 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV6D: Multi-View 6D Pose Estimation on RGB-D Frames Using a Deep Point-wise Voting Network
Paper and Code
Aug 01, 2022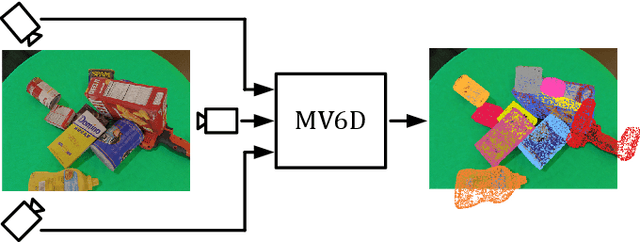
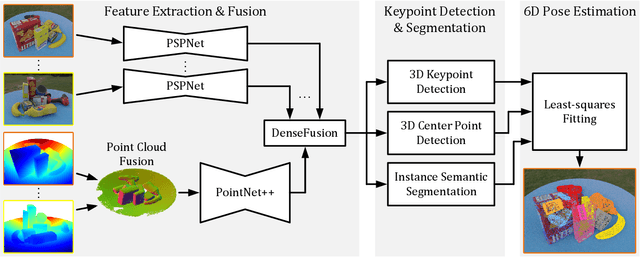
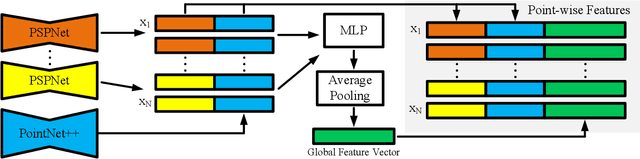
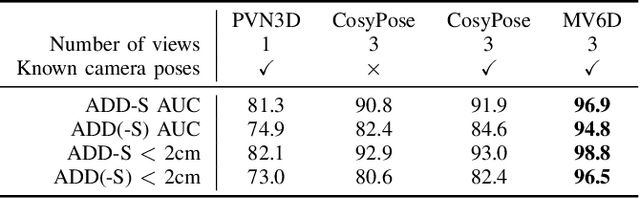
Estimating 6D poses of objects is an essential computer vision task. However, most conventional approaches rely on camera data from a single perspective and therefore suffer from occlusions. We overcome this issue with our novel multi-view 6D pose estimation method called MV6D which accurately predicts the 6D poses of all objects in a cluttered scene based on RGB-D images from multiple perspectives. We base our approach on the PVN3D network that uses a single RGB-D image to predict keypoints of the target objects. We extend this approach by using a combined point cloud from multiple views and fusing the images from each view with a DenseFusion layer. In contrast to current multi-view pose detection networks such as CosyPose, our MV6D can learn the fusion of multiple perspectives in an end-to-end manner and does not require multiple prediction stages or subsequent fine tuning of the prediction. Furthermore, we present three novel photorealistic datasets of cluttered scenes with heavy occlusions. All of them contain RGB-D images from multiple perspectives and the ground truth for instance semantic segmentation and 6D pose estimation. MV6D significantly outperforms the state-of-the-art in multi-view 6D pose estimation even in cases where the camera poses are known inaccurately. Furthermore, we show that our approach is robust towards dynamic camera setups and that its accuracy increases incrementally with an increasing number of perspectives.