 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Representation Learning from Temporal Ordering of Automated Driving Sequences
Paper and Code
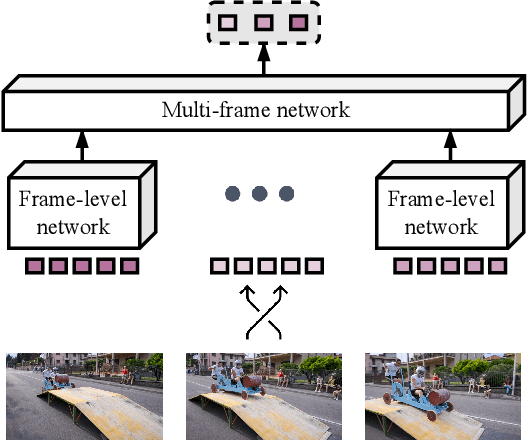



Self-supervised feature learning enables perception systems to benefit from the vast amount of raw data being recorded by vehicle fleets all over the world. However, their potential to learn dense representations from sequential data has been relatively unexplored. In this work, we propose TempO, a temporal ordering pretext task for pre-training region-level feature representations for perception tasks. We embed each frame by an unordered set of proposal feature vectors, a representation that is natural for instance-level perception architectures, and formulate the sequential ordering prediction by comparing similarities between sets of feature vectors in a transformer-based multi-frame architecture. Extensive evaluation in automated driving domains on the BDD100K and MOT17 datasets shows that our TempO approach outperforms existing self-supervised single-frame pre-training methods as well as supervised transfer learning initialization strategies on standard object detection and multi-object tracking benchmarks.