 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack from the future: bidirectional CTC decoding using future information in speech recognition
Oct 07, 2021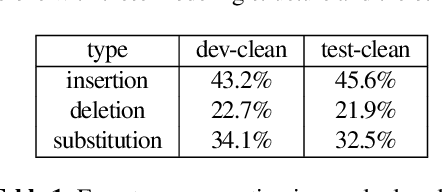

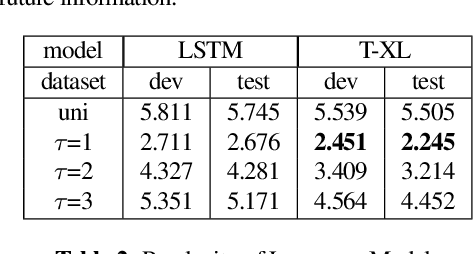
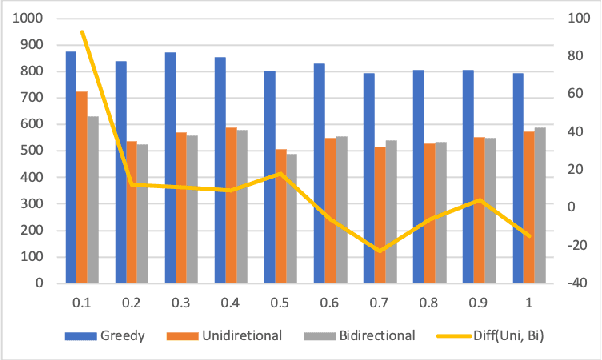
In this paper, we propose a simple but effective method to decode the output of Connectionist Temporal Classifier (CTC) model using a bi-directional neural language model. The bidirectional language model uses the future as well as the past information in order to predict the next output in the sequence. The proposed method based on bi-directional beam search takes advantage of the CTC greedy decoding output to represent the noisy future information. Experiments on the Librispeechdataset demonstrate the superiority of our proposed method compared to baselines using unidirectional decoding. In particular, the boost inaccuracy is most apparent at the start of a sequence which is the most erroneous part for existing systems based on unidirectional decoding.
Spell my name: keyword boosted speech recognition
Oct 06, 2021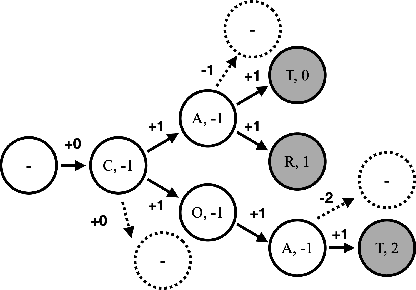


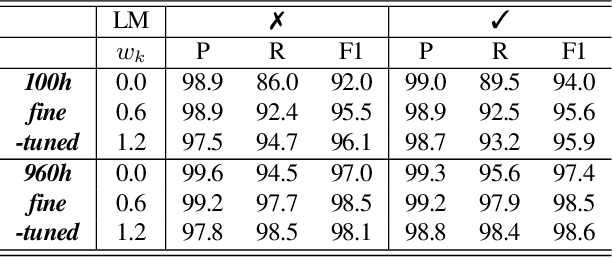
Recognition of uncommon words such as names and technical terminology is important to understanding conversations in context. However, the ability to recognise such words remains a challenge in modern automatic speech recognition (ASR) systems. In this paper, we propose a simple but powerful ASR decoding method that can better recognise these uncommon keywords, which in turn enables better readability of the results. The method boosts the probabilities of given keywords in a beam search based on acoustic model predictions. The method does not require any training in advance. We demonstrate the effectiveness of our method on the LibriSpeeech test sets and also internal data of real-world conversations. Our method significantly boosts keyword accuracy on the test sets, while maintaining the accuracy of the other words, and as well as providing significant qualitative improvements. This method is applicable to other tasks such as machine translation, or wherever unseen and difficult keywords need to be recognised in beam search.
Continuous Semantic Topic Embedding Model Using Variational Autoencoder
Nov 24, 2017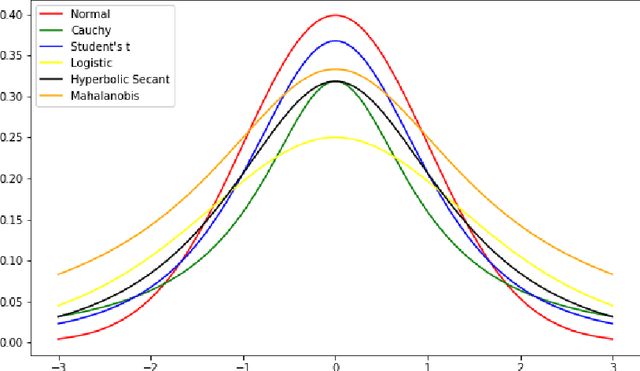
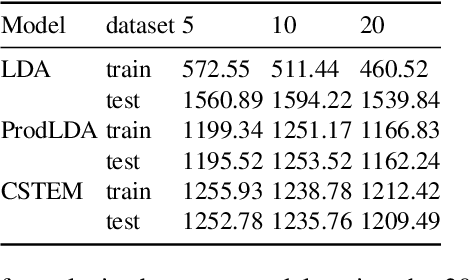
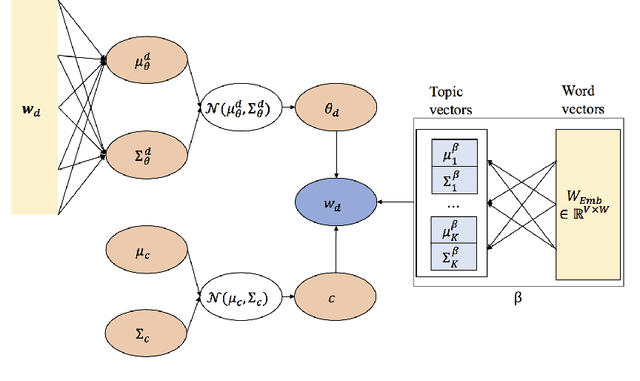
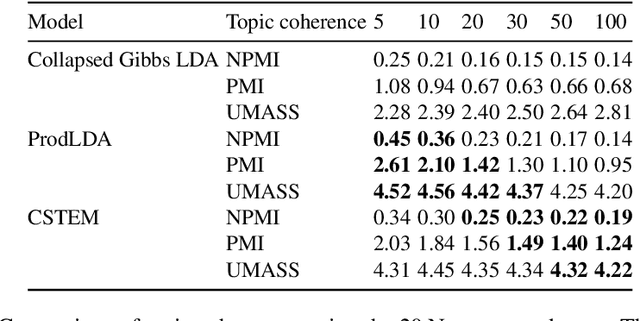
This paper proposes the continuous semantic topic embedding model (CSTEM) which finds latent topic variables in documents using continuous semantic distance function between the topics and the words by means of the variational autoencoder(VAE). The semantic distance could be represented by any symmetric bell-shaped geometric distance function on the Euclidean space, for which the Mahalanobis distance is used in this paper. In order for the semantic distance to perform more properly, we newly introduce an additional model parameter for each word to take out the global factor from this distance indicating how likely it occurs regardless of its topic. It certainly improves the problem that the Gaussian distribution which is used in previous topic model with continuous word embedding could not explain the semantic relation correctly and helps to obtain the higher topic coherence. Through the experiments with the dataset of 20 Newsgroup, NIPS papers and CNN/Dailymail corpus, the performance of the recent state-of-the-art models is accomplished by our model as well as generating topic embedding vectors which makes possible to observe where the topic vectors are embedded with the word vectors in the real Euclidean space and how the topics are related each other semantically.