 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-ViGU: Towards Unified Video Generation and Understanding via A Diffusion-Based Video Generator
Apr 09, 2026Unified multimodal models integrating visual understanding and generation face a fundamental challenge: visual generation incurs substantially higher computational costs than understanding, particularly for video. This imbalance motivates us to invert the conventional paradigm: rather than extending understanding-centric MLLMs to support generation, we propose Uni-ViGU, a framework that unifies video generation and understanding by extending a video generator as the foundation. We introduce a unified flow method that performs continuous flow matching for video and discrete flow matching for text within a single process, enabling coherent multimodal generation. We further propose a modality-driven MoE-based framework that augments Transformer blocks with lightweight layers for text generation while preserving generative priors. To repurpose generation knowledge for understanding, we design a bidirectional training mechanism with two stages: Knowledge Recall reconstructs input prompts to leverage learned text-video correspondences, while Capability Refinement fine-tunes on detailed captions to establish discriminative shared representations. Experiments demonstrate that Uni-ViGU achieves competitive performance on both video generation and understanding, validating generation-centric architectures as a scalable path toward unified multimodal intelligence. Project Page and Code: https://fr0zencrane.github.io/uni-vigu-page/.
Omni-Video 2: Scaling MLLM-Conditioned Diffusion for Unified Video Generation and Editing
Feb 09, 2026We present Omni-Video 2, a scalable and computationally efficient model that connects pretrained multimodal large-language models (MLLMs) with video diffusion models for unified video generation and editing. Our key idea is to exploit the understanding and reasoning capabilities of MLLMs to produce explicit target captions to interpret user instructions. In this way, the rich contextual representations from the understanding model are directly used to guide the generative process, thereby improving performance on complex and compositional editing. Moreover, a lightweight adapter is developed to inject multimodal conditional tokens into pretrained text-to-video diffusion models, allowing maximum reuse of their powerful generative priors in a parameter-efficient manner. Benefiting from these designs, we scale up Omni-Video 2 to a 14B video diffusion model on meticulously curated training data with quality, supporting high quality text-to-video generation and various video editing tasks such as object removal, addition, background change, complex motion editing, \emph{etc.} We evaluate the performance of Omni-Video 2 on the FiVE benchmark for fine-grained video editing and the VBench benchmark for text-to-video generation. The results demonstrate its superior ability to follow complex compositional instructions in video editing, while also achieving competitive or superior quality in video generation tasks.
Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision
Aug 07, 2025
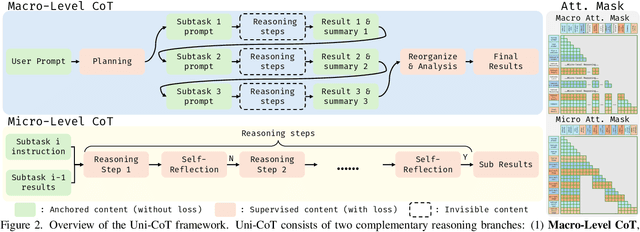

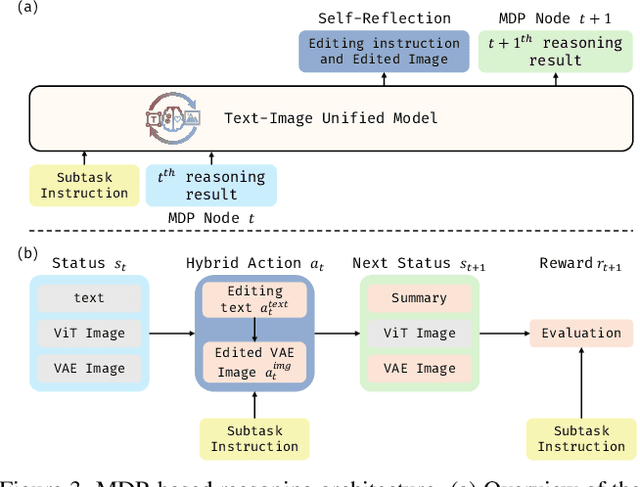
Chain-of-Thought (CoT) reasoning has been widely adopted to enhance Large Language Models (LLMs) by decomposing complex tasks into simpler, sequential subtasks. However, extending CoT to vision-language reasoning tasks remains challenging, as it often requires interpreting transitions of visual states to support reasoning. Existing methods often struggle with this due to limited capacity of modeling visual state transitions or incoherent visual trajectories caused by fragmented architectures. To overcome these limitations, we propose Uni-CoT, a Unified Chain-of-Thought framework that enables coherent and grounded multimodal reasoning within a single unified model. The key idea is to leverage a model capable of both image understanding and generation to reason over visual content and model evolving visual states. However, empowering a unified model to achieve that is non-trivial, given the high computational cost and the burden of training. To address this, Uni-CoT introduces a novel two-level reasoning paradigm: A Macro-Level CoT for high-level task planning and A Micro-Level CoT for subtask execution. This design significantly reduces the computational overhead. Furthermore, we introduce a structured training paradigm that combines interleaved image-text supervision for macro-level CoT with multi-task objectives for micro-level CoT. Together, these innovations allow Uni-CoT to perform scalable and coherent multi-modal reasoning. Furthermore, thanks to our design, all experiments can be efficiently completed using only 8 A100 GPUs with 80GB VRAM each. Experimental results on reasoning-driven image generation benchmark (WISE) and editing benchmarks (RISE and KRIS) indicates that Uni-CoT demonstrates SOTA performance and strong generalization, establishing Uni-CoT as a promising solution for multi-modal reasoning. Project Page and Code: https://sais-fuxi.github.io/projects/uni-cot/
Omni-Video: Democratizing Unified Video Understanding and Generation
Jul 09, 2025Notable breakthroughs in unified understanding and generation modeling have led to remarkable advancements in image understanding, reasoning, production and editing, yet current foundational models predominantly focus on processing images, creating a gap in the development of unified models for video understanding and generation. This report presents Omni-Video, an efficient and effective unified framework for video understanding, generation, as well as instruction-based editing. Our key insight is to teach existing multimodal large language models (MLLMs) to produce continuous visual clues that are used as the input of diffusion decoders, which produce high-quality videos conditioned on these visual clues. To fully unlock the potential of our system for unified video modeling, we integrate several technical improvements: 1) a lightweight architectural design that respectively attaches a vision head on the top of MLLMs and a adapter before the input of diffusion decoders, the former produce visual tokens for the latter, which adapts these visual tokens to the conditional space of diffusion decoders; and 2) an efficient multi-stage training scheme that facilitates a fast connection between MLLMs and diffusion decoders with limited data and computational resources. We empirically demonstrate that our model exhibits satisfactory generalization abilities across video generation, editing and understanding tasks.
Instance Temperature Knowledge Distillation
Jun 27, 2024



Knowledge distillation (KD) enhances the performance of a student network by allowing it to learn the knowledge transferred from a teacher network incrementally. Existing methods dynamically adjust the temperature to enable the student network to adapt to the varying learning difficulties at different learning stages of KD. KD is a continuous process, but when adjusting the temperature, these methods consider only the immediate benefits of the operation in the current learning phase and fail to take into account its future returns. To address this issue, we formulate the adjustment of temperature as a sequential decision-making task and propose a method based on reinforcement learning, termed RLKD. Importantly, we design a novel state representation to enable the agent to make more informed action (i.e. instance temperature adjustment). To handle the problem of delayed rewards in our method due to the KD setting, we explore an instance reward calibration approach. In addition,we devise an efficient exploration strategy that enables the agent to learn valuable instance temperature adjustment policy more efficiently. Our framework can serve as a plug-and-play technique to be inserted into various KD methods easily, and we validate its effectiveness on both image classification and object detection tasks. Our code is at https://github.com/Zhengbo-Zhang/ITKD
LAGA: Layered 3D Avatar Generation and Customization via Gaussian Splatting
May 21, 2024



Creating and customizing a 3D clothed avatar from textual descriptions is a critical and challenging task. Traditional methods often treat the human body and clothing as inseparable, limiting users' ability to freely mix and match garments. In response to this limitation, we present LAyered Gaussian Avatar (LAGA), a carefully designed framework enabling the creation of high-fidelity decomposable avatars with diverse garments. By decoupling garments from avatar, our framework empowers users to conviniently edit avatars at the garment level. Our approach begins by modeling the avatar using a set of Gaussian points organized in a layered structure, where each layer corresponds to a specific garment or the human body itself. To generate high-quality garments for each layer, we introduce a coarse-to-fine strategy for diverse garment generation and a novel dual-SDS loss function to maintain coherence between the generated garments and avatar components, including the human body and other garments. Moreover, we introduce three regularization losses to guide the movement of Gaussians for garment transfer, allowing garments to be freely transferred to various avatars. Extensive experimentation demonstrates that our approach surpasses existing methods in the generation of 3D clothed humans.
LLMs are Good Sign Language Translators
Apr 01, 2024

Sign Language Translation (SLT) is a challenging task that aims to translate sign videos into spoken language. Inspired by the strong translation capabilities of large language models (LLMs) that are trained on extensive multilingual text corpora, we aim to harness off-the-shelf LLMs to handle SLT. In this paper, we regularize the sign videos to embody linguistic characteristics of spoken language, and propose a novel SignLLM framework to transform sign videos into a language-like representation for improved readability by off-the-shelf LLMs. SignLLM comprises two key modules: (1) The Vector-Quantized Visual Sign module converts sign videos into a sequence of discrete character-level sign tokens, and (2) the Codebook Reconstruction and Alignment module converts these character-level tokens into word-level sign representations using an optimal transport formulation. A sign-text alignment loss further bridges the gap between sign and text tokens, enhancing semantic compatibility. We achieve state-of-the-art gloss-free results on two widely-used SLT benchmarks.
Distribution-Aligned Diffusion for Human Mesh Recovery
Sep 11, 2023



Recovering a 3D human mesh from a single RGB image is a challenging task due to depth ambiguity and self-occlusion, resulting in a high degree of uncertainty. Meanwhile, diffusion models have recently seen much success in generating high-quality outputs by progressively denoising noisy inputs. Inspired by their capability, we explore a diffusion-based approach for human mesh recovery, and propose a Human Mesh Diffusion (HMDiff) framework which frames mesh recovery as a reverse diffusion process. We also propose a Distribution Alignment Technique (DAT) that infuses prior distribution information into the mesh distribution diffusion process, and provides useful prior knowledge to facilitate the mesh recovery task. Our method achieves state-of-the-art performance on three widely used datasets. Project page: https://gongjia0208.github.io/HMDiff/.
System-status-aware Adaptive Network for Online Streaming Video Understanding
Apr 09, 2023Recent years have witnessed great progress in deep neural networks for real-time applications. However, most existing works do not explicitly consider the general case where the device's state and the available resources fluctuate over time, and none of them investigate or address the impact of varying computational resources for online video understanding tasks. This paper proposes a System-status-aware Adaptive Network (SAN) that considers the device's real-time state to provide high-quality predictions with low delay. Usage of our agent's policy improves efficiency and robustness to fluctuations of the system status. On two widely used video understanding tasks, SAN obtains state-of-the-art performance while constantly keeping processing delays low. Moreover, training such an agent on various types of hardware configurations is not easy as the labeled training data might not be available, or can be computationally prohibitive. To address this challenging problem, we propose a Meta Self-supervised Adaptation (MSA) method that adapts the agent's policy to new hardware configurations at test-time, allowing for easy deployment of the model onto other unseen hardware platforms.
DiffPose: Toward More Reliable 3D Pose Estimation
Nov 30, 2022



Monocular 3D human pose estimation is quite challenging due to the inherent ambiguity and occlusion, which often lead to high uncertainty and indeterminacy. On the other hand, diffusion models have recently emerged as an effective tool for generating high-quality images from noise. Inspired by their capability, we explore a novel pose estimation framework (DiffPose) that formulates 3D pose estimation as a reverse diffusion process. We incorporate novel designs into our DiffPose that facilitate the diffusion process for 3D pose estimation: a pose-specific initialization of pose uncertainty distributions, a Gaussian Mixture Model-based forward diffusion process, and a context-conditioned reverse diffusion process. Our proposed DiffPose significantly outperforms existing methods on the widely used pose estimation benchmarks Human3.6M and MPI-INF-3DHP.