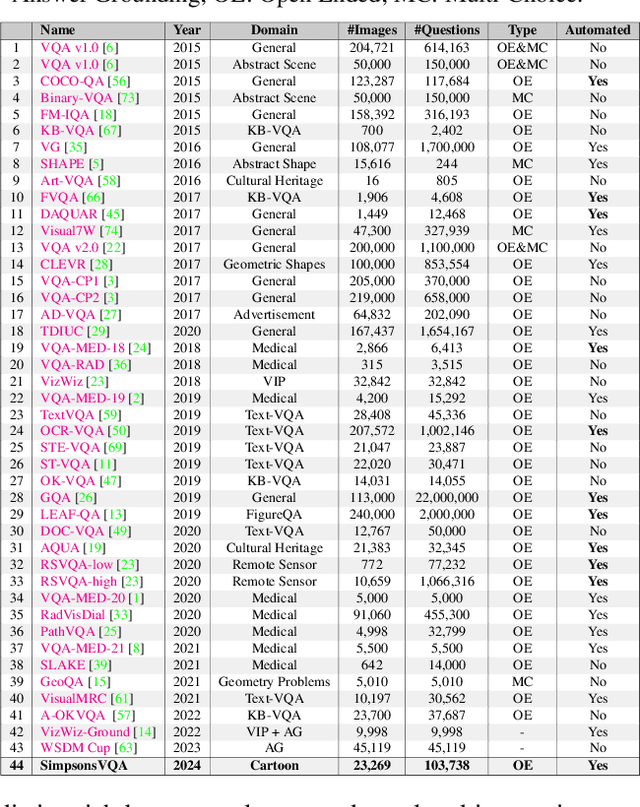

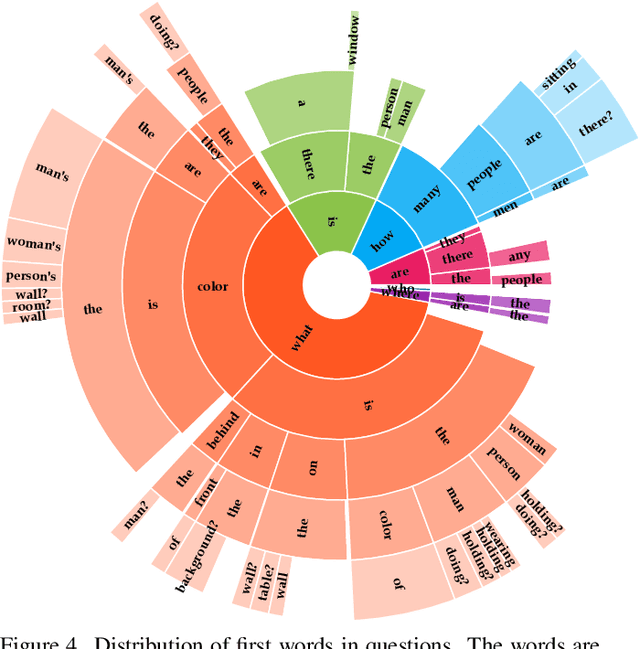
Visual Question Answering (VQA) has emerged as a promising area of research to develop AI-based systems for enabling interactive and immersive learning. Numerous VQA datasets have been introduced to facilitate various tasks, such as answering questions or identifying unanswerable ones. However, most of these datasets are constructed using real-world images, leaving the performance of existing models on cartoon images largely unexplored. Hence, in this paper, we present "SimpsonsVQA", a novel dataset for VQA derived from The Simpsons TV show, designed to promote inquiry-based learning. Our dataset is specifically designed to address not only the traditional VQA task but also to identify irrelevant questions related to images, as well as the reverse scenario where a user provides an answer to a question that the system must evaluate (e.g., as correct, incorrect, or ambiguous). It aims to cater to various visual applications, harnessing the visual content of "The Simpsons" to create engaging and informative interactive systems. SimpsonsVQA contains approximately 23K images, 166K QA pairs, and 500K judgments (https://simpsonsvqa.org). Our experiments show that current large vision-language models like ChatGPT4o underperform in zero-shot settings across all three tasks, highlighting the dataset's value for improving model performance on cartoon images. We anticipate that SimpsonsVQA will inspire further research, innovation, and advancements in inquiry-based learning VQA.
HUMS2023 Data Challenge Result Submission
Jul 14, 2023



We implemented a simple method for early detection in this research. The implemented methods are plotting the given mat files and analyzing scalogram images generated by performing Continuous Wavelet Transform (CWT) on the samples. Also, finding the mean, standard deviation (STD), and peak-to-peak (P2P) values from each signal also helped detect faulty signs. We have implemented the autoregressive integrated moving average (ARIMA) method to track the progression.
The STOIC2021 COVID-19 AI challenge: applying reusable training methodologies to private data
Jun 25, 2023Challenges drive the state-of-the-art of automated medical image analysis. The quantity of public training data that they provide can limit the performance of their solutions. Public access to the training methodology for these solutions remains absent. This study implements the Type Three (T3) challenge format, which allows for training solutions on private data and guarantees reusable training methodologies. With T3, challenge organizers train a codebase provided by the participants on sequestered training data. T3 was implemented in the STOIC2021 challenge, with the goal of predicting from a computed tomography (CT) scan whether subjects had a severe COVID-19 infection, defined as intubation or death within one month. STOIC2021 consisted of a Qualification phase, where participants developed challenge solutions using 2000 publicly available CT scans, and a Final phase, where participants submitted their training methodologies with which solutions were trained on CT scans of 9724 subjects. The organizers successfully trained six of the eight Final phase submissions. The submitted codebases for training and running inference were released publicly. The winning solution obtained an area under the receiver operating characteristic curve for discerning between severe and non-severe COVID-19 of 0.815. The Final phase solutions of all finalists improved upon their Qualification phase solutions.HSUXJM-TNZF9CHSUXJM-TNZF9C
Adversarial Attacks on Speech Recognition Systems for Mission-Critical Applications: A Survey
Feb 22, 2022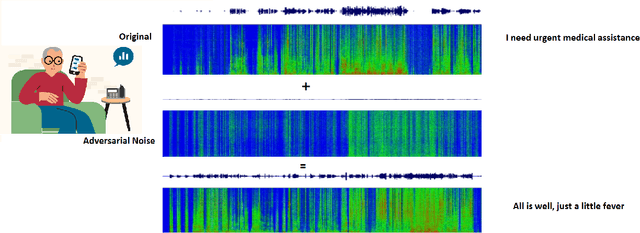
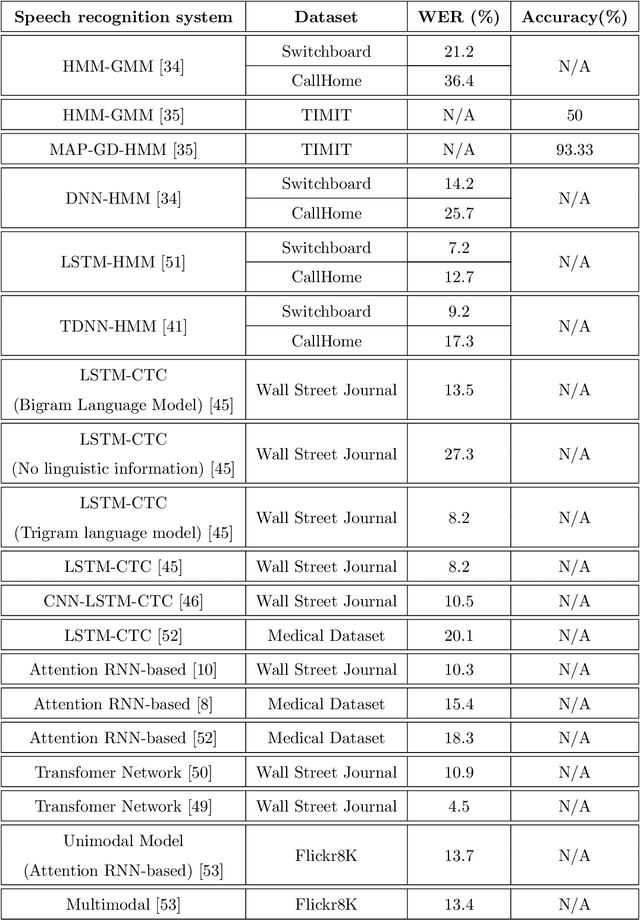
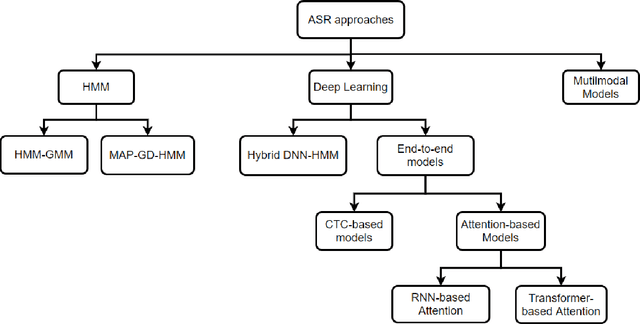
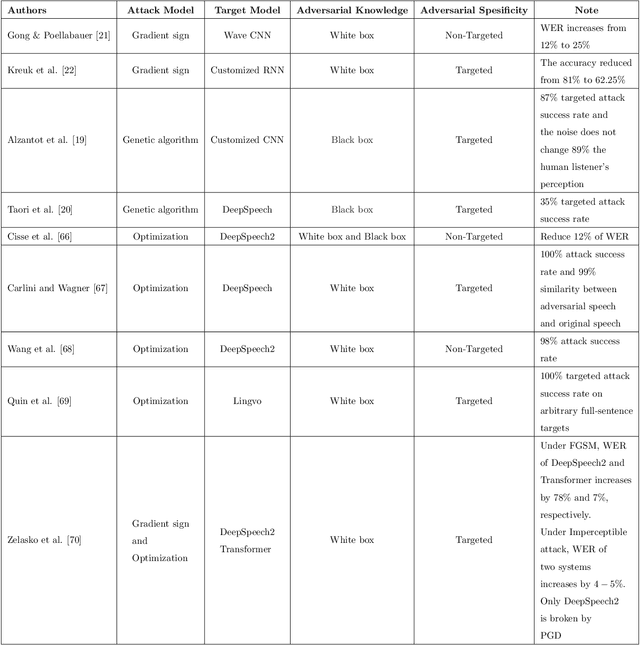
A Machine-Critical Application is a system that is fundamentally necessary to the success of specific and sensitive operations such as search and recovery, rescue, military, and emergency management actions. Recent advances in Machine Learning, Natural Language Processing, voice recognition, and speech processing technologies have naturally allowed the development and deployment of speech-based conversational interfaces to interact with various machine-critical applications. While these conversational interfaces have allowed users to give voice commands to carry out strategic and critical activities, their robustness to adversarial attacks remains uncertain and unclear. Indeed, Adversarial Artificial Intelligence (AI) which refers to a set of techniques that attempt to fool machine learning models with deceptive data, is a growing threat in the AI and machine learning research community, in particular for machine-critical applications. The most common reason of adversarial attacks is to cause a malfunction in a machine learning model. An adversarial attack might entail presenting a model with inaccurate or fabricated samples as it's training data, or introducing maliciously designed data to deceive an already trained model. While focusing on speech recognition for machine-critical applications, in this paper, we first review existing speech recognition techniques, then, we investigate the effectiveness of adversarial attacks and defenses against these systems, before outlining research challenges, defense recommendations, and future work. This paper is expected to serve researchers and practitioners as a reference to help them in understanding the challenges, position themselves and, ultimately, help them to improve existing models of speech recognition for mission-critical applications. Keywords: Mission-Critical Applications, Adversarial AI, Speech Recognition Systems.