 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-based Framework for Robust Model-Based Connector Mating in Robotic Wire Harness Installation
Mar 12, 2025



Despite the widespread adoption of industrial robots in automotive assembly, wire harness installation remains a largely manual process, as it requires precise and flexible manipulation. To address this challenge, we design a novel AI-based framework that automates cable connector mating by integrating force control with deep visuotactile learning. Our system optimizes search-and-insertion strategies using first-order optimization over a multimodal transformer architecture trained on visual, tactile, and proprioceptive data. Additionally, we design a novel automated data collection and optimization pipeline that minimizes the need for machine learning expertise. The framework optimizes robot programs that run natively on standard industrial controllers, permitting human experts to audit and certify them. Experimental validations on a center console assembly task demonstrate significant improvements in cycle times and robustness compared to conventional robot programming approaches. Videos are available under https://claudius-kienle.github.io/AppMuTT.
QueryCAD: Grounded Question Answering for CAD Models
Sep 16, 2024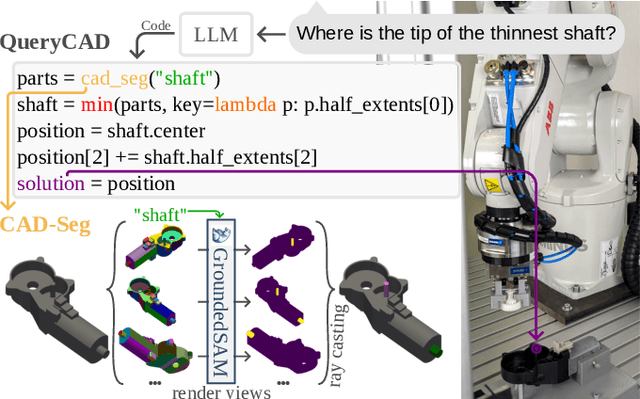
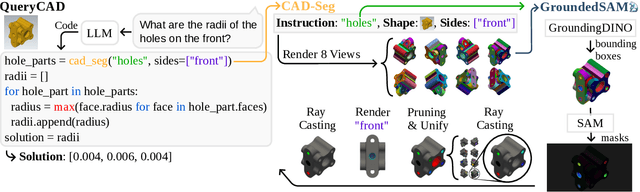
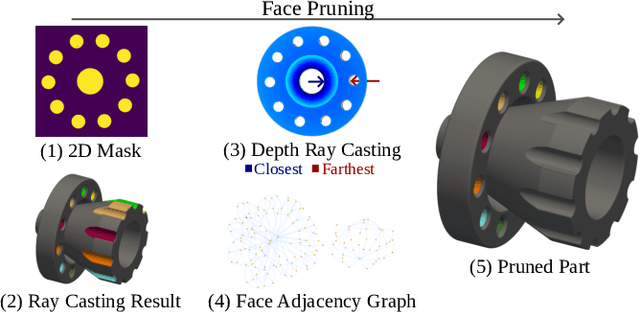
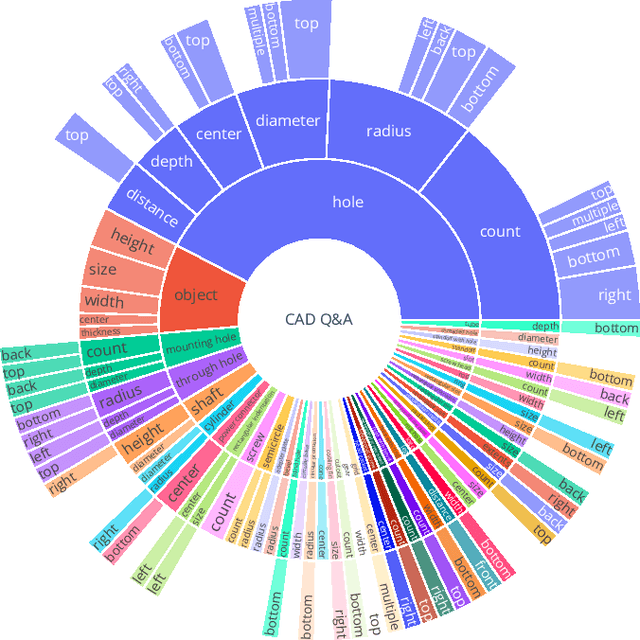
CAD models are widely used in industry and are essential for robotic automation processes. However, these models are rarely considered in novel AI-based approaches, such as the automatic synthesis of robot programs, as there are no readily available methods that would allow CAD models to be incorporated for the analysis, interpretation, or extraction of information. To address these limitations, we propose QueryCAD, the first system designed for CAD question answering, enabling the extraction of precise information from CAD models using natural language queries. QueryCAD incorporates SegCAD, an open-vocabulary instance segmentation model we developed to identify and select specific parts of the CAD model based on part descriptions. We further propose a CAD question answering benchmark to evaluate QueryCAD and establish a foundation for future research. Lastly, we integrate QueryCAD within an automatic robot program synthesis framework, validating its ability to enhance deep-learning solutions for robotics by enabling them to process CAD models (https://claudius-kienle.github.com/querycad).
Shadow Program Inversion with Differentiable Planning: A Framework for Unified Robot Program Parameter and Trajectory Optimization
Sep 13, 2024



This paper presents SPI-DP, a novel first-order optimizer capable of optimizing robot programs with respect to both high-level task objectives and motion-level constraints. To that end, we introduce DGPMP2-ND, a differentiable collision-free motion planner for serial N-DoF kinematics, and integrate it into an iterative, gradient-based optimization approach for generic, parameterized robot program representations. SPI-DP allows first-order optimization of planned trajectories and program parameters with respect to objectives such as cycle time or smoothness subject to e.g. collision constraints, while enabling humans to understand, modify or even certify the optimized programs. We provide a comprehensive evaluation on two practical household and industrial applications.
MuTT: A Multimodal Trajectory Transformer for Robot Skills
Jul 22, 2024



High-level robot skills represent an increasingly popular paradigm in robot programming. However, configuring the skills' parameters for a specific task remains a manual and time-consuming endeavor. Existing approaches for learning or optimizing these parameters often require numerous real-world executions or do not work in dynamic environments. To address these challenges, we propose MuTT, a novel encoder-decoder transformer architecture designed to predict environment-aware executions of robot skills by integrating vision, trajectory, and robot skill parameters. Notably, we pioneer the fusion of vision and trajectory, introducing a novel trajectory projection. Furthermore, we illustrate MuTT's efficacy as a predictor when combined with a model-based robot skill optimizer. This approach facilitates the optimization of robot skill parameters for the current environment, without the need for real-world executions during optimization. Designed for compatibility with any representation of robot skills, MuTT demonstrates its versatility across three comprehensive experiments, showcasing superior performance across two different skill representations.
Human-AI Interaction in Industrial Robotics: Design and Empirical Evaluation of a User Interface for Explainable AI-Based Robot Program Optimization
Apr 30, 2024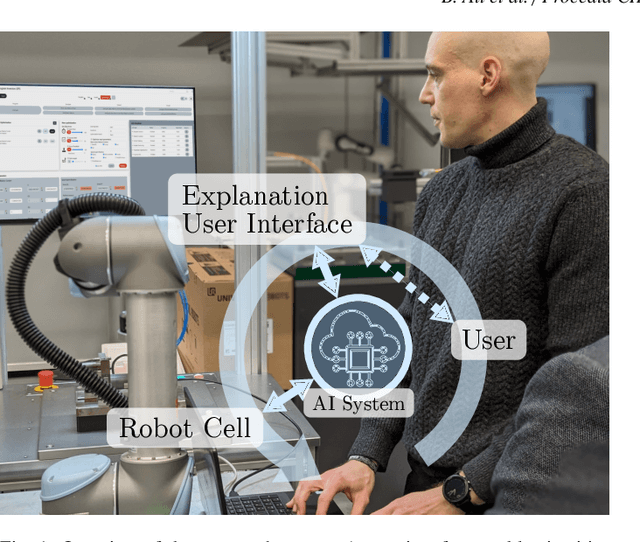


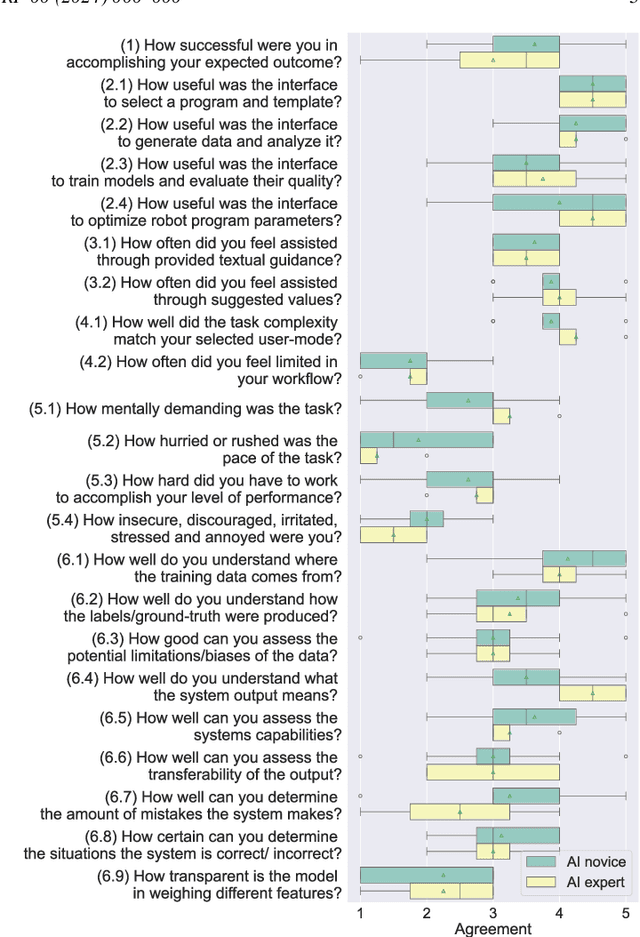
While recent advances in deep learning have demonstrated its transformative potential, its adoption for real-world manufacturing applications remains limited. We present an Explanation User Interface (XUI) for a state-of-the-art deep learning-based robot program optimizer which provides both naive and expert users with different user experiences depending on their skill level, as well as Explainable AI (XAI) features to facilitate the application of deep learning methods in real-world applications. To evaluate the impact of the XUI on task performance, user satisfaction and cognitive load, we present the results of a preliminary user survey and propose a study design for a large-scale follow-up study.
Multi-Object Self-Supervised Depth Denoising
May 09, 2023



Depth cameras are frequently used in robotic manipulation, e.g. for visual servoing. The quality of small and compact depth cameras is though often not sufficient for depth reconstruction, which is required for precise tracking in and perception of the robot's working space. Based on the work of Shabanov et al. (2021), in this work, we present a self-supervised multi-object depth denoising pipeline, that uses depth maps of higher-quality sensors as close-to-ground-truth supervisory signals to denoise depth maps coming from a lower-quality sensor. We display a computationally efficient way to align sets of two frame pairs in space and retrieve a frame-based multi-object mask, in order to receive a clean labeled dataset to train a denoising neural network on. The implementation of our presented work can be found at https://github.com/alr-internship/self-supervised-depth-denoising.