 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoGymCM: Harnessing Continuous Material Stiffness for Soft Robot Co-Design
Apr 09, 2026In the automated co-design of soft robots, precisely adapting the material stiffness field to task environments is crucial for unlocking their full physical potential. However, mainstream platforms (e.g., EvoGym) strictly discretize the material dimension, artificially restricting the design space and performance of soft robots. To address this, we propose EvoGymCM (EvoGym with Continuous Materials), a benchmark suite formally establishing continuous material stiffness as a first-class design variable alongside morphology and control. Aligning with real-world material mechanisms, EvoGymCM introduces two settings: (i) EvoGymCM-R (Reactive), motivated by programmable materials with dynamically tunable stiffness; and (ii) EvoGymCM-I (Invariant), motivated by traditional materials with invariant stiffness fields. To tackle the resulting high-dimensional coupling, we formulate two Morphology-Material-Control co-design paradigms: (i) Reactive-Material Co-Design, which learns real-time stiffness tuning policies to guide programmable materials; and (ii) Invariant-Material Co-Design, which jointly optimizes morphology and fixed material fields to guide traditional material fabrication. Systematic experiments across diverse tasks demonstrate that continuous material optimization boosts performance and unlocks synergy across morphology, material, and control.
SoulX-FlashHead: Oracle-guided Generation of Infinite Real-time Streaming Talking Heads
Feb 07, 2026Achieving a balance between high-fidelity visual quality and low-latency streaming remains a formidable challenge in audio-driven portrait generation. Existing large-scale models often suffer from prohibitive computational costs, while lightweight alternatives typically compromise on holistic facial representations and temporal stability. In this paper, we propose SoulX-FlashHead, a unified 1.3B-parameter framework designed for real-time, infinite-length, and high-fidelity streaming video generation. To address the instability of audio features in streaming scenarios, we introduce Streaming-Aware Spatiotemporal Pre-training equipped with a Temporal Audio Context Cache mechanism, which ensures robust feature extraction from short audio fragments. Furthermore, to mitigate the error accumulation and identity drift inherent in long-sequence autoregressive generation, we propose Oracle-Guided Bidirectional Distillation, leveraging ground-truth motion priors to provide precise physical guidance. We also present VividHead, a large-scale, high-quality dataset containing 782 hours of strictly aligned footage to support robust training. Extensive experiments demonstrate that SoulX-FlashHead achieves state-of-the-art performance on HDTF and VFHQ benchmarks. Notably, our Lite variant achieves an inference speed of 96 FPS on a single NVIDIA RTX 4090, facilitating ultra-fast interaction without sacrificing visual coherence.
SoulX-FlashTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Jan 06, 2026Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-FlashTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-FlashTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
SoulX-LiveTalk: Real-Time Infinite Streaming of Audio-Driven Avatars via Self-Correcting Bidirectional Distillation
Dec 31, 2025Deploying massive diffusion models for real-time, infinite-duration, audio-driven avatar generation presents a significant engineering challenge, primarily due to the conflict between computational load and strict latency constraints. Existing approaches often compromise visual fidelity by enforcing strictly unidirectional attention mechanisms or reducing model capacity. To address this problem, we introduce \textbf{SoulX-LiveTalk}, a 14B-parameter framework optimized for high-fidelity real-time streaming. Diverging from conventional unidirectional paradigms, we use a \textbf{Self-correcting Bidirectional Distillation} strategy that retains bidirectional attention within video chunks. This design preserves critical spatiotemporal correlations, significantly enhancing motion coherence and visual detail. To ensure stability during infinite generation, we incorporate a \textbf{Multi-step Retrospective Self-Correction Mechanism}, enabling the model to autonomously recover from accumulated errors and preventing collapse. Furthermore, we engineered a full-stack inference acceleration suite incorporating hybrid sequence parallelism, Parallel VAE, and kernel-level optimizations. Extensive evaluations confirm that SoulX-LiveTalk is the first 14B-scale system to achieve a \textbf{sub-second start-up latency (0.87s)} while reaching a real-time throughput of \textbf{32 FPS}, setting a new standard for high-fidelity interactive digital human synthesis.
Breaking the Modality Wall: Time-step Mixup for Efficient Spiking Knowledge Transfer from Static to Event Domain
Nov 15, 2025The integration of event cameras and spiking neural networks (SNNs) promises energy-efficient visual intelligence, yet scarce event data and the sparsity of DVS outputs hinder effective training. Prior knowledge transfers from RGB to DVS often underperform because the distribution gap between modalities is substantial. In this work, we present Time-step Mixup Knowledge Transfer (TMKT), a cross-modal training framework with a probabilistic Time-step Mixup (TSM) strategy. TSM exploits the asynchronous nature of SNNs by interpolating RGB and DVS inputs at various time steps to produce a smooth curriculum within each sequence, which reduces gradient variance and stabilizes optimization with theoretical analysis. To employ auxiliary supervision from TSM, TMKT introduces two lightweight modality-aware objectives, Modality Aware Guidance (MAG) for per-frame source supervision and Mixup Ratio Perception (MRP) for sequence-level mix ratio estimation, which explicitly align temporal features with the mixing schedule. TMKT enables smoother knowledge transfer, helps mitigate modality mismatch during training, and achieves superior performance in spiking image classification tasks. Extensive experiments across diverse benchmarks and multiple SNN backbones, together with ablations, demonstrate the effectiveness of our method.
Time-step Mixup for Efficient Spiking Knowledge Transfer from Appearance to Event Domain
Sep 16, 2025The integration of event cameras and spiking neural networks holds great promise for energy-efficient visual processing. However, the limited availability of event data and the sparse nature of DVS outputs pose challenges for effective training. Although some prior work has attempted to transfer semantic knowledge from RGB datasets to DVS, they often overlook the significant distribution gap between the two modalities. In this paper, we propose Time-step Mixup knowledge transfer (TMKT), a novel fine-grained mixing strategy that exploits the asynchronous nature of SNNs by interpolating RGB and DVS inputs at various time-steps. To enable label mixing in cross-modal scenarios, we further introduce modality-aware auxiliary learning objectives. These objectives support the time-step mixup process and enhance the model's ability to discriminate effectively across different modalities. Our approach enables smoother knowledge transfer, alleviates modality shift during training, and achieves superior performance in spiking image classification tasks. Extensive experiments demonstrate the effectiveness of our method across multiple datasets. The code will be released after the double-blind review process.
Nonperiodic dynamic CT reconstruction using backward-warping INR with regularization of diffeomorphism (BIRD)
May 06, 2025
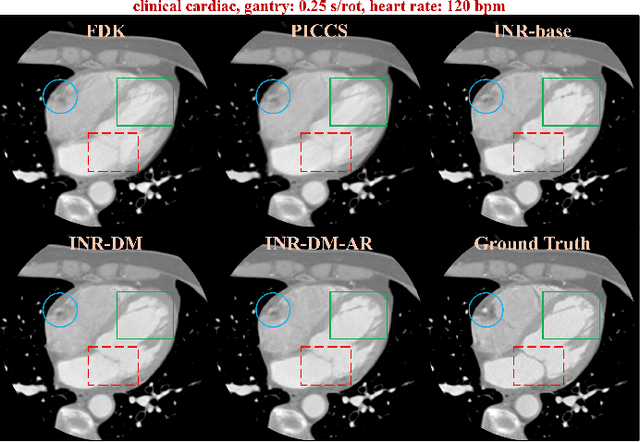
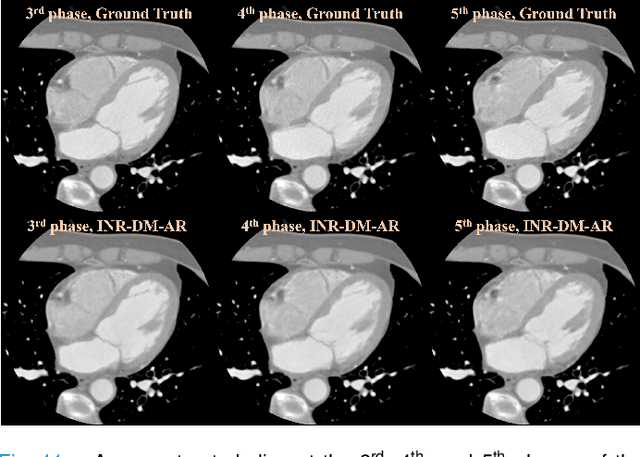

Dynamic computed tomography (CT) reconstruction faces significant challenges in addressing motion artifacts, particularly for nonperiodic rapid movements such as cardiac imaging with fast heart rates. Traditional methods struggle with the extreme limited-angle problems inherent in nonperiodic cases. Deep learning methods have improved performance but face generalization challenges. Recent implicit neural representation (INR) techniques show promise through self-supervised deep learning, but have critical limitations: computational inefficiency due to forward-warping modeling, difficulty balancing DVF complexity with anatomical plausibility, and challenges in preserving fine details without additional patient-specific pre-scans. This paper presents a novel INR-based framework, BIRD, for nonperiodic dynamic CT reconstruction. It addresses these challenges through four key contributions: (1) backward-warping deformation that enables direct computation of each dynamic voxel with significantly reduced computational cost, (2) diffeomorphism-based DVF regularization that ensures anatomically plausible deformations while maintaining representational capacity, (3) motion-compensated analytical reconstruction that enhances fine details without requiring additional pre-scans, and (4) dimensional-reduction design for efficient 4D coordinate encoding. Through various simulations and practical studies, including digital and physical phantoms and retrospective patient data, we demonstrate the effectiveness of our approach for nonperiodic dynamic CT reconstruction with enhanced details and reduced motion artifacts. The proposed framework enables more accurate dynamic CT reconstruction with potential clinical applications, such as one-beat cardiac reconstruction, cinematic image sequences for functional imaging, and motion artifact reduction in conventional CT scans.
MFP-VTON: Enhancing Mask-Free Person-to-Person Virtual Try-On via Diffusion Transformer
Feb 03, 2025



The garment-to-person virtual try-on (VTON) task, which aims to generate fitting images of a person wearing a reference garment, has made significant strides. However, obtaining a standard garment is often more challenging than using the garment already worn by the person. To improve ease of use, we propose MFP-VTON, a Mask-Free framework for Person-to-Person VTON. Recognizing the scarcity of person-to-person data, we adapt a garment-to-person model and dataset to construct a specialized dataset for this task. Our approach builds upon a pretrained diffusion transformer, leveraging its strong generative capabilities. During mask-free model fine-tuning, we introduce a Focus Attention loss to emphasize the garment of the reference person and the details outside the garment of the target person. Experimental results demonstrate that our model excels in both person-to-person and garment-to-person VTON tasks, generating high-fidelity fitting images.
IGR: Improving Diffusion Model for Garment Restoration from Person Image
Dec 16, 2024



Garment restoration, the inverse of virtual try-on task, focuses on restoring standard garment from a person image, requiring accurate capture of garment details. However, existing methods often fail to preserve the identity of the garment or rely on complex processes. To address these limitations, we propose an improved diffusion model for restoring authentic garments. Our approach employs two garment extractors to independently capture low-level features and high-level semantics from the person image. Leveraging a pretrained latent diffusion model, these features are integrated into the denoising process through garment fusion blocks, which combine self-attention and cross-attention layers to align the restored garment with the person image. Furthermore, a coarse-to-fine training strategy is introduced to enhance the fidelity and authenticity of the generated garments. Experimental results demonstrate that our model effectively preserves garment identity and generates high-quality restorations, even in challenging scenarios such as complex garments or those with occlusions.