 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyMFM6D: Symmetry-aware Multi-directional Fusion for Multi-View 6D Object Pose Estimation
Jul 01, 2023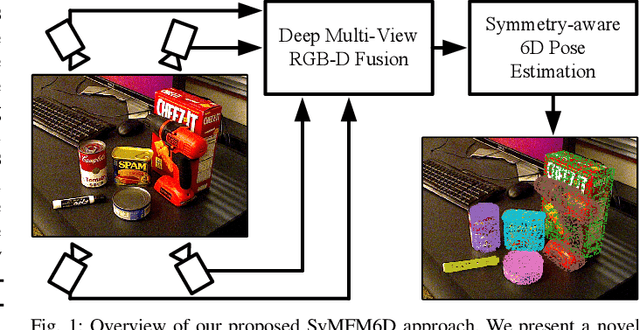
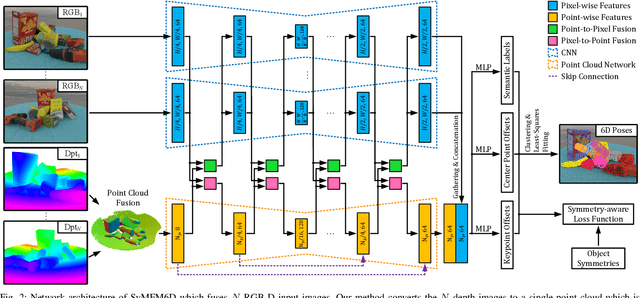
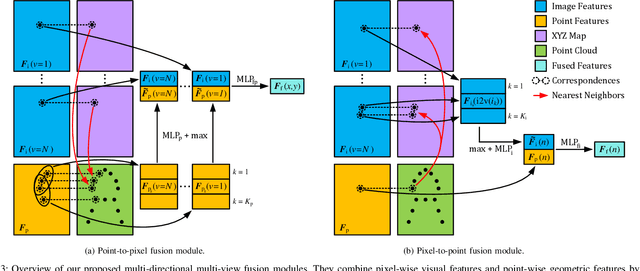
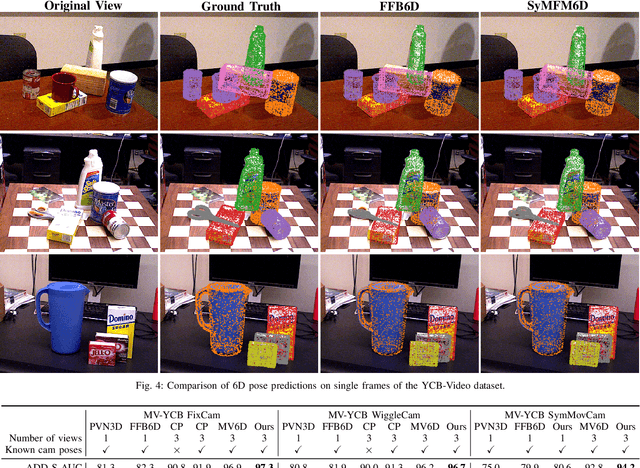
Detecting objects and estimating their 6D poses is essential for automated systems to interact safely with the environment. Most 6D pose estimators, however, rely on a single camera frame and suffer from occlusions and ambiguities due to object symmetries. We overcome this issue by presenting a novel symmetry-aware multi-view 6D pose estimator called SyMFM6D. Our approach efficiently fuses the RGB-D frames from multiple perspectives in a deep multi-directional fusion network and predicts predefined keypoints for all objects in the scene simultaneously. Based on the keypoints and an instance semantic segmentation, we efficiently compute the 6D poses by least-squares fitting. To address the ambiguity issues for symmetric objects, we propose a novel training procedure for symmetry-aware keypoint detection including a new objective function. Our SyMFM6D network significantly outperforms the state-of-the-art in both single-view and multi-view 6D pose estimation. We furthermore show the effectiveness of our symmetry-aware training procedure and demonstrate that our approach is robust towards inaccurate camera calibration and dynamic camera setups.
FusionVAE: A Deep Hierarchical Variational Autoencoder for RGB Image Fusion
Sep 22, 2022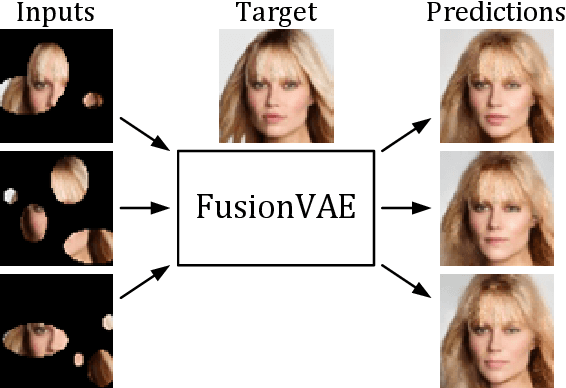
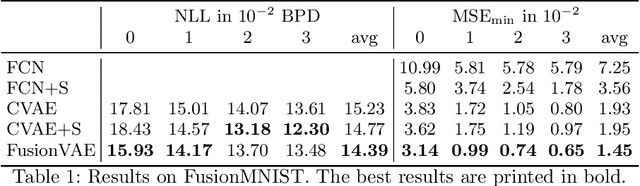
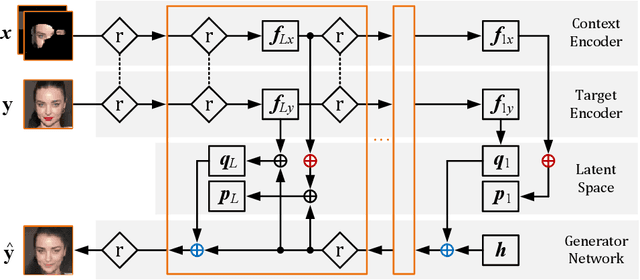
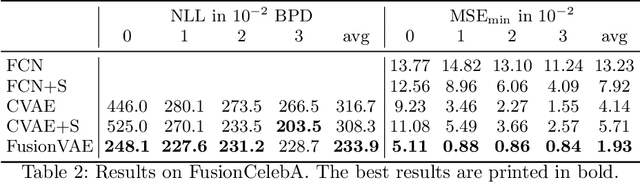
Sensor fusion can significantly improve the performance of many computer vision tasks. However, traditional fusion approaches are either not data-driven and cannot exploit prior knowledge nor find regularities in a given dataset or they are restricted to a single application. We overcome this shortcoming by presenting a novel deep hierarchical variational autoencoder called FusionVAE that can serve as a basis for many fusion tasks. Our approach is able to generate diverse image samples that are conditioned on multiple noisy, occluded, or only partially visible input images. We derive and optimize a variational lower bound for the conditional log-likelihood of FusionVAE. In order to assess the fusion capabilities of our model thoroughly, we created three novel datasets for image fusion based on popular computer vision datasets. In our experiments, we show that FusionVAE learns a representation of aggregated information that is relevant to fusion tasks. The results demonstrate that our approach outperforms traditional methods significantly. Furthermore, we present the advantages and disadvantages of different design choices.
MV6D: Multi-View 6D Pose Estimation on RGB-D Frames Using a Deep Point-wise Voting Network
Aug 01, 2022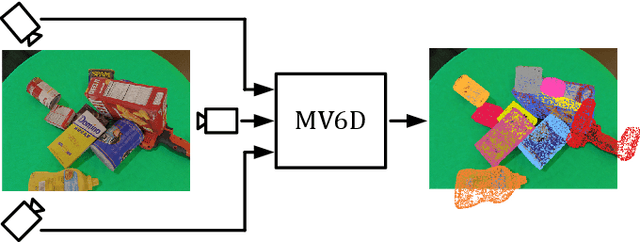
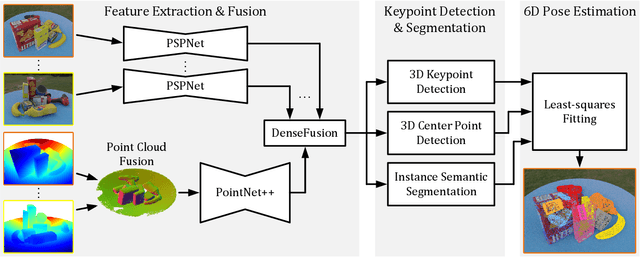
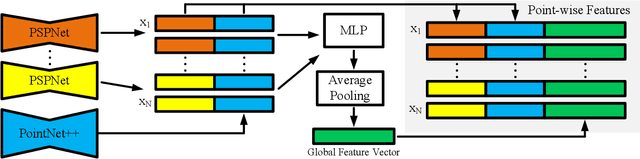
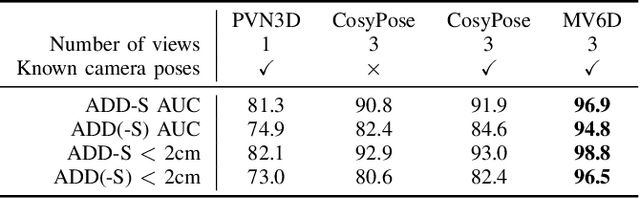
Estimating 6D poses of objects is an essential computer vision task. However, most conventional approaches rely on camera data from a single perspective and therefore suffer from occlusions. We overcome this issue with our novel multi-view 6D pose estimation method called MV6D which accurately predicts the 6D poses of all objects in a cluttered scene based on RGB-D images from multiple perspectives. We base our approach on the PVN3D network that uses a single RGB-D image to predict keypoints of the target objects. We extend this approach by using a combined point cloud from multiple views and fusing the images from each view with a DenseFusion layer. In contrast to current multi-view pose detection networks such as CosyPose, our MV6D can learn the fusion of multiple perspectives in an end-to-end manner and does not require multiple prediction stages or subsequent fine tuning of the prediction. Furthermore, we present three novel photorealistic datasets of cluttered scenes with heavy occlusions. All of them contain RGB-D images from multiple perspectives and the ground truth for instance semantic segmentation and 6D pose estimation. MV6D significantly outperforms the state-of-the-art in multi-view 6D pose estimation even in cases where the camera poses are known inaccurately. Furthermore, we show that our approach is robust towards dynamic camera setups and that its accuracy increases incrementally with an increasing number of perspectives.
Deep Multi-modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges
Feb 21, 2019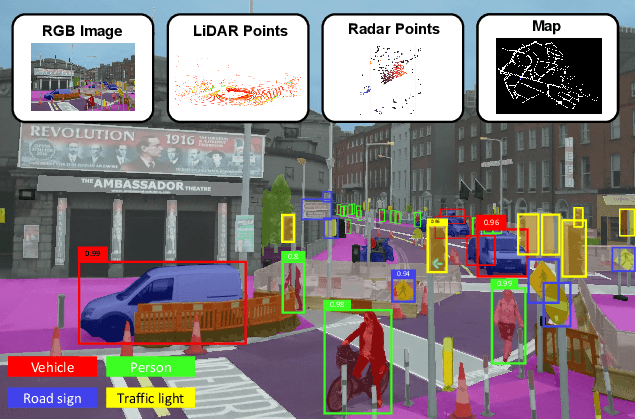

Recent advancements in the perception for autonomous driving are driven by deep learning. In order to achieve the robust and accurate scene understanding, autonomous vehicles are usually equipped with different sensors (e.g. cameras, LiDARs, Radars), and multiple sensing modalities can be fused to exploit their complementary properties. In this context, many methods have been proposed for deep multi-modal perception problems. However, there is no general guideline for network architecture design, and questions of "what to fuse", "when to fuse", and "how to fuse" remain open. This review paper attempts to systematically summarize methodologies and discuss challenges for deep multi-modal object detection and semantic segmentation in autonomous driving. To this end, we first provide an overview of on-board sensors on test vehicles, open datasets and the background information of object detection and semantic segmentation for the autonomous driving research. We then summarize the fusion methodologies and discuss challenges and open questions. In the appendix, we provide tables that summarize topics and methods. We also provide an interactive online platform to navigate each reference: https://multimodalperception.github.io.