 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Versatile and Efficient Visual Knowledge Injection into Pre-trained Language Models with Cross-Modal Adapters
Paper and Code
May 12, 2023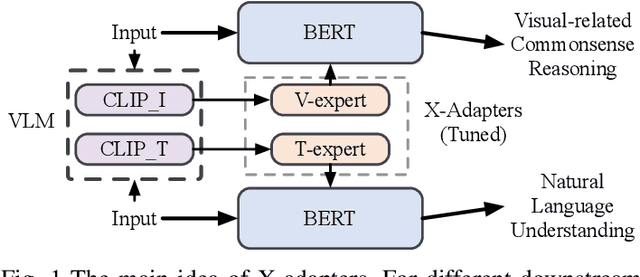

Humans learn language via multi-modal knowledge. However, due to the text-only pre-training scheme, most existing pre-trained language models (PLMs) are hindered from the multi-modal information. To inject visual knowledge into PLMs, existing methods incorporate either the text or image encoder of vision-language models (VLMs) to encode the visual information and update all the original parameters of PLMs for knowledge fusion. In this paper, we propose a new plug-and-play module, X-adapter, to flexibly leverage the aligned visual and textual knowledge learned in pre-trained VLMs and efficiently inject them into PLMs. Specifically, we insert X-adapters into PLMs, and only the added parameters are updated during adaptation. To fully exploit the potential in VLMs, X-adapters consist of two sub-modules, V-expert and T-expert, to fuse VLMs' image and text representations, respectively. We can opt for activating different sub-modules depending on the downstream tasks. Experimental results show that our method can significantly improve the performance on object-color reasoning and natural language understanding (NLU) tasks compared with PLM baselines.