 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative AI Agents and Critics for Fault Detection and Cause Analysis in Network Telemetry
Mar 31, 2026We develop algorithms for collaborative control of AI agents and critics in a multi-actor, multi-critic federated multi-agent system. Each AI agent and critic has access to classical machine learning or generative AI foundation models. The AI agents and critics collaborate with a central server to complete multimodal tasks such as fault detection, severity, and cause analysis in a network telemetry system, text-to-image generation, video generation, healthcare diagnostics from medical images and patient records, etcetera. The AI agents complete their tasks and send them to AI critics for evaluation. The critics then send feedback to agents to improve their responses. Collaboratively, they minimize the overall cost to the system with no inter-agent or inter-critic communication. AI agents and critics keep their cost functions or derivatives of cost functions private. Using multi-time scale stochastic approximation techniques, we provide convergence guarantees on the time-average active states of AI agents and critics. The communication overhead is a little on the system, of the order of $\mathcal{O}(m)$, for $m$ modalities and is independent of the number of AI agents and critics. Finally, we present an example of fault detection, severity, and cause analysis in network telemetry and thorough evaluation to check the algorithm's efficacy.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
ERCache: An Efficient and Reliable Caching Framework for Large-Scale User Representations in Meta's Ads System
Oct 09, 2024



The increasing complexity of deep learning models used for calculating user representations presents significant challenges, particularly with limited computational resources and strict service-level agreements (SLAs). Previous research efforts have focused on optimizing model inference but have overlooked a critical question: is it necessary to perform user model inference for every ad request in large-scale social networks? To address this question and these challenges, we first analyze user access patterns at Meta and find that most user model inferences occur within a short timeframe. T his observation reveals a triangular relationship among model complexity, embedding freshness, and service SLAs. Building on this insight, we designed, implemented, and evaluated ERCache, an efficient and robust caching framework for large-scale user representations in ads recommendation systems on social networks. ERCache categorizes cache into direct and failover types and applies customized settings and eviction policies for each model, effectively balancing model complexity, embedding freshness, and service SLAs, even considering the staleness introduced by caching. ERCache has been deployed at Meta for over six months, supporting more than 30 ranking models while efficiently conserving computational resources and complying with service SLA requirements.
LADEV: A Language-Driven Testing and Evaluation Platform for Vision-Language-Action Models in Robotic Manipulation
Oct 07, 2024



Building on the advancements of Large Language Models (LLMs) and Vision Language Models (VLMs), recent research has introduced Vision-Language-Action (VLA) models as an integrated solution for robotic manipulation tasks. These models take camera images and natural language task instructions as input and directly generate control actions for robots to perform specified tasks, greatly improving both decision-making capabilities and interaction with human users. However, the data-driven nature of VLA models, combined with their lack of interpretability, makes the assurance of their effectiveness and robustness a challenging task. This highlights the need for a reliable testing and evaluation platform. For this purpose, in this work, we propose LADEV, a comprehensive and efficient platform specifically designed for evaluating VLA models. We first present a language-driven approach that automatically generates simulation environments from natural language inputs, mitigating the need for manual adjustments and significantly improving testing efficiency. Then, to further assess the influence of language input on the VLA models, we implement a paraphrase mechanism that produces diverse natural language task instructions for testing. Finally, to expedite the evaluation process, we introduce a batch-style method for conducting large-scale testing of VLA models. Using LADEV, we conducted experiments on several state-of-the-art VLA models, demonstrating its effectiveness as a tool for evaluating these models. Our results showed that LADEV not only enhances testing efficiency but also establishes a solid baseline for evaluating VLA models, paving the way for the development of more intelligent and advanced robotic systems.
Oracle Bone Inscriptions Multi-modal Dataset
Jul 04, 2024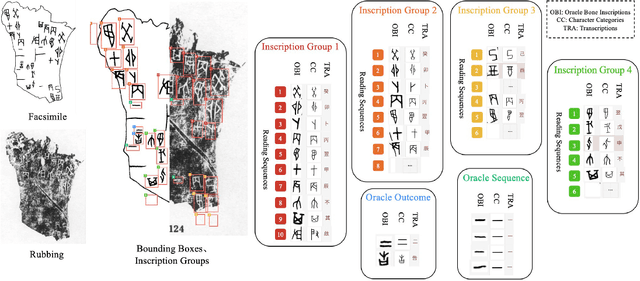
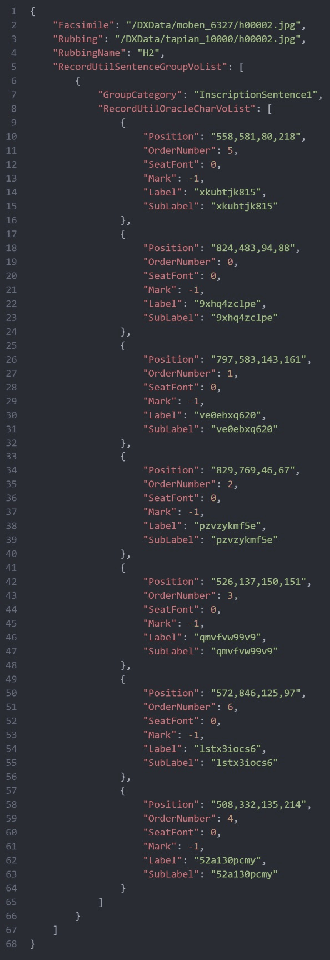
Oracle bone inscriptions(OBI) is the earliest developed writing system in China, bearing invaluable written exemplifications of early Shang history and paleography. However, the task of deciphering OBI, in the current climate of the scholarship, can prove extremely challenging. Out of the 4,500 oracle bone characters excavated, only a third have been successfully identified. Therefore, leveraging the advantages of advanced AI technology to assist in the decipherment of OBI is a highly essential research topic. However, fully utilizing AI's capabilities in these matters is reliant on having a comprehensive and high-quality annotated OBI dataset at hand whereas most existing datasets are only annotated in just a single or a few dimensions, limiting the value of their potential application. For instance, the Oracle-MNIST dataset only offers 30k images classified into 10 categories. Therefore, this paper proposes an Oracle Bone Inscriptions Multi-modal Dataset(OBIMD), which includes annotation information for 10,077 pieces of oracle bones. Each piece has two modalities: pixel-level aligned rubbings and facsimiles. The dataset annotates the detection boxes, character categories, transcriptions, corresponding inscription groups, and reading sequences in the groups of each oracle bone character, providing a comprehensive and high-quality level of annotations. This dataset can be used for a variety of AI-related research tasks relevant to the field of OBI, such as OBI Character Detection and Recognition, Rubbing Denoising, Character Matching, Character Generation, Reading Sequence Prediction, Missing Characters Completion task and so on. We believe that the creation and publication of a dataset like this will help significantly advance the application of AI algorithms in the field of OBI research.
GenSafe: A Generalizable Safety Enhancer for Safe Reinforcement Learning Algorithms Based on Reduced Order Markov Decision Process Model
Jun 06, 2024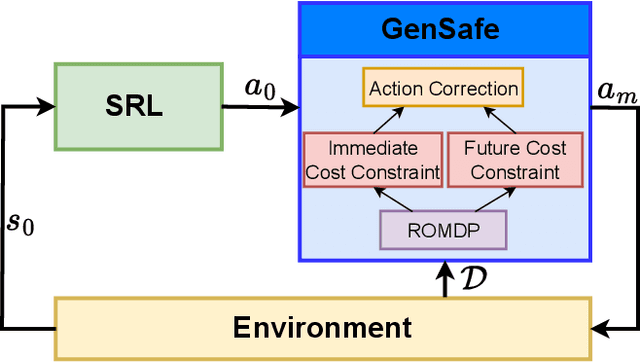
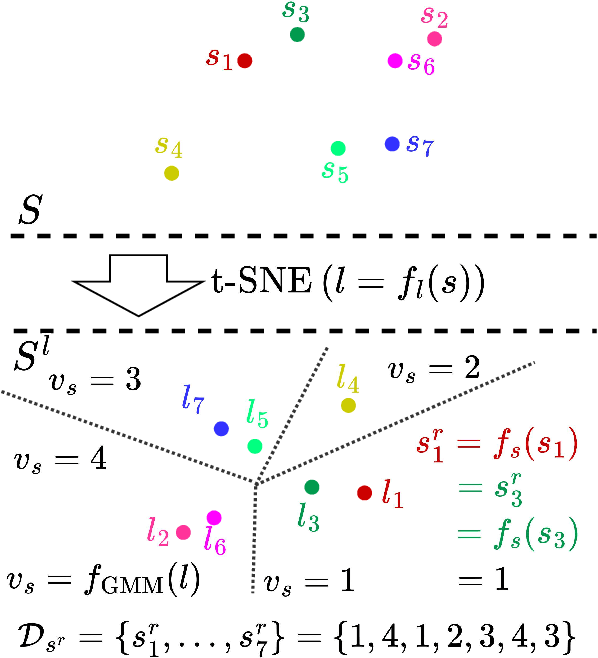


Although deep reinforcement learning has demonstrated impressive achievements in controlling various autonomous systems, e.g., autonomous vehicles or humanoid robots, its inherent reliance on random exploration raises safety concerns in their real-world applications. To improve system safety during the learning process, a variety of Safe Reinforcement Learning (SRL) algorithms have been proposed, which usually incorporate safety constraints within the Constrained Markov Decision Process (CMDP) framework. However, the efficacy of these SRL algorithms often relies on accurate function approximations, a task that is notably challenging to accomplish in the early learning stages due to data insufficiency. To address this problem, we introduce a Genralizable Safety enhancer (GenSafe) in this work. Leveraging model order reduction techniques, we first construct a Reduced Order Markov Decision Process (ROMDP) as a low-dimensional proxy for the original cost function in CMDP. Then, by solving ROMDP-based constraints that are reformulated from the original cost constraints, the proposed GenSafe refines the actions taken by the agent to enhance the possibility of constraint satisfaction. Essentially, GenSafe acts as an additional safety layer for SRL algorithms, offering broad compatibility across diverse SRL approaches. The performance of GenSafe is examined on multiple SRL benchmark problems. The results show that, it is not only able to improve the safety performance, especially in the early learning phases, but also to maintain the task performance at a satisfactory level.
Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta
Nov 16, 2023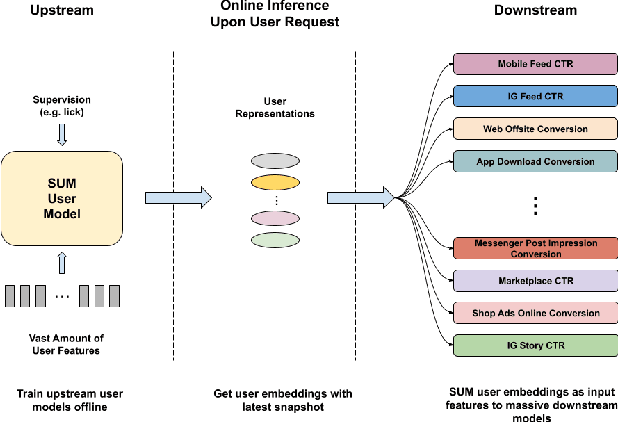
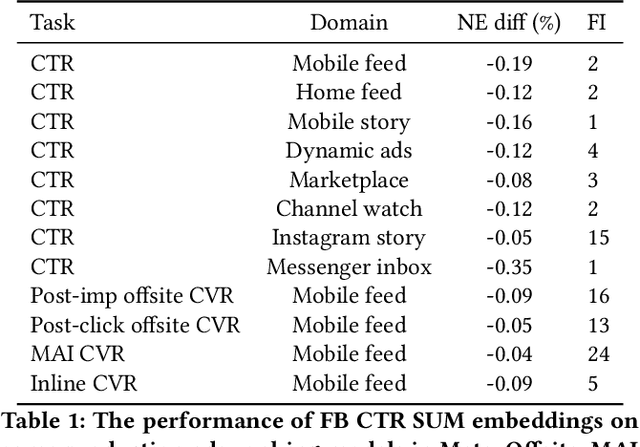
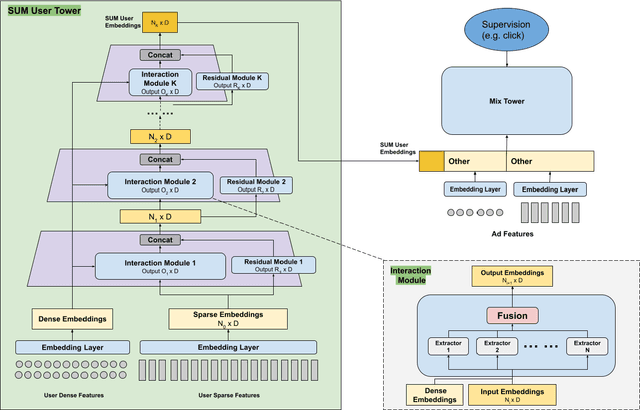

Effective user representations are pivotal in personalized advertising. However, stringent constraints on training throughput, serving latency, and memory, often limit the complexity and input feature set of online ads ranking models. This challenge is magnified in extensive systems like Meta's, which encompass hundreds of models with diverse specifications, rendering the tailoring of user representation learning for each model impractical. To address these challenges, we present Scaling User Modeling (SUM), a framework widely deployed in Meta's ads ranking system, designed to facilitate efficient and scalable sharing of online user representation across hundreds of ads models. SUM leverages a few designated upstream user models to synthesize user embeddings from massive amounts of user features with advanced modeling techniques. These embeddings then serve as inputs to downstream online ads ranking models, promoting efficient representation sharing. To adapt to the dynamic nature of user features and ensure embedding freshness, we designed SUM Online Asynchronous Platform (SOAP), a latency free online serving system complemented with model freshness and embedding stabilization, which enables frequent user model updates and online inference of user embeddings upon each user request. We share our hands-on deployment experiences for the SUM framework and validate its superiority through comprehensive experiments. To date, SUM has been launched to hundreds of ads ranking models in Meta, processing hundreds of billions of user requests daily, yielding significant online metric gains and infrastructure cost savings.
Topology Recoverability Prediction for Ad-Hoc Robot Networks: A Data-Driven Fault-Tolerant Approach
Oct 30, 2023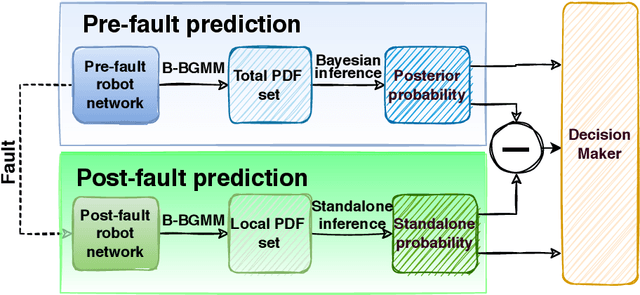
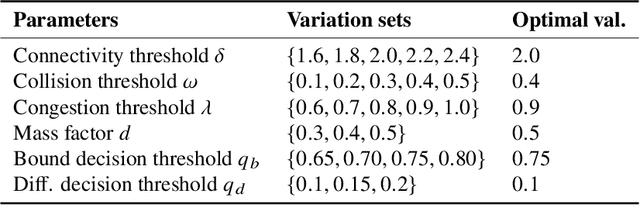

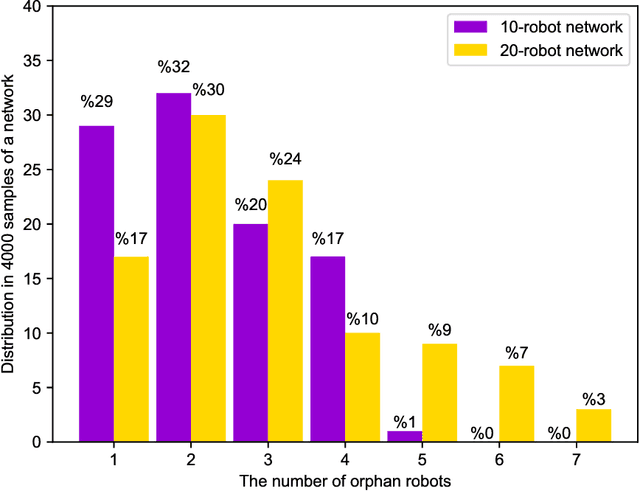
Faults occurring in ad-hoc robot networks may fatally perturb their topologies leading to disconnection of subsets of those networks. Optimal topology synthesis is generally resource-intensive and time-consuming to be done in real time for large ad-hoc robot networks. One should only perform topology re-computations if the probability of topology recoverability after the occurrence of any fault surpasses that of its irrecoverability. We formulate this problem as a binary classification problem. Then, we develop a two-pathway data-driven model based on Bayesian Gaussian mixture models that predicts the solution to a typical problem by two different pre-fault and post-fault prediction pathways. The results, obtained by the integration of the predictions of those pathways, clearly indicate the success of our model in solving the topology (ir)recoverability prediction problem compared to the best of current strategies found in the literature.
Self-Refined Large Language Model as Automated Reward Function Designer for Deep Reinforcement Learning in Robotics
Oct 02, 2023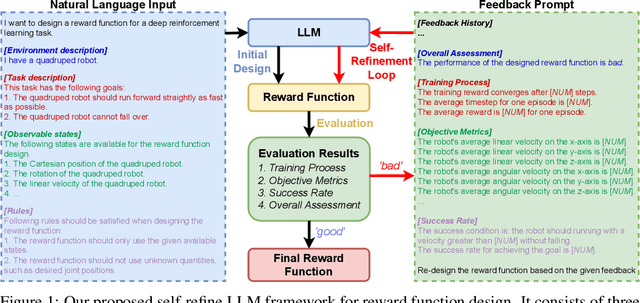
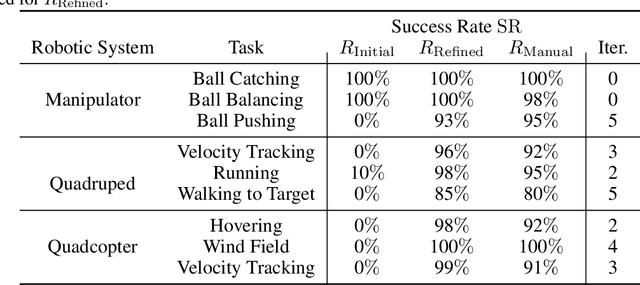
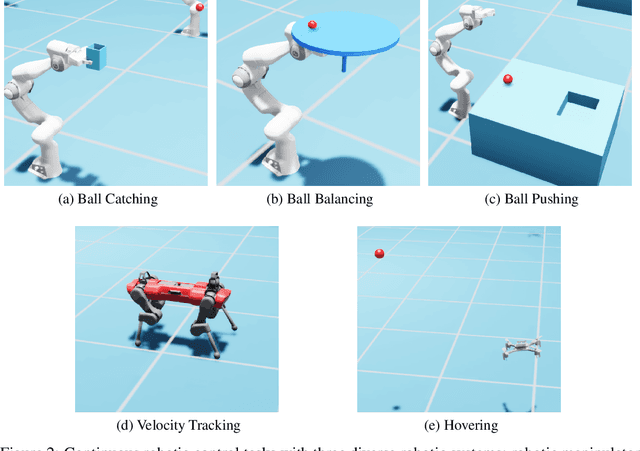

Although Deep Reinforcement Learning (DRL) has achieved notable success in numerous robotic applications, designing a high-performing reward function remains a challenging task that often requires substantial manual input. Recently, Large Language Models (LLMs) have been extensively adopted to address tasks demanding in-depth common-sense knowledge, such as reasoning and planning. Recognizing that reward function design is also inherently linked to such knowledge, LLM offers a promising potential in this context. Motivated by this, we propose in this work a novel LLM framework with a self-refinement mechanism for automated reward function design. The framework commences with the LLM formulating an initial reward function based on natural language inputs. Then, the performance of the reward function is assessed, and the results are presented back to the LLM for guiding its self-refinement process. We examine the performance of our proposed framework through a variety of continuous robotic control tasks across three diverse robotic systems. The results indicate that our LLM-designed reward functions are able to rival or even surpass manually designed reward functions, highlighting the efficacy and applicability of our approach.
ISR-LLM: Iterative Self-Refined Large Language Model for Long-Horizon Sequential Task Planning
Aug 26, 2023

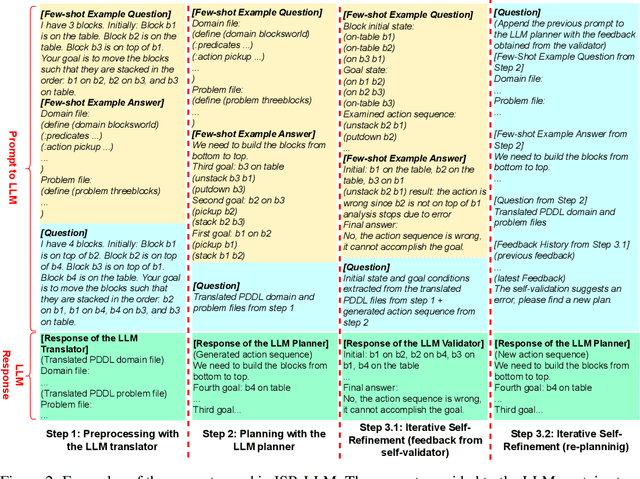

Motivated by the substantial achievements observed in Large Language Models (LLMs) in the field of natural language processing, recent research has commenced investigations into the application of LLMs for complex, long-horizon sequential task planning challenges in robotics. LLMs are advantageous in offering the potential to enhance the generalizability as task-agnostic planners and facilitate flexible interaction between human instructors and planning systems. However, task plans generated by LLMs often lack feasibility and correctness. To address this challenge, we introduce ISR-LLM, a novel framework that improves LLM-based planning through an iterative self-refinement process. The framework operates through three sequential steps: preprocessing, planning, and iterative self-refinement. During preprocessing, an LLM translator is employed to convert natural language input into a Planning Domain Definition Language (PDDL) formulation. In the planning phase, an LLM planner formulates an initial plan, which is then assessed and refined in the iterative self-refinement step by using a validator. We examine the performance of ISR-LLM across three distinct planning domains. The results show that ISR-LLM is able to achieve markedly higher success rates in task accomplishments compared to state-of-the-art LLM-based planners. Moreover, it also preserves the broad applicability and generalizability of working with natural language instructions.