 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Intent Queries for Motion Transformer-based Trajectory Prediction
Apr 22, 2025In autonomous driving, accurately predicting the movements of other traffic participants is crucial, as it significantly influences a vehicle's planning processes. Modern trajectory prediction models strive to interpret complex patterns and dependencies from agent and map data. The Motion Transformer (MTR) architecture and subsequent work define the most accurate methods in common benchmarks such as the Waymo Open Motion Benchmark. The MTR model employs pre-generated static intention points as initial goal points for trajectory prediction. However, the static nature of these points frequently leads to misalignment with map data in specific traffic scenarios, resulting in unfeasible or unrealistic goal points. Our research addresses this limitation by integrating scene-specific dynamic intention points into the MTR model. This adaptation of the MTR model was trained and evaluated on the Waymo Open Motion Dataset. Our findings demonstrate that incorporating dynamic intention points has a significant positive impact on trajectory prediction accuracy, especially for predictions over long time horizons. Furthermore, we analyze the impact on ground truth trajectories which are not compliant with the map data or are illegal maneuvers.
Towards Consistent and Explainable Motion Prediction using Heterogeneous Graph Attention
May 16, 2024In autonomous driving, accurately interpreting the movements of other road users and leveraging this knowledge to forecast future trajectories is crucial. This is typically achieved through the integration of map data and tracked trajectories of various agents. Numerous methodologies combine this information into a singular embedding for each agent, which is then utilized to predict future behavior. However, these approaches have a notable drawback in that they may lose exact location information during the encoding process. The encoding still includes general map information. However, the generation of valid and consistent trajectories is not guaranteed. This can cause the predicted trajectories to stray from the actual lanes. This paper introduces a new refinement module designed to project the predicted trajectories back onto the actual map, rectifying these discrepancies and leading towards more consistent predictions. This versatile module can be readily incorporated into a wide range of architectures. Additionally, we propose a novel scene encoder that handles all relations between agents and their environment in a single unified heterogeneous graph attention network. By analyzing the attention values on the different edges in this graph, we can gain unique insights into the neural network's inner workings leading towards a more explainable prediction.
MV6D: Multi-View 6D Pose Estimation on RGB-D Frames Using a Deep Point-wise Voting Network
Aug 01, 2022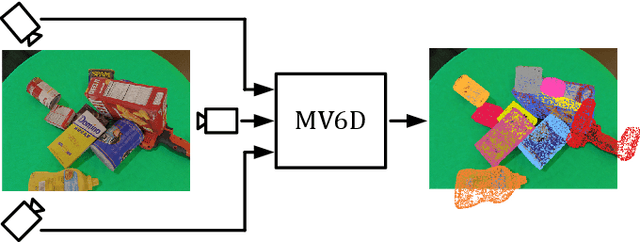
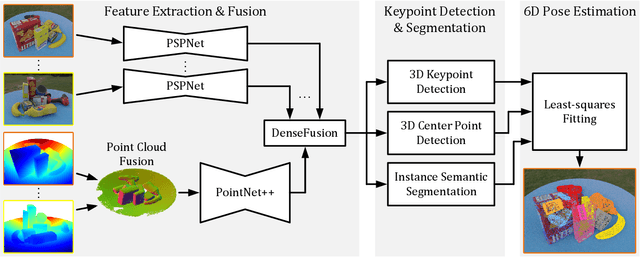
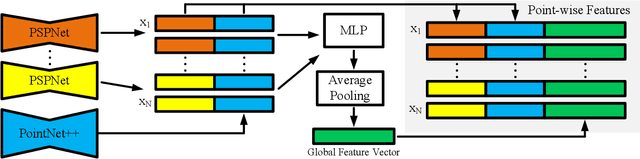
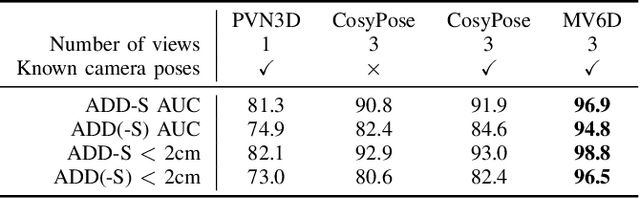
Estimating 6D poses of objects is an essential computer vision task. However, most conventional approaches rely on camera data from a single perspective and therefore suffer from occlusions. We overcome this issue with our novel multi-view 6D pose estimation method called MV6D which accurately predicts the 6D poses of all objects in a cluttered scene based on RGB-D images from multiple perspectives. We base our approach on the PVN3D network that uses a single RGB-D image to predict keypoints of the target objects. We extend this approach by using a combined point cloud from multiple views and fusing the images from each view with a DenseFusion layer. In contrast to current multi-view pose detection networks such as CosyPose, our MV6D can learn the fusion of multiple perspectives in an end-to-end manner and does not require multiple prediction stages or subsequent fine tuning of the prediction. Furthermore, we present three novel photorealistic datasets of cluttered scenes with heavy occlusions. All of them contain RGB-D images from multiple perspectives and the ground truth for instance semantic segmentation and 6D pose estimation. MV6D significantly outperforms the state-of-the-art in multi-view 6D pose estimation even in cases where the camera poses are known inaccurately. Furthermore, we show that our approach is robust towards dynamic camera setups and that its accuracy increases incrementally with an increasing number of perspectives.