 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConverting and Smoothing False Negatives for Vision-Language Pre-training
Paper and Code
Dec 11, 2023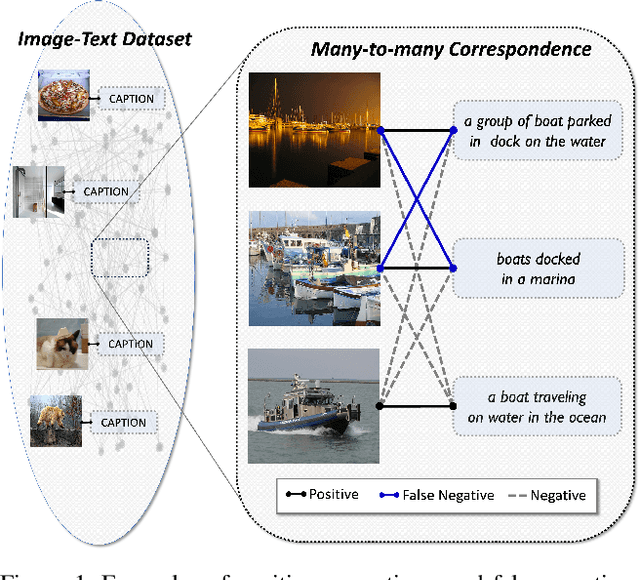



We consider the critical issue of false negatives in Vision-Language Pre-training (VLP), a challenge that arises from the inherent many-to-many correspondence of image-text pairs in large-scale web-crawled datasets. The presence of false negatives can impede achieving optimal performance and even lead to learning failures. To address this challenge, we propose a method called COSMO (COnverting and SMOoothing false negatives) that manages the false negative issues, especially powerful in hard negative sampling. Building upon the recently developed GRouped mIni-baTch sampling (GRIT) strategy, our approach consists of two pivotal components: 1) an efficient connection mining process that identifies and converts false negatives into positives, and 2) label smoothing for the image-text contrastive loss (ITC). Our comprehensive experiments verify the effectiveness of COSMO across multiple downstream tasks, emphasizing the crucial role of addressing false negatives in VLP, potentially even surpassing the importance of addressing false positives. In addition, the compatibility of COSMO with the recent BLIP-family model is also demonstrated.