 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimpsonsVQA: Enhancing Inquiry-Based Learning with a Tailored Dataset
Paper and Code
Oct 30, 2024
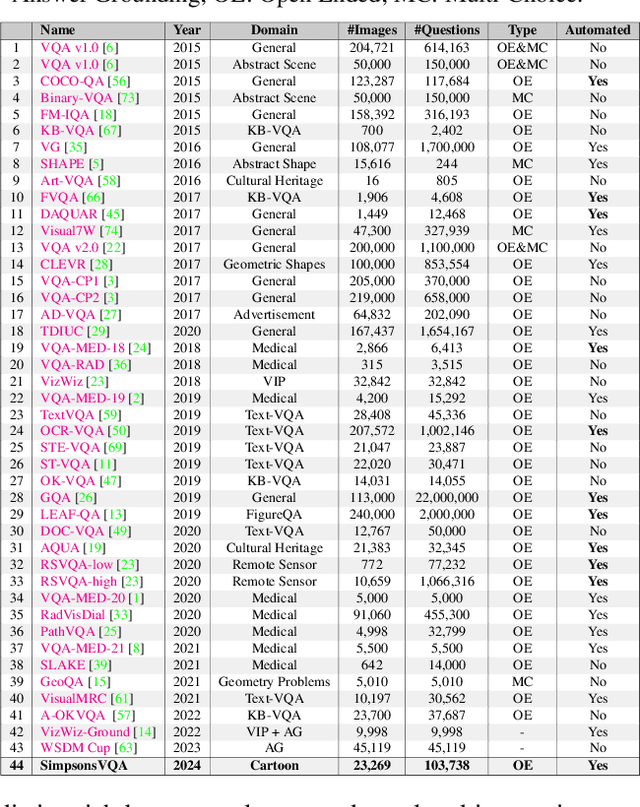

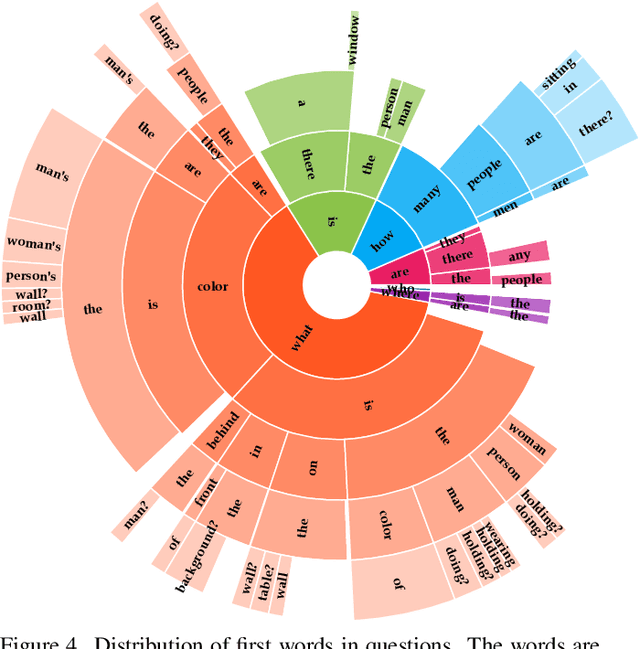
Visual Question Answering (VQA) has emerged as a promising area of research to develop AI-based systems for enabling interactive and immersive learning. Numerous VQA datasets have been introduced to facilitate various tasks, such as answering questions or identifying unanswerable ones. However, most of these datasets are constructed using real-world images, leaving the performance of existing models on cartoon images largely unexplored. Hence, in this paper, we present "SimpsonsVQA", a novel dataset for VQA derived from The Simpsons TV show, designed to promote inquiry-based learning. Our dataset is specifically designed to address not only the traditional VQA task but also to identify irrelevant questions related to images, as well as the reverse scenario where a user provides an answer to a question that the system must evaluate (e.g., as correct, incorrect, or ambiguous). It aims to cater to various visual applications, harnessing the visual content of "The Simpsons" to create engaging and informative interactive systems. SimpsonsVQA contains approximately 23K images, 166K QA pairs, and 500K judgments (https://simpsonsvqa.org). Our experiments show that current large vision-language models like ChatGPT4o underperform in zero-shot settings across all three tasks, highlighting the dataset's value for improving model performance on cartoon images. We anticipate that SimpsonsVQA will inspire further research, innovation, and advancements in inquiry-based learning VQA.