 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Natural Image Autoencoders Compactly Tokenize fMRI Volumes for Long-Range Dynamics Modeling?
Apr 04, 2026Modeling long-range spatiotemporal dynamics in functional Magnetic Resonance Imaging (fMRI) remains a key challenge due to the high dimensionality of the four-dimensional signals. Prior voxel-based models, although demonstrating excellent performance and interpretation capabilities, are constrained by prohibitive memory demands and thus can only capture limited temporal windows. To address this, we propose TABLeT (Two-dimensionally Autoencoded Brain Latent Transformer), a novel approach that tokenizes fMRI volumes using a pre-trained 2D natural image autoencoder. Each 3D fMRI volume is compressed into a compact set of continuous tokens, enabling long-sequence modeling with a simple Transformer encoder with limited VRAM. Across large-scale benchmarks including the UK-Biobank (UKB), Human Connectome Project (HCP), and ADHD-200 datasets, TABLeT outperforms existing models in multiple tasks, while demonstrating substantial gains in computational and memory efficiency over the state-of-the-art voxel-based method given the same input. Furthermore, we develop a self-supervised masked token modeling approach to pre-train TABLeT, which improves the model's performance for various downstream tasks. Our findings suggest a promising approach for scalable and interpretable spatiotemporal modeling of brain activity. Our code is available at https://github.com/beotborry/TABLeT.
PopResume: Causal Fairness Evaluation of LLM/VLM Resume Screeners with Population-Representative Dataset
Mar 24, 2026We present PopResume, a population-representative resume dataset for causal fairness auditing of LLM- and VLM-based resume screening systems. Unlike existing benchmarks that rely on manually injected demographic information and outcome-level disparities, PopResume is grounded in population statistics and preserves natural attribute relationships, enabling path-specific effect (PSE)-based fairness evaluation. We decompose the effect of a protected attribute on resume scores into two paths: the business necessity path, mediated by job-relevant qualifications, and the redlining path, mediated by demographic proxies. This distinction allows auditors to separate legally permissible from impermissible sources of disparity. Evaluating four LLMs and four VLMs on PopResume's 60.8K resumes across five occupations, we identify five representative discrimination patterns that aggregate metrics fail to capture. Our results demonstrate that PSE-based evaluation reveals fairness issues masked by outcome-level measures, underscoring the need for causally-grounded auditing frameworks in AI-assisted hiring.
SEED: Towards More Accurate Semantic Evaluation for Visual Brain Decoding
Mar 09, 2025We present SEED (\textbf{Se}mantic \textbf{E}valuation for Visual Brain \textbf{D}ecoding), a novel metric for evaluating the semantic decoding performance of visual brain decoding models. It integrates three complementary metrics, each capturing a different aspect of semantic similarity between images. Using carefully crowd-sourced human judgment data, we demonstrate that SEED achieves the highest alignment with human evaluations, outperforming other widely used metrics. Through the evaluation of existing visual brain decoding models, we further reveal that crucial information is often lost in translation, even in state-of-the-art models that achieve near-perfect scores on existing metrics. To facilitate further research, we open-source the human judgment data, encouraging the development of more advanced evaluation methods for brain decoding models. Additionally, we propose a novel loss function designed to enhance semantic decoding performance by leveraging the order of pairwise cosine similarity in CLIP image embeddings. This loss function is compatible with various existing methods and has been shown to consistently improve their semantic decoding performances when used for training, with respect to both existing metrics and SEED.
DEAL: Decoupled Classifier with Adaptive Linear Modulation for Group Robust Early Diagnosis of MCI to AD Conversion
Nov 25, 2024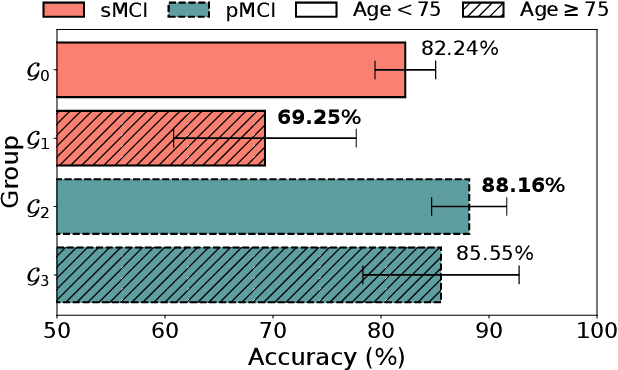


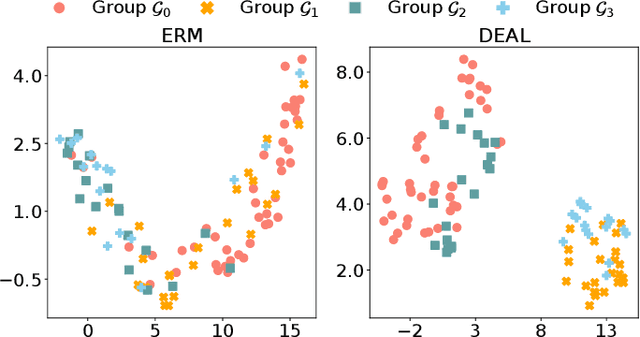
While deep learning-based Alzheimer's disease (AD) diagnosis has recently made significant advancements, particularly in predicting the conversion of mild cognitive impairment (MCI) to AD based on MRI images, there remains a critical gap in research regarding the group robustness of the diagnosis. Although numerous studies pointed out that deep learning-based classifiers may exhibit poor performance in certain groups by relying on unimportant attributes, this issue has been largely overlooked in the early diagnosis of MCI to AD conversion. In this paper, we present the first comprehensive investigation of the group robustness in the early diagnosis of MCI to AD conversion using MRI images, focusing on disparities in accuracy between groups, specifically sMCI and pMCI individuals divided by age. Our experiments reveal that standard classifiers consistently underperform for certain groups across different architectures, highlighting the need for more tailored approaches. To address this, we propose a novel method, dubbed DEAL (DEcoupled classifier with Adaptive Linear modulation), comprising two key components: (1) a linear modulation of features from the penultimate layer, incorporating easily obtainable age and cognitive indicative tabular features, and (2) a decoupled classifier that provides more tailored decision boundaries for each group, further improving performance. Through extensive experiments and evaluations across different architectures, we demonstrate the efficacy of DEAL in improving the group robustness of the MCI to AD conversion prediction.
TLDR: Text Based Last-layer Retraining for Debiasing Image Classifiers
Nov 30, 2023A classifier may depend on incidental features stemming from a strong correlation between the feature and the classification target in the training dataset. Recently, Last Layer Retraining (LLR) with group-balanced datasets is known to be efficient in mitigating the spurious correlation of classifiers. However, the acquisition of group-balanced datasets is costly, which hinders the applicability of the LLR method. In this work, we propose to perform LLR based on text datasets built with large language models for a general image classifier. We demonstrate that text can be a proxy for its corresponding image beyond the image-text joint embedding space, such as CLIP. Based on this, we use generated texts to train the final layer in the embedding space of the arbitrary image classifier. In addition, we propose a method of filtering the generated words to get rid of noisy, imprecise words, which reduces the effort of inspecting each word. We dub these procedures as TLDR (\textbf{T}ext-based \textbf{L}ast layer retraining for \textbf{D}ebiasing image classifie\textbf{R}s) and show our method achieves the performance that is comparable to those of the LLR methods that also utilize group-balanced image dataset for retraining. Furthermore, TLDR outperforms other baselines that involve training the last linear layer without a group annotated dataset.