 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Intent Queries for Motion Transformer-based Trajectory Prediction
Apr 22, 2025In autonomous driving, accurately predicting the movements of other traffic participants is crucial, as it significantly influences a vehicle's planning processes. Modern trajectory prediction models strive to interpret complex patterns and dependencies from agent and map data. The Motion Transformer (MTR) architecture and subsequent work define the most accurate methods in common benchmarks such as the Waymo Open Motion Benchmark. The MTR model employs pre-generated static intention points as initial goal points for trajectory prediction. However, the static nature of these points frequently leads to misalignment with map data in specific traffic scenarios, resulting in unfeasible or unrealistic goal points. Our research addresses this limitation by integrating scene-specific dynamic intention points into the MTR model. This adaptation of the MTR model was trained and evaluated on the Waymo Open Motion Dataset. Our findings demonstrate that incorporating dynamic intention points has a significant positive impact on trajectory prediction accuracy, especially for predictions over long time horizons. Furthermore, we analyze the impact on ground truth trajectories which are not compliant with the map data or are illegal maneuvers.
Enhancing Online Road Network Perception and Reasoning with Standard Definition Maps
Aug 01, 2024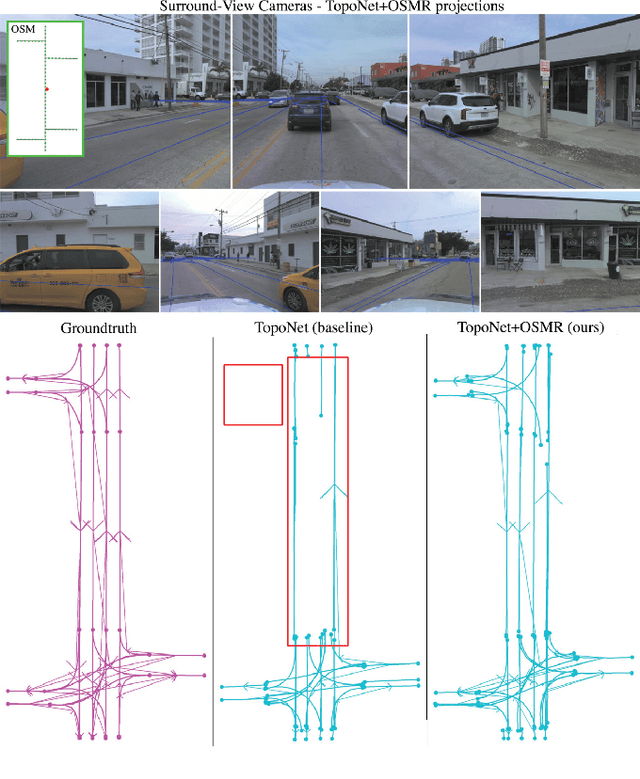
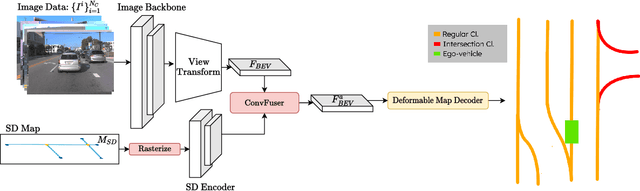
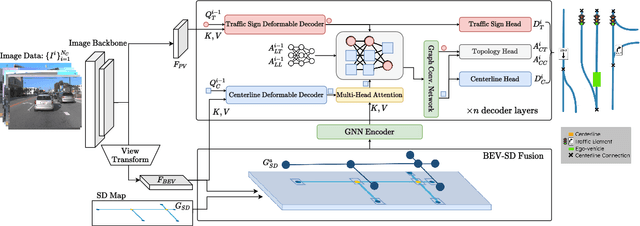
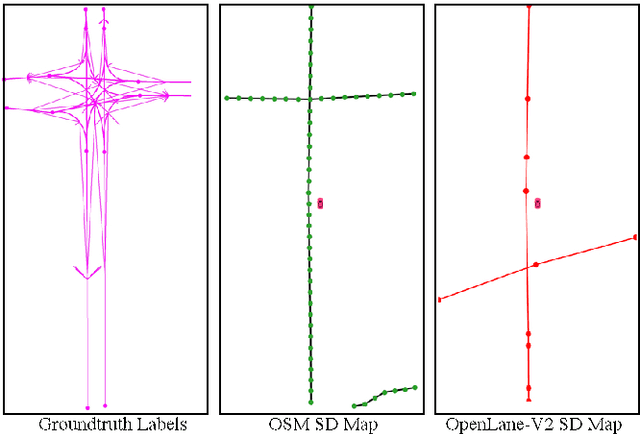
Autonomous driving for urban and highway driving applications often requires High Definition (HD) maps to generate a navigation plan. Nevertheless, various challenges arise when generating and maintaining HD maps at scale. While recent online mapping methods have started to emerge, their performance especially for longer ranges is limited by heavy occlusion in dynamic environments. With these considerations in mind, our work focuses on leveraging lightweight and scalable priors-Standard Definition (SD) maps-in the development of online vectorized HD map representations. We first examine the integration of prototypical rasterized SD map representations into various online mapping architectures. Furthermore, to identify lightweight strategies, we extend the OpenLane-V2 dataset with OpenStreetMaps and evaluate the benefits of graphical SD map representations. A key finding from designing SD map integration components is that SD map encoders are model agnostic and can be quickly adapted to new architectures that utilize bird's eye view (BEV) encoders. Our results show that making use of SD maps as priors for the online mapping task can significantly speed up convergence and boost the performance of the online centerline perception task by 30% (mAP). Furthermore, we show that the introduction of the SD maps leads to a reduction of the number of parameters in the perception and reasoning task by leveraging SD map graphs while improving the overall performance. Project Page: https://henryzhangzhy.github.io/sdhdmap/.
Towards Consistent and Explainable Motion Prediction using Heterogeneous Graph Attention
May 16, 2024In autonomous driving, accurately interpreting the movements of other road users and leveraging this knowledge to forecast future trajectories is crucial. This is typically achieved through the integration of map data and tracked trajectories of various agents. Numerous methodologies combine this information into a singular embedding for each agent, which is then utilized to predict future behavior. However, these approaches have a notable drawback in that they may lose exact location information during the encoding process. The encoding still includes general map information. However, the generation of valid and consistent trajectories is not guaranteed. This can cause the predicted trajectories to stray from the actual lanes. This paper introduces a new refinement module designed to project the predicted trajectories back onto the actual map, rectifying these discrepancies and leading towards more consistent predictions. This versatile module can be readily incorporated into a wide range of architectures. Additionally, we propose a novel scene encoder that handles all relations between agents and their environment in a single unified heterogeneous graph attention network. By analyzing the attention values on the different edges in this graph, we can gain unique insights into the neural network's inner workings leading towards a more explainable prediction.
Self-Supervised Representation Learning from Temporal Ordering of Automated Driving Sequences
Feb 17, 2023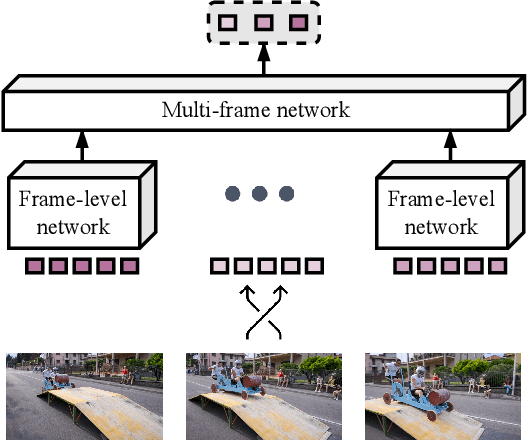



Self-supervised feature learning enables perception systems to benefit from the vast amount of raw data being recorded by vehicle fleets all over the world. However, their potential to learn dense representations from sequential data has been relatively unexplored. In this work, we propose TempO, a temporal ordering pretext task for pre-training region-level feature representations for perception tasks. We embed each frame by an unordered set of proposal feature vectors, a representation that is natural for instance-level perception architectures, and formulate the sequential ordering prediction by comparing similarities between sets of feature vectors in a transformer-based multi-frame architecture. Extensive evaluation in automated driving domains on the BDD100K and MOT17 datasets shows that our TempO approach outperforms existing self-supervised single-frame pre-training methods as well as supervised transfer learning initialization strategies on standard object detection and multi-object tracking benchmarks.