 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMPlanner: Integrating Visual Language Models with Motion Planning
Jul 27, 2025Integrating large language models (LLMs) into autonomous driving motion planning has recently emerged as a promising direction, offering enhanced interpretability, better controllability, and improved generalization in rare and long-tail scenarios. However, existing methods often rely on abstracted perception or map-based inputs, missing crucial visual context, such as fine-grained road cues, accident aftermath, or unexpected obstacles, which are essential for robust decision-making in complex driving environments. To bridge this gap, we propose VLMPlanner, a hybrid framework that combines a learning-based real-time planner with a vision-language model (VLM) capable of reasoning over raw images. The VLM processes multi-view images to capture rich, detailed visual information and leverages its common-sense reasoning capabilities to guide the real-time planner in generating robust and safe trajectories. Furthermore, we develop the Context-Adaptive Inference Gate (CAI-Gate) mechanism that enables the VLM to mimic human driving behavior by dynamically adjusting its inference frequency based on scene complexity, thereby achieving an optimal balance between planning performance and computational efficiency. We evaluate our approach on the large-scale, challenging nuPlan benchmark, with comprehensive experimental results demonstrating superior planning performance in scenarios with intricate road conditions and dynamic elements. Code will be available.
ElectricSight: 3D Hazard Monitoring for Power Lines Using Low-Cost Sensors
May 10, 2025Protecting power transmission lines from potential hazards involves critical tasks, one of which is the accurate measurement of distances between power lines and potential threats, such as large cranes. The challenge with this task is that the current sensor-based methods face challenges in balancing accuracy and cost in distance measurement. A common practice is to install cameras on transmission towers, which, however, struggle to measure true 3D distances due to the lack of depth information. Although 3D lasers can provide accurate depth data, their high cost makes large-scale deployment impractical. To address this challenge, we present ElectricSight, a system designed for 3D distance measurement and monitoring of potential hazards to power transmission lines. This work's key innovations lie in both the overall system framework and a monocular depth estimation method. Specifically, the system framework combines real-time images with environmental point cloud priors, enabling cost-effective and precise 3D distance measurements. As a core component of the system, the monocular depth estimation method enhances the performance by integrating 3D point cloud data into image-based estimates, improving both the accuracy and reliability of the system. To assess ElectricSight's performance, we conducted tests with data from a real-world power transmission scenario. The experimental results demonstrate that ElectricSight achieves an average accuracy of 1.08 m for distance measurements and an early warning accuracy of 92%.
GraspCoT: Integrating Physical Property Reasoning for 6-DoF Grasping under Flexible Language Instructions
Mar 20, 2025Flexible instruction-guided 6-DoF grasping is a significant yet challenging task for real-world robotic systems. Existing methods utilize the contextual understanding capabilities of the large language models (LLMs) to establish mappings between expressions and targets, allowing robots to comprehend users' intentions in the instructions. However, the LLM's knowledge about objects' physical properties remains underexplored despite its tight relevance to grasping. In this work, we propose GraspCoT, a 6-DoF grasp detection framework that integrates a Chain-of-Thought (CoT) reasoning mechanism oriented to physical properties, guided by auxiliary question-answering (QA) tasks. Particularly, we design a set of QA templates to enable hierarchical reasoning that includes three stages: target parsing, physical property analysis, and grasp action selection. Moreover, GraspCoT presents a unified multimodal LLM architecture, which encodes multi-view observations of 3D scenes into 3D-aware visual tokens, and then jointly embeds these visual tokens with CoT-derived textual tokens within LLMs to generate grasp pose predictions. Furthermore, we present IntentGrasp, a large-scale benchmark that fills the gap in public datasets for multi-object grasp detection under diverse and indirect verbal commands. Extensive experiments on IntentGrasp demonstrate the superiority of our method, with additional validation in real-world robotic applications confirming its practicality. Codes and data will be released.
RaCFormer: Towards High-Quality 3D Object Detection via Query-based Radar-Camera Fusion
Dec 17, 2024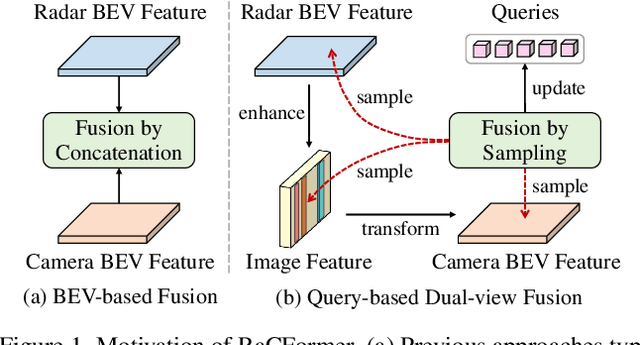
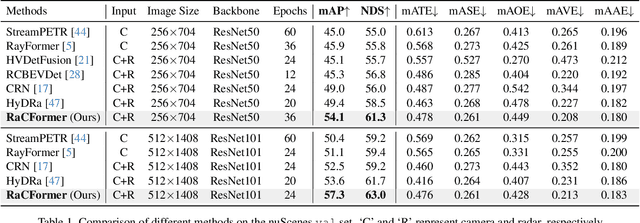
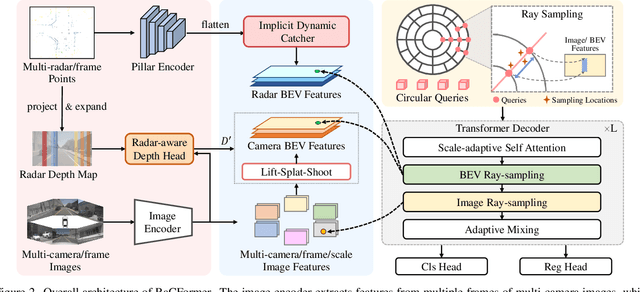
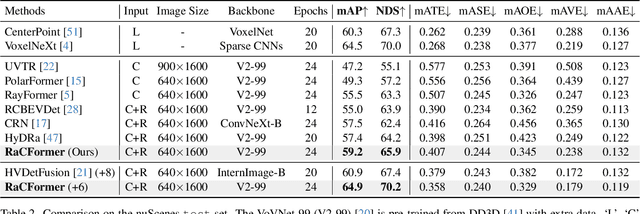
We propose Radar-Camera fusion transformer (RaCFormer) to boost the accuracy of 3D object detection by the following insight. The Radar-Camera fusion in outdoor 3D scene perception is capped by the image-to-BEV transformation--if the depth of pixels is not accurately estimated, the naive combination of BEV features actually integrates unaligned visual content. To avoid this problem, we propose a query-based framework that enables adaptively sample instance-relevant features from both the BEV and the original image view. Furthermore, we enhance system performance by two key designs: optimizing query initialization and strengthening the representational capacity of BEV. For the former, we introduce an adaptive circular distribution in polar coordinates to refine the initialization of object queries, allowing for a distance-based adjustment of query density. For the latter, we initially incorporate a radar-guided depth head to refine the transformation from image view to BEV. Subsequently, we focus on leveraging the Doppler effect of radar and introduce an implicit dynamic catcher to capture the temporal elements within the BEV. Extensive experiments on nuScenes and View-of-Delft (VoD) datasets validate the merits of our design. Remarkably, our method achieves superior results of 64.9% mAP and 70.2% NDS on nuScenes, even outperforming several LiDAR-based detectors. RaCFormer also secures the 1st ranking on the VoD dataset. The code will be released.
CELLmap: Enhancing LiDAR SLAM through Elastic and Lightweight Spherical Map Representation
Sep 29, 2024



SLAM is a fundamental capability of unmanned systems, with LiDAR-based SLAM gaining widespread adoption due to its high precision. Current SLAM systems can achieve centimeter-level accuracy within a short period. However, there are still several challenges when dealing with largescale mapping tasks including significant storage requirements and difficulty of reusing the constructed maps. To address this, we first design an elastic and lightweight map representation called CELLmap, composed of several CELLs, each representing the local map at the corresponding location. Then, we design a general backend including CELL-based bidirectional registration module and loop closure detection module to improve global map consistency. Our experiments have demonstrated that CELLmap can represent the precise geometric structure of large-scale maps of KITTI dataset using only about 60 MB. Additionally, our general backend achieves up to a 26.88% improvement over various LiDAR odometry methods.
LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion
Sep 21, 2024



Multi-modal systems enhance performance in autonomous driving but face inefficiencies due to indiscriminate processing within each modality. Additionally, the independent feature learning of each modality lacks interaction, which results in extracted features that do not possess the complementary characteristics. These issue increases the cost of fusing redundant information across modalities. To address these challenges, we propose targeting driving-relevant elements, which reduces the volume of LiDAR features while preserving critical information. This approach enhances lane level interaction between the image and LiDAR branches, allowing for the extraction and fusion of their respective advantageous features. Building upon the camera-only framework PHP, we introduce the Lane-level camera-LiDAR Fusion Planning (LFP) method, which balances efficiency with performance by using lanes as the unit for sensor fusion. Specifically, we design three modules to enhance efficiency and performance. For efficiency, we propose an image-guided coarse lane prior generation module that forecasts the region of interest (ROI) for lanes and assigns a confidence score, guiding LiDAR processing. The LiDAR feature extraction modules leverages lane-aware priors from the image branch to guide sampling for pillar, retaining essential pillars. For performance, the lane-level cross-modal query integration and feature enhancement module uses confidence score from ROI to combine low-confidence image queries with LiDAR queries, extracting complementary depth features. These features enhance the low-confidence image features, compensating for the lack of depth. Experiments on the Carla benchmarks show that our method achieves state-of-the-art performance in both driving score and infraction score, with maximum improvement of 15% and 14% over existing algorithms, respectively, maintaining high frame rate of 19.27 FPS.
RayFormer: Improving Query-Based Multi-Camera 3D Object Detection via Ray-Centric Strategies
Jul 27, 2024



The recent advances in query-based multi-camera 3D object detection are featured by initializing object queries in the 3D space, and then sampling features from perspective-view images to perform multi-round query refinement. In such a framework, query points near the same camera ray are likely to sample similar features from very close pixels, resulting in ambiguous query features and degraded detection accuracy. To this end, we introduce RayFormer, a camera-ray-inspired query-based 3D object detector that aligns the initialization and feature extraction of object queries with the optical characteristics of cameras. Specifically, RayFormer transforms perspective-view image features into bird's eye view (BEV) via the lift-splat-shoot method and segments the BEV map to sectors based on the camera rays. Object queries are uniformly and sparsely initialized along each camera ray, facilitating the projection of different queries onto different areas in the image to extract distinct features. Besides, we leverage the instance information of images to supplement the uniformly initialized object queries by further involving additional queries along the ray from 2D object detection boxes. To extract unique object-level features that cater to distinct queries, we design a ray sampling method that suitably organizes the distribution of feature sampling points on both images and bird's eye view. Extensive experiments are conducted on the nuScenes dataset to validate our proposed ray-inspired model design. The proposed RayFormer achieves 55.5% mAP and 63.3% NDS, respectively. Our codes will be made available.
Perception Helps Planning: Facilitating Multi-Stage Lane-Level Integration via Double-Edge Structures
Jul 16, 2024



When planning for autonomous driving, it is crucial to consider essential traffic elements such as lanes, intersections, traffic regulations, and dynamic agents. However, they are often overlooked by the traditional end-to-end planning methods, likely leading to inefficiencies and non-compliance with traffic regulations. In this work, we endeavor to integrate the perception of these elements into the planning task. To this end, we propose Perception Helps Planning (PHP), a novel framework that reconciles lane-level planning with perception. This integration ensures that planning is inherently aligned with traffic constraints, thus facilitating safe and efficient driving. Specifically, PHP focuses on both edges of a lane for planning and perception purposes, taking into consideration the 3D positions of both lane edges and attributes for lane intersections, lane directions, lane occupancy, and planning. In the algorithmic design, the process begins with the transformer encoding multi-camera images to extract the above features and predicting lane-level perception results. Next, the hierarchical feature early fusion module refines the features for predicting planning attributes. Finally, the double-edge interpreter utilizes a late-fusion process specifically designed to integrate lane-level perception and planning information, culminating in the generation of vehicle control signals. Experiments on three Carla benchmarks show significant improvements in driving score of 27.20%, 33.47%, and 15.54% over existing algorithms, respectively, achieving the state-of-the-art performance, with the system operating up to 22.57 FPS.
Rotation Initialization and Stepwise Refinement for Universal LiDAR Calibration
May 09, 2024



Autonomous systems often employ multiple LiDARs to leverage the integrated advantages, enhancing perception and robustness. The most critical prerequisite under this setting is the estimating the extrinsic between each LiDAR, i.e., calibration. Despite the exciting progress in multi-LiDAR calibration efforts, a universal, sensor-agnostic calibration method remains elusive. According to the coarse-to-fine framework, we first design a spherical descriptor TERRA for 3-DoF rotation initialization with no prior knowledge. To further optimize, we present JEEP for the joint estimation of extrinsic and pose, integrating geometric and motion information to overcome factors affecting the point cloud registration. Finally, the LiDAR poses optimized by the hierarchical optimization module are input to time synchronization module to produce the ultimate calibration results, including the time offset. To verify the effectiveness, we conduct extensive experiments on eight datasets, where 16 diverse types of LiDARs in total and dozens of calibration tasks are tested. In the challenging tasks, the calibration errors can still be controlled within 5cm and 1{\deg} with a high success rate.
EdgeCalib: Multi-Frame Weighted Edge Features for Automatic Targetless LiDAR-Camera Calibration
Oct 25, 2023In multimodal perception systems, achieving precise extrinsic calibration between LiDAR and camera is of critical importance. Previous calibration methods often required specific targets or manual adjustments, making them both labor-intensive and costly. Online calibration methods based on features have been proposed, but these methods encounter challenges such as imprecise feature extraction, unreliable cross-modality associations, and high scene-specific requirements. To address this, we introduce an edge-based approach for automatic online calibration of LiDAR and cameras in real-world scenarios. The edge features, which are prevalent in various environments, are aligned in both images and point clouds to determine the extrinsic parameters. Specifically, stable and robust image edge features are extracted using a SAM-based method and the edge features extracted from the point cloud are weighted through a multi-frame weighting strategy for feature filtering. Finally, accurate extrinsic parameters are optimized based on edge correspondence constraints. We conducted evaluations on both the KITTI dataset and our dataset. The results show a state-of-the-art rotation accuracy of 0.086{\deg} and a translation accuracy of 0.977 cm, outperforming existing edge-based calibration methods in both precision and robustness.