 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Sentence Compression for Meeting Summarization
Paper and Code
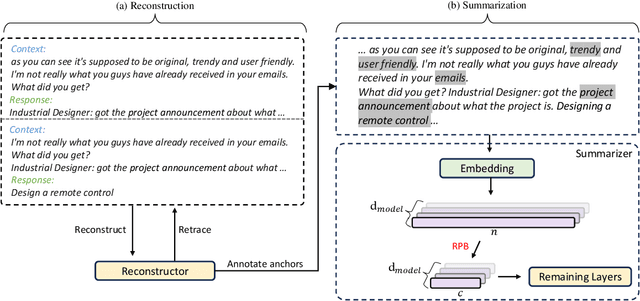
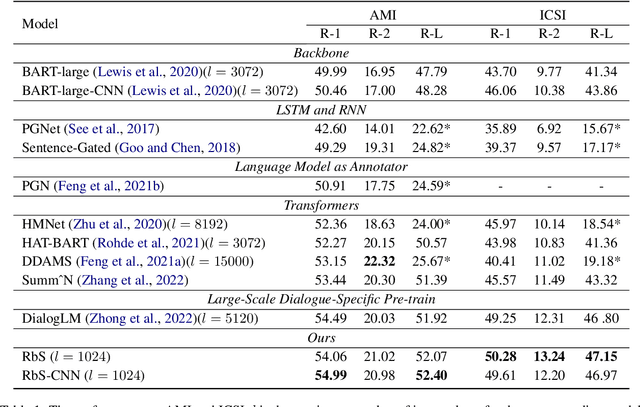
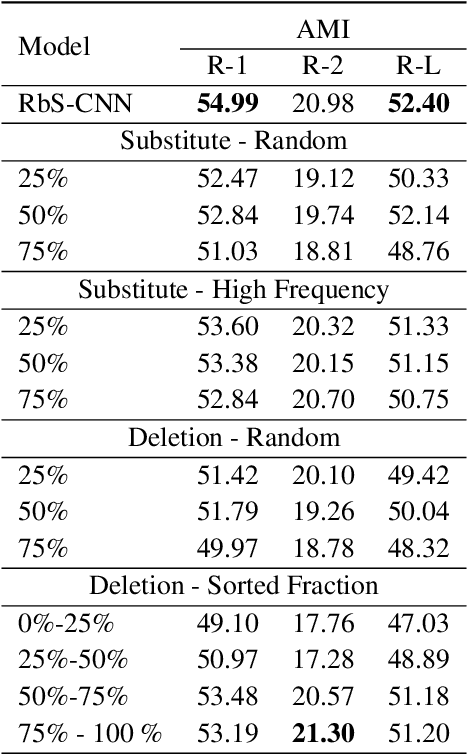
The conventional summarization model often fails to capture critical information in meeting transcripts, as meeting corpus usually involves multiple parties with lengthy conversations and is stuffed with redundant and trivial content. To tackle this problem, we present SVB, an effective and efficient framework for meeting summarization that `compress' the redundancy while preserving important content via three processes: sliding-window dialogue restoration and \textbf{S}coring, channel-wise importance score \textbf{V}oting, and relative positional \textbf{B}ucketing. Specifically, under the self-supervised paradigm, the sliding-window scoring aims to rate the importance of each token from multiple views. Then these ratings are aggregated by channel-wise voting. Tokens with high ratings will be regarded as salient information and labeled as \textit{anchors}. Finally, to tailor the lengthy input to an acceptable length for the language model, the relative positional bucketing algorithm is performed to retain the anchors while compressing other irrelevant contents in different granularities. Without large-scale pre-training or expert-grade annotating tools, our proposed method outperforms previous state-of-the-art approaches. A vast amount of evaluations and analyses are conducted to prove the effectiveness of our method.