 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXAONE 4.5 Technical Report
Apr 09, 2026This technical report introduces EXAONE 4.5, the first open-weight vision language model released by LG AI Research. EXAONE 4.5 is architected by integrating a dedicated visual encoder into the existing EXAONE 4.0 framework, enabling native multimodal pretraining over both visual and textual modalities. The model is trained on large-scale data with careful curation, particularly emphasizing document-centric corpora that align with LG's strategic application domains. This targeted data design enables substantial performance gains in document understanding and related tasks, while also delivering broad improvements across general language capabilities. EXAONE 4.5 extends context length up to 256K tokens, facilitating long-context reasoning and enterprise-scale use cases. Comparative evaluations demonstrate that EXAONE 4.5 achieves competitive performance in general benchmarks while outperforming state-of-the-art models of similar scale in document understanding and Korean contextual reasoning. As part of LG's ongoing effort toward practical industrial deployment, EXAONE 4.5 is designed to be continuously extended with additional domains and application scenarios to advance AI for a better life.
PRISP: Privacy-Safe Few-Shot Personalization via Lightweight Adaptation
Jan 10, 2026Large language model (LLM) personalization aims to adapt general-purpose models to individual users. Most existing methods, however, are developed under data-rich and resource-abundant settings, often incurring privacy risks. In contrast, realistic personalization typically occurs after deployment under (i) extremely limited user data, (ii) constrained computational resources, and (iii) strict privacy requirements. We propose PRISP, a lightweight and privacy-safe personalization framework tailored to these constraints. PRISP leverages a Text-to-LoRA hypernetwork to generate task-aware LoRA parameters from task descriptions, and enables efficient user personalization by optimizing a small subset of task-aware LoRA parameters together with minimal additional modules using few-shot user data. Experiments on a few-shot variant of the LaMP benchmark demonstrate that PRISP achieves strong overall performance compared to prior approaches, while reducing computational overhead and eliminating privacy risks.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
DoMIX: An Efficient Framework for Exploiting Domain Knowledge in Fine-Tuning
Jul 03, 2025Domain-Adaptive Pre-training (DAP) has recently gained attention for its effectiveness in fine-tuning pre-trained models. Building on this, continual DAP has been explored to develop pre-trained models capable of incrementally incorporating different domain datasets. However, existing continual DAP methods face several limitations: (1) high computational cost and GPU memory usage during training; (2) sensitivity to incremental data order; and (3) providing a single, generalized model for all end tasks, which contradicts the essence of DAP. In this paper, we propose DoMIX, a novel approach that addresses these challenges by leveraging LoRA modules, a representative parameter-efficient fine-tuning (PEFT) method. Our approach enables efficient and parallel domain-adaptive pre-training that is robust to domain order and effectively utilizes accumulated knowledge to provide tailored pre-trained models for specific tasks. We also demonstrate that our method can be extended beyond the DAP setting to standard LLM fine-tuning scenarios. Code is available at https://github.com/dohoonkim-ai/DoMIX.
MADCluster: Model-agnostic Anomaly Detection with Self-supervised Clustering Network
May 22, 2025In this paper, we propose MADCluster, a novel model-agnostic anomaly detection framework utilizing self-supervised clustering. MADCluster is applicable to various deep learning architectures and addresses the 'hypersphere collapse' problem inherent in existing deep learning-based anomaly detection methods. The core idea is to cluster normal pattern data into a 'single cluster' while simultaneously learning the cluster center and mapping data close to this center. Also, to improve expressiveness and enable effective single clustering, we propose a new 'One-directed Adaptive loss'. The optimization of this loss is mathematically proven. MADCluster consists of three main components: Base Embedder capturing high-dimensional temporal dynamics, Cluster Distance Mapping, and Sequence-wise Clustering for continuous center updates. Its model-agnostic characteristics are achieved by applying various architectures to the Base Embedder. Experiments on four time series benchmark datasets demonstrate that applying MADCluster improves the overall performance of comparative models. In conclusion, the compatibility of MADCluster shows potential for enhancing model performance across various architectures.
Converting and Smoothing False Negatives for Vision-Language Pre-training
Dec 11, 2023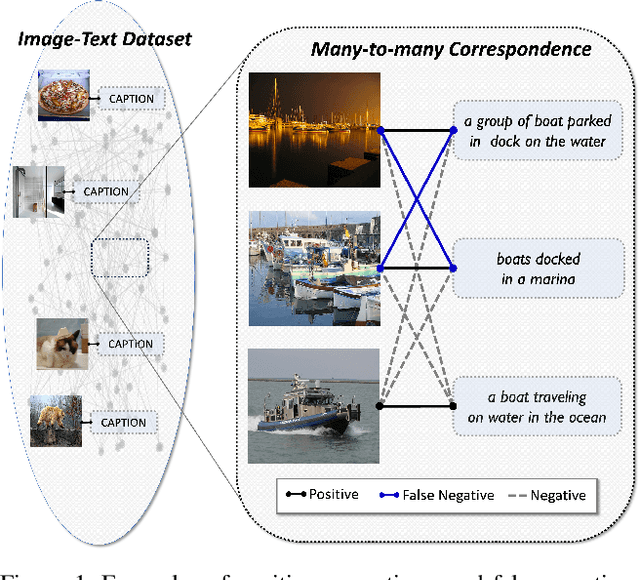



We consider the critical issue of false negatives in Vision-Language Pre-training (VLP), a challenge that arises from the inherent many-to-many correspondence of image-text pairs in large-scale web-crawled datasets. The presence of false negatives can impede achieving optimal performance and even lead to learning failures. To address this challenge, we propose a method called COSMO (COnverting and SMOoothing false negatives) that manages the false negative issues, especially powerful in hard negative sampling. Building upon the recently developed GRouped mIni-baTch sampling (GRIT) strategy, our approach consists of two pivotal components: 1) an efficient connection mining process that identifies and converts false negatives into positives, and 2) label smoothing for the image-text contrastive loss (ITC). Our comprehensive experiments verify the effectiveness of COSMO across multiple downstream tasks, emphasizing the crucial role of addressing false negatives in VLP, potentially even surpassing the importance of addressing false positives. In addition, the compatibility of COSMO with the recent BLIP-family model is also demonstrated.
Power Allocation for Device-to-Device Interference Channel Using Truncated Graph Transformers
Jul 23, 2023



Power control for the device-to-device interference channel with single-antenna transceivers has been widely analyzed with both model-based methods and learning-based approaches. Although the learning-based approaches, i.e., datadriven and model-driven, offer performance improvement, the widely adopted graph neural network suffers from learning the heterophilous power distribution of the interference channel. In this paper, we propose a deep learning architecture in the family of graph transformers to circumvent the issue. Experiment results show that the proposed methods achieve the state-of-theart performance across a wide range of untrained network configurations. Furthermore, we show there is a trade-off between model complexity and generality.
PU-EdgeFormer: Edge Transformer for Dense Prediction in Point Cloud Upsampling
May 02, 2023Despite the recent development of deep learning-based point cloud upsampling, most MLP-based point cloud upsampling methods have limitations in that it is difficult to train the local and global structure of the point cloud at the same time. To solve this problem, we present a combined graph convolution and transformer for point cloud upsampling, denoted by PU-EdgeFormer. The proposed method constructs EdgeFormer unit that consists of graph convolution and multi-head self-attention modules. We employ graph convolution using EdgeConv, which learns the local geometry and global structure of point cloud better than existing point-to-feature method. Through in-depth experiments, we confirmed that the proposed method has better point cloud upsampling performance than the existing state-of-the-art method in both subjective and objective aspects. The code is available at https://github.com/dohoon2045/PU-EdgeFormer.