 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-aware Mamba for Crack Segmentation in Structures
Paper and Code

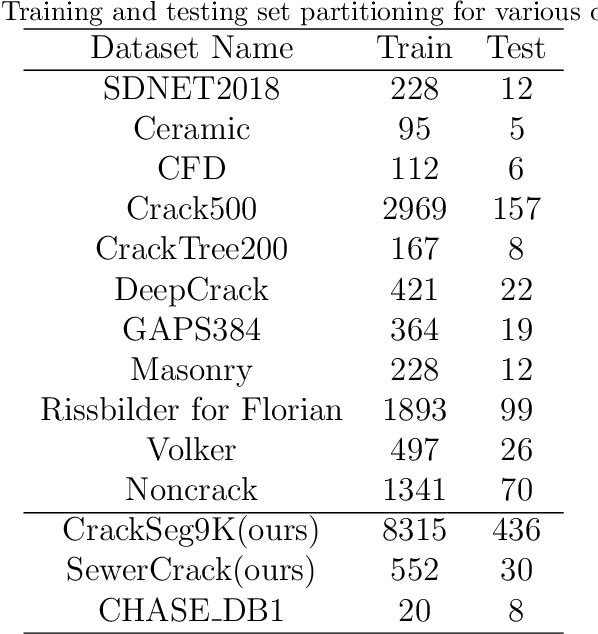
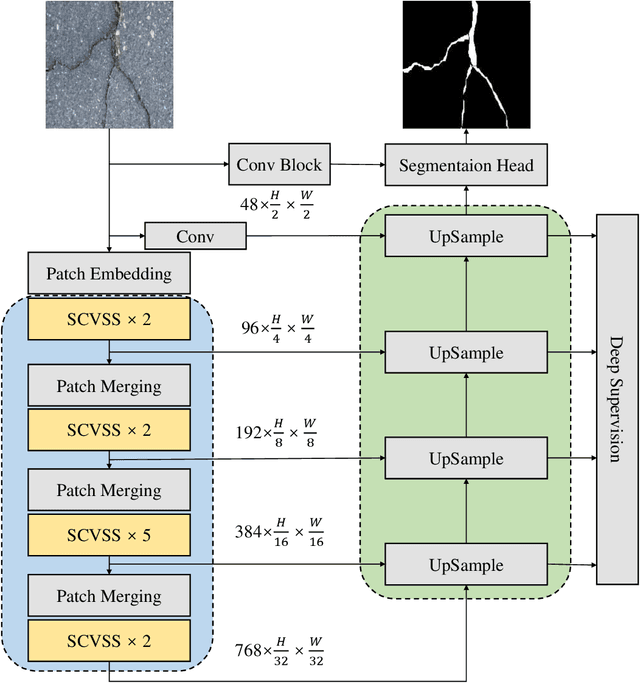
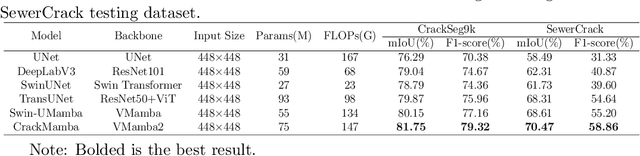
CrackMamba, a Mamba-based model, is designed for efficient and accurate crack segmentation for monitoring the structural health of infrastructure. Traditional Convolutional Neural Network (CNN) models struggle with limited receptive fields, and while Vision Transformers (ViT) improve segmentation accuracy, they are computationally intensive. CrackMamba addresses these challenges by utilizing the VMambaV2 with pre-trained ImageNet-1k weights as the encoder and a newly designed decoder for better performance. To handle the random and complex nature of crack development, a Snake Scan module is proposed to reshape crack feature sequences, enhancing feature extraction. Additionally, the three-branch Snake Conv VSS (SCVSS) block is proposed to target cracks more effectively. Experiments show that CrackMamba achieves state-of-the-art (SOTA) performance on the CrackSeg9k and SewerCrack datasets, and demonstrates competitive performance on the retinal vessel segmentation dataset CHASE\underline{~}DB1, highlighting its generalization capability. The code is publicly available at: {https://github.com/shengyu27/CrackMamba.}