 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Robust Multi-Agent Learning by Adaptable Auxiliary Multi-Agent Adversary Generation
May 09, 2023Communication can promote coordination in cooperative Multi-Agent Reinforcement Learning (MARL). Nowadays, existing works mainly focus on improving the communication efficiency of agents, neglecting that real-world communication is much more challenging as there may exist noise or potential attackers. Thus the robustness of the communication-based policies becomes an emergent and severe issue that needs more exploration. In this paper, we posit that the ego system trained with auxiliary adversaries may handle this limitation and propose an adaptable method of Multi-Agent Auxiliary Adversaries Generation for robust Communication, dubbed MA3C, to obtain a robust communication-based policy. In specific, we introduce a novel message-attacking approach that models the learning of the auxiliary attacker as a cooperative problem under a shared goal to minimize the coordination ability of the ego system, with which every information channel may suffer from distinct message attacks. Furthermore, as naive adversarial training may impede the generalization ability of the ego system, we design an attacker population generation approach based on evolutionary learning. Finally, the ego system is paired with an attacker population and then alternatively trained against the continuously evolving attackers to improve its robustness, meaning that both the ego system and the attackers are adaptable. Extensive experiments on multiple benchmarks indicate that our proposed MA3C provides comparable or better robustness and generalization ability than other baselines.
FHHOP: A Factored Hybrid Heuristic Online Planning Algorithm for Large POMDPs
Oct 16, 2012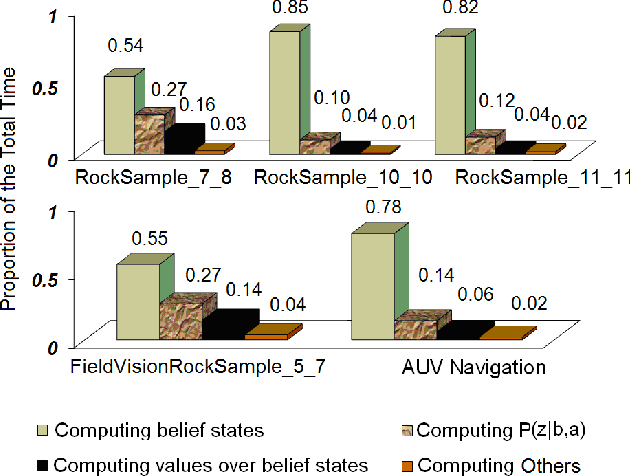
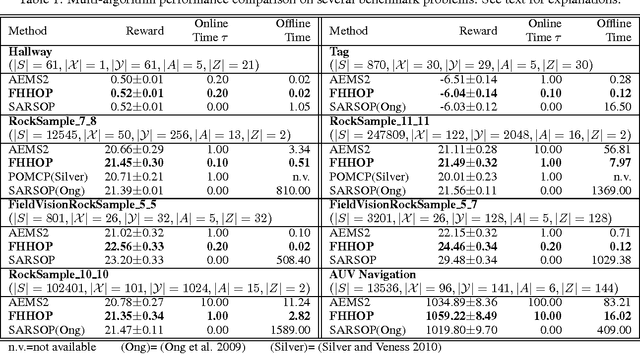


Planning in partially observable Markov decision processes (POMDPs) remains a challenging topic in the artificial intelligence community, in spite of recent impressive progress in approximation techniques. Previous research has indicated that online planning approaches are promising in handling large-scale POMDP domains efficiently as they make decisions "on demand" instead of proactively for the entire state space. We present a Factored Hybrid Heuristic Online Planning (FHHOP) algorithm for large POMDPs. FHHOP gets its power by combining a novel hybrid heuristic search strategy with a recently developed factored state representation. On several benchmark problems, FHHOP substantially outperformed state-of-the-art online heuristic search approaches in terms of both scalability and quality.