 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-aware Mamba for Crack Segmentation in Structures
Oct 25, 2024
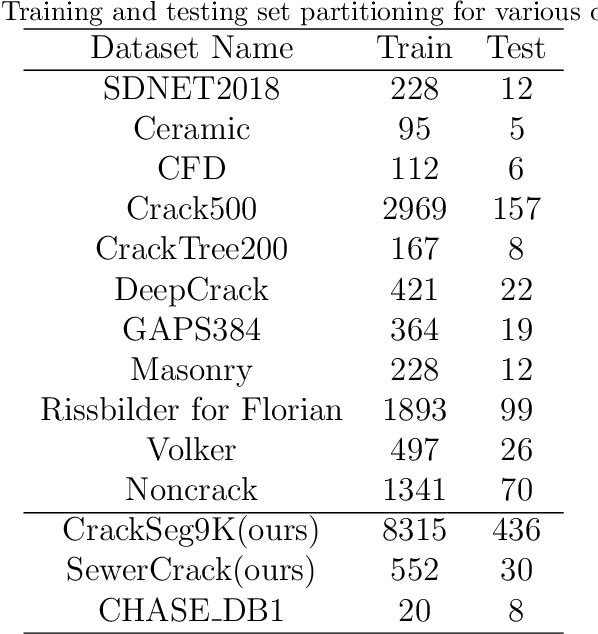
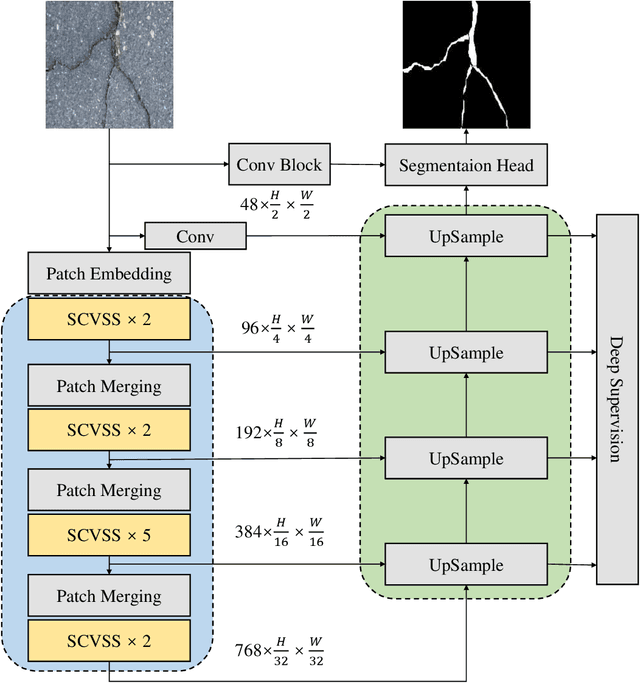
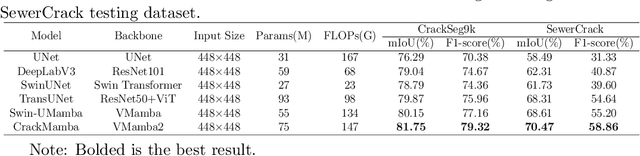
CrackMamba, a Mamba-based model, is designed for efficient and accurate crack segmentation for monitoring the structural health of infrastructure. Traditional Convolutional Neural Network (CNN) models struggle with limited receptive fields, and while Vision Transformers (ViT) improve segmentation accuracy, they are computationally intensive. CrackMamba addresses these challenges by utilizing the VMambaV2 with pre-trained ImageNet-1k weights as the encoder and a newly designed decoder for better performance. To handle the random and complex nature of crack development, a Snake Scan module is proposed to reshape crack feature sequences, enhancing feature extraction. Additionally, the three-branch Snake Conv VSS (SCVSS) block is proposed to target cracks more effectively. Experiments show that CrackMamba achieves state-of-the-art (SOTA) performance on the CrackSeg9k and SewerCrack datasets, and demonstrates competitive performance on the retinal vessel segmentation dataset CHASE\underline{~}DB1, highlighting its generalization capability. The code is publicly available at: {https://github.com/shengyu27/CrackMamba.}
Multi-label Sewer Pipe Defect Recognition with Mask Attention Feature Enhancement and Label Correlation Learning
Aug 01, 2024



The coexistence of multiple defect categories as well as the substantial class imbalance problem significantly impair the detection of sewer pipeline defects. To solve this problem, a multi-label pipe defect recognition method is proposed based on mask attention guided feature enhancement and label correlation learning. The proposed method can achieve current approximate state-of-the-art classification performance using just 1/16 of the Sewer-ML training dataset and exceeds the current best method by 11.87\% in terms of F2 metric on the full dataset, while also proving the superiority of the model. The major contribution of this study is the development of a more efficient model for identifying and locating multiple defects in sewer pipe images for a more accurate sewer pipeline condition assessment. Moreover, by employing class activation maps, our method can accurately pinpoint multiple defect categories in the image which demonstrates a strong model interpretability. Our code is available at \href{https://github.com/shengyu27/MA-Q2L}{\textcolor{black}{https://github.com/shengyu27/MA-Q2L.}