 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleCrafter: Tuning-free Higher-Resolution Visual Generation with Diffusion Models
Paper and Code

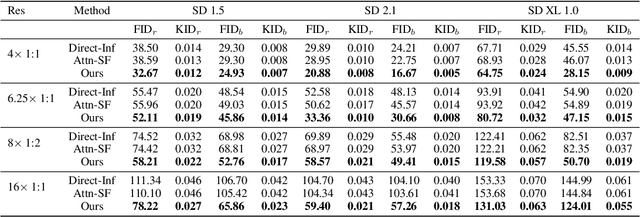


In this work, we investigate the capability of generating images from pre-trained diffusion models at much higher resolutions than the training image sizes. In addition, the generated images should have arbitrary image aspect ratios. When generating images directly at a higher resolution, 1024 x 1024, with the pre-trained Stable Diffusion using training images of resolution 512 x 512, we observe persistent problems of object repetition and unreasonable object structures. Existing works for higher-resolution generation, such as attention-based and joint-diffusion approaches, cannot well address these issues. As a new perspective, we examine the structural components of the U-Net in diffusion models and identify the crucial cause as the limited perception field of convolutional kernels. Based on this key observation, we propose a simple yet effective re-dilation that can dynamically adjust the convolutional perception field during inference. We further propose the dispersed convolution and noise-damped classifier-free guidance, which can enable ultra-high-resolution image generation (e.g., 4096 x 4096). Notably, our approach does not require any training or optimization. Extensive experiments demonstrate that our approach can address the repetition issue well and achieve state-of-the-art performance on higher-resolution image synthesis, especially in texture details. Our work also suggests that a pre-trained diffusion model trained on low-resolution images can be directly used for high-resolution visual generation without further tuning, which may provide insights for future research on ultra-high-resolution image and video synthesis.