 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Point-Based Approach to Efficient LiDAR Multi-Task Perception
Apr 19, 2024Multi-task networks can potentially improve performance and computational efficiency compared to single-task networks, facilitating online deployment. However, current multi-task architectures in point cloud perception combine multiple task-specific point cloud representations, each requiring a separate feature encoder and making the network structures bulky and slow. We propose PAttFormer, an efficient multi-task architecture for joint semantic segmentation and object detection in point clouds that only relies on a point-based representation. The network builds on transformer-based feature encoders using neighborhood attention and grid-pooling and a query-based detection decoder using a novel 3D deformable-attention detection head design. Unlike other LiDAR-based multi-task architectures, our proposed PAttFormer does not require separate feature encoders for multiple task-specific point cloud representations, resulting in a network that is 3x smaller and 1.4x faster while achieving competitive performance on the nuScenes and KITTI benchmarks for autonomous driving perception. Our extensive evaluations show substantial gains from multi-task learning, improving LiDAR semantic segmentation by +1.7% in mIou and 3D object detection by +1.7% in mAP on the nuScenes benchmark compared to the single-task models.
Self-Supervised Multi-Object Tracking From Consistency Across Timescales
Apr 25, 2023



Self-supervised multi-object trackers have the potential to leverage the vast amounts of raw data recorded worldwide. However, they still fall short in re-identification accuracy compared to their supervised counterparts. We hypothesize that this deficiency results from restricting self-supervised objectives to single frames or frame pairs. Such designs lack sufficient visual appearance variations during training to learn consistent re-identification features. Therefore, we propose a training objective that learns re-identification features over a sequence of frames by enforcing consistent association scores across short and long timescales. Extensive evaluations on the BDD100K and MOT17 benchmarks demonstrate that our learned ReID features significantly reduce ID switches compared to other self-supervised methods, setting the new state of the art for self-supervised multi-object tracking and even performing on par with supervised methods on the BDD100k benchmark.
Self-Supervised Representation Learning from Temporal Ordering of Automated Driving Sequences
Feb 17, 2023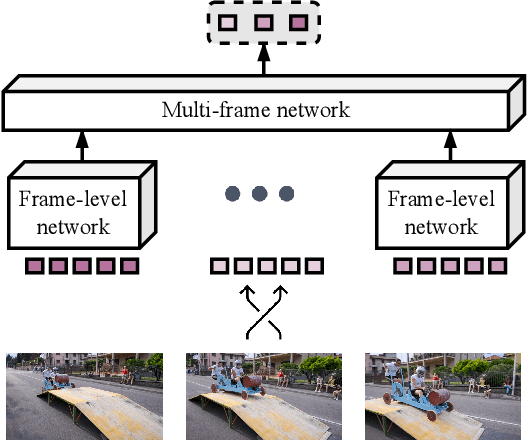



Self-supervised feature learning enables perception systems to benefit from the vast amount of raw data being recorded by vehicle fleets all over the world. However, their potential to learn dense representations from sequential data has been relatively unexplored. In this work, we propose TempO, a temporal ordering pretext task for pre-training region-level feature representations for perception tasks. We embed each frame by an unordered set of proposal feature vectors, a representation that is natural for instance-level perception architectures, and formulate the sequential ordering prediction by comparing similarities between sets of feature vectors in a transformer-based multi-frame architecture. Extensive evaluation in automated driving domains on the BDD100K and MOT17 datasets shows that our TempO approach outperforms existing self-supervised single-frame pre-training methods as well as supervised transfer learning initialization strategies on standard object detection and multi-object tracking benchmarks.