 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUMBT+LaRL: End-to-end Neural Task-oriented Dialog System with Reinforcement Learning
Paper and Code
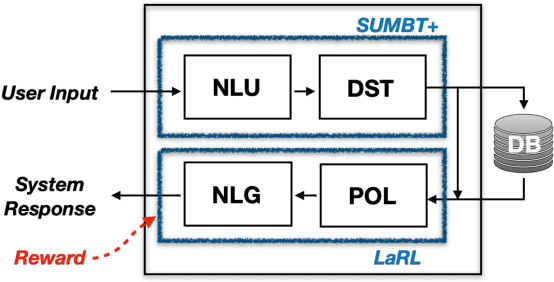
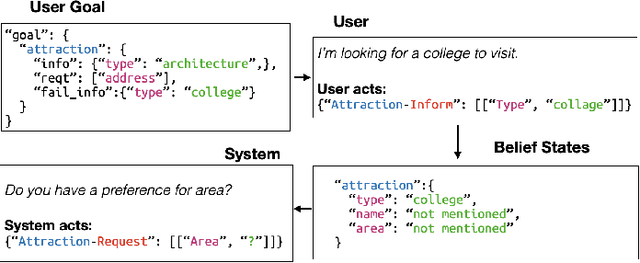
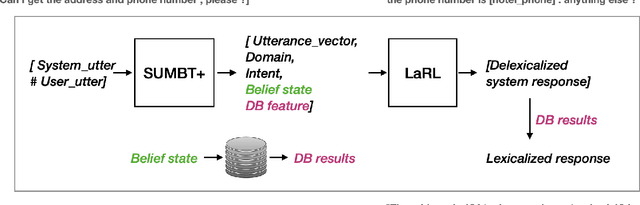
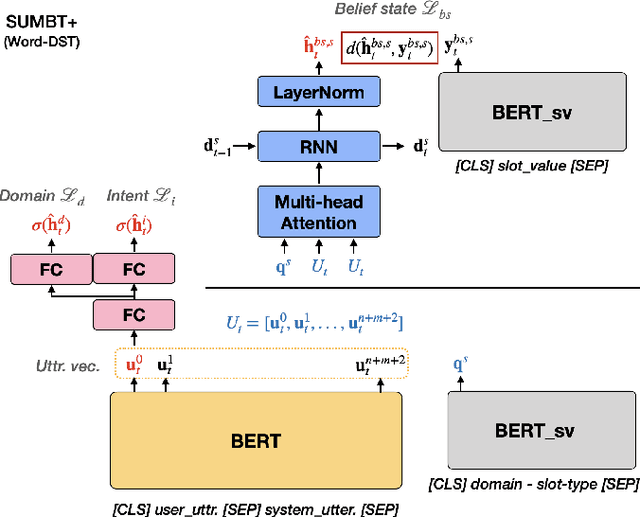
The recent advent of neural approaches for developing each dialog component in task-oriented dialog systems has remarkably improved, yet optimizing the overall system performance remains a challenge. In this paper, we propose an end-to-end trainable neural dialog system with reinforcement learning, named SUMBT+LaRL. The SUMBT+ estimates user-acts as well as dialog belief states, and the LaRL models latent system action spaces and generates responses given the estimated contexts. We experimentally demonstrate that the training framework in which the SUMBT+ and LaRL are separately pretrained and then the entire system is fine-tuned significantly increases dialog success rates. We propose new success criteria for reinforcement learning to the end-to-end dialog system as well as provide experimental analysis on a different result aspect depending on the success criteria and evaluation methods. Consequently, our model achieved the new state-of-the-art success rate of 85.4% on corpus-based evaluation, and a comparable success rate of 81.40% on simulator-based evaluation provided by the DSTC8 challenge.