 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$P^{3}O$: Transferring Visual Representations for Reinforcement Learning via Prompting
Paper and Code
Mar 27, 2023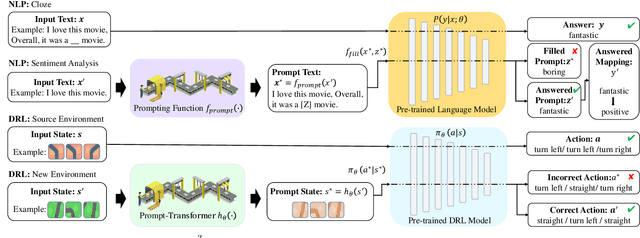
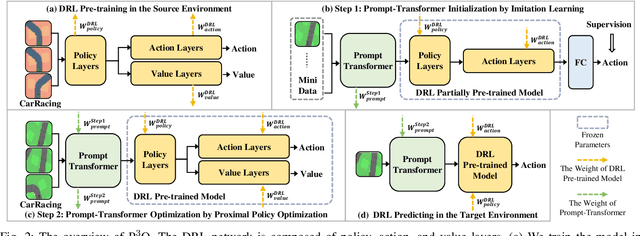
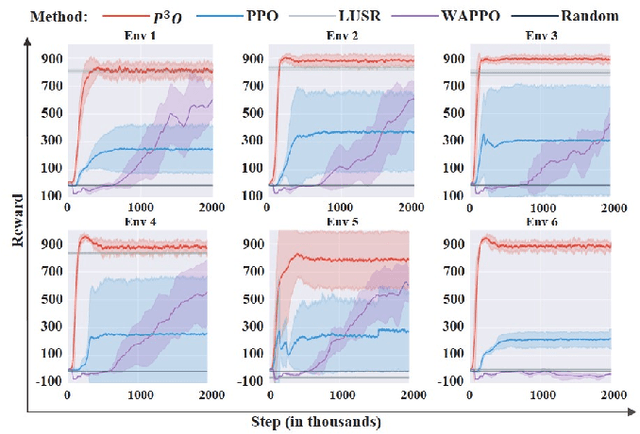
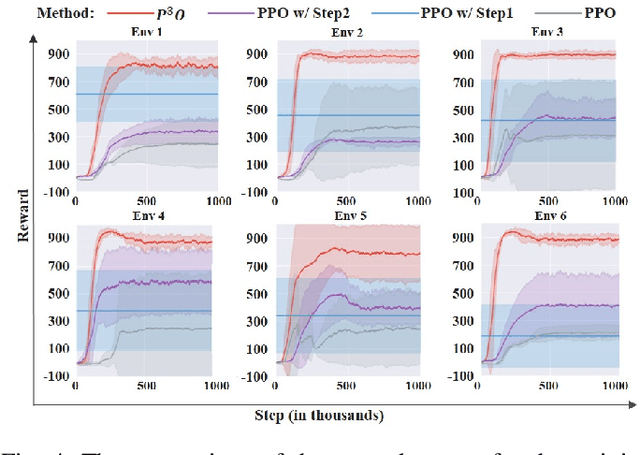
It is important for deep reinforcement learning (DRL) algorithms to transfer their learned policies to new environments that have different visual inputs. In this paper, we introduce Prompt based Proximal Policy Optimization ($P^{3}O$), a three-stage DRL algorithm that transfers visual representations from a target to a source environment by applying prompting. The process of $P^{3}O$ consists of three stages: pre-training, prompting, and predicting. In particular, we specify a prompt-transformer for representation conversion and propose a two-step training process to train the prompt-transformer for the target environment, while the rest of the DRL pipeline remains unchanged. We implement $P^{3}O$ and evaluate it on the OpenAI CarRacing video game. The experimental results show that $P^{3}O$ outperforms the state-of-the-art visual transferring schemes. In particular, $P^{3}O$ allows the learned policies to perform well in environments with different visual inputs, which is much more effective than retraining the policies in these environments.