 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
The Curse of Helpfulness: Inverse Scaling Law in Robustness to Distractor Instructions via DistractionIF
May 28, 2026Large Language Models (LLMs) are increasingly deployed in agentic and retrieval-augmented generation (RAG) systems, where they must execute user-specified tasks over externally provided reference text. In practice, such context is often unstructured and contaminated with benign but instruction-like semantic noise, such as editorial comments and system traces, which should be treated strictly as data. We introduce DistractionIF, a benchmark designed to evaluate robustness against such distractor instructions in reference text. Across a broad range of models, we observe a consistent inverse scaling phenomenon: larger models are often less robust, with performance dropping by up to 30 points as scale increases. Mechanistically, our perplexity analysis reveals that scaling erodes the probabilistic boundary between robust and distracted behaviors, making models increasingly prone to over-interpreting noise as instructions. To address this, we demonstrate that reinforcement learning, specifically Group Relative Policy Optimization (GRPO), can restore this boundary, improving robustness by up to 15.5% without compromising general instruction-following capability. Our findings highlight a critical instruction-following robustness gap in reference-grounded tasks and establish reinforcement learning as a promising path for enforcing strict data-instruction separation at scale.
Source-Grounded Semantic Reinforcement Learning for Low-Resource Target-Language Generation
May 28, 2026Low-resource target-language generation is often limited by scarce parallel data, while high-resource source-language monolingual data is abundant but difficult to use with standard supervised fine-tuning. We propose Source-Grounded Semantic Reinforcement Learning (SG-SRL), a resource-utilization framework that converts source-language monolingual data into cross-lingual semantic supervision for target-language generation. SG-SRL performs reference-free reinforcement learning (RL) on source-language data using a cross-lingual semantic reward model, instantiated by a cross-lingual reranker that scores the semantic relevance between the source input and the target-language generation. While this induces severe verbosity-based reward hacking, a lightweight recovery stage using a small parallel corpus restores fluency, conciseness, and task format while preserving the semantic gains. Experiments on Chinese-to-Thai generation show that SG-SRL improves semantic grounding and factual coverage over cold-start SFT. Additional analyses on long-form transfer and Tibetan embedding-based rewards clarify the generalization behavior of SG-SRL and show that an encoder-based semantic reward can substitute for an LLM-based reranker in a realistic low-resource language setting.
Reinforcement Learning with Semantic Rewards Enables Low-Resource Language Expansion without Alignment Tax
May 14, 2026Extending large language models (LLMs) to low-resource languages often incurs an "alignment tax": improvements in the target language come at the cost of catastrophic forgetting in general capabilities. We argue that this trade-off arises from the rigidity of supervised fine-tuning (SFT), which enforces token-level surface imitation on narrow and biased data distributions. To address this limitation, we propose a semantic-space alignment paradigm powered by Group Relative Policy Optimization (GRPO), where the model is optimized using embedding-level semantic rewards rather than likelihood maximization. This objective encourages meaning preservation through flexible realizations, enabling controlled updates that reduce destructive interference with pretrained knowledge. We evaluate our approach on Tibetan-Chinese machine translation and Tibetan headline generation. Experiments show that our method acquires low-resource capabilities while markedly mitigating alignment tax, preserving general competence more effectively than SFT. Despite producing less rigid surface overlap, semantic RL yields higher semantic quality and preference in open-ended generation, and few-shot transfer results indicate that it learns more transferable and robust representations under limited supervision. Overall, our study demonstrates that reinforcement learning with semantic rewards provides a safer and more reliable pathway for inclusive low-resource language expansion.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
Federated Learning on Non-iid Data via Local and Global Distillation
Jun 26, 2023



Most existing federated learning algorithms are based on the vanilla FedAvg scheme. However, with the increase of data complexity and the number of model parameters, the amount of communication traffic and the number of iteration rounds for training such algorithms increases significantly, especially in non-independently and homogeneously distributed scenarios, where they do not achieve satisfactory performance. In this work, we propose FedND: federated learning with noise distillation. The main idea is to use knowledge distillation to optimize the model training process. In the client, we propose a self-distillation method to train the local model. In the server, we generate noisy samples for each client and use them to distill other clients. Finally, the global model is obtained by the aggregation of local models. Experimental results show that the algorithm achieves the best performance and is more communication-efficient than state-of-the-art methods.
Privacy Inference-Empowered Stealthy Backdoor Attack on Federated Learning under Non-IID Scenarios
Jun 13, 2023



Federated learning (FL) naturally faces the problem of data heterogeneity in real-world scenarios, but this is often overlooked by studies on FL security and privacy. On the one hand, the effectiveness of backdoor attacks on FL may drop significantly under non-IID scenarios. On the other hand, malicious clients may steal private data through privacy inference attacks. Therefore, it is necessary to have a comprehensive perspective of data heterogeneity, backdoor, and privacy inference. In this paper, we propose a novel privacy inference-empowered stealthy backdoor attack (PI-SBA) scheme for FL under non-IID scenarios. Firstly, a diverse data reconstruction mechanism based on generative adversarial networks (GANs) is proposed to produce a supplementary dataset, which can improve the attacker's local data distribution and support more sophisticated strategies for backdoor attacks. Based on this, we design a source-specified backdoor learning (SSBL) strategy as a demonstration, allowing the adversary to arbitrarily specify which classes are susceptible to the backdoor trigger. Since the PI-SBA has an independent poisoned data synthesis process, it can be integrated into existing backdoor attacks to improve their effectiveness and stealthiness in non-IID scenarios. Extensive experiments based on MNIST, CIFAR10 and Youtube Aligned Face datasets demonstrate that the proposed PI-SBA scheme is effective in non-IID FL and stealthy against state-of-the-art defense methods.
Towards Scalable and Privacy-Preserving Deep Neural Network via Algorithmic-Cryptographic Co-design
Dec 17, 2020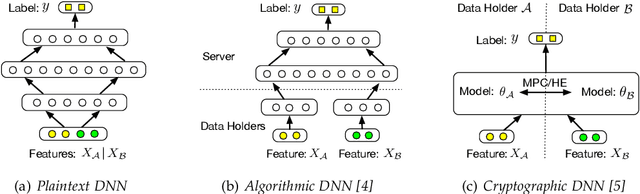
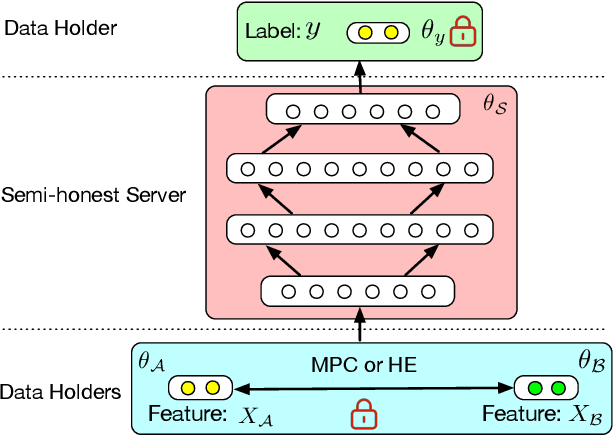


Deep Neural Networks (DNNs) have achieved remarkable progress in various real-world applications, especially when abundant training data are provided. However, data isolation has become a serious problem currently. Existing works build privacy preserving DNN models from either algorithmic perspective or cryptographic perspective. The former mainly splits the DNN computation graph between data holders or between data holders and server, which demonstrates good scalability but suffers from accuracy loss and potential privacy risks. In contrast, the latter leverages time-consuming cryptographic techniques, which has strong privacy guarantee but poor scalability. In this paper, we propose SPNN - a Scalable and Privacy-preserving deep Neural Network learning framework, from algorithmic-cryptographic co-perspective. From algorithmic perspective, we split the computation graph of DNN models into two parts, i.e., the private data related computations that are performed by data holders and the rest heavy computations that are delegated to a server with high computation ability. From cryptographic perspective, we propose using two types of cryptographic techniques, i.e., secret sharing and homomorphic encryption, for the isolated data holders to conduct private data related computations privately and cooperatively. Furthermore, we implement SPNN in a decentralized setting and introduce user-friendly APIs. Experimental results conducted on real-world datasets demonstrate the superiority of SPNN.
ASFGNN: Automated Separated-Federated Graph Neural Network
Nov 06, 2020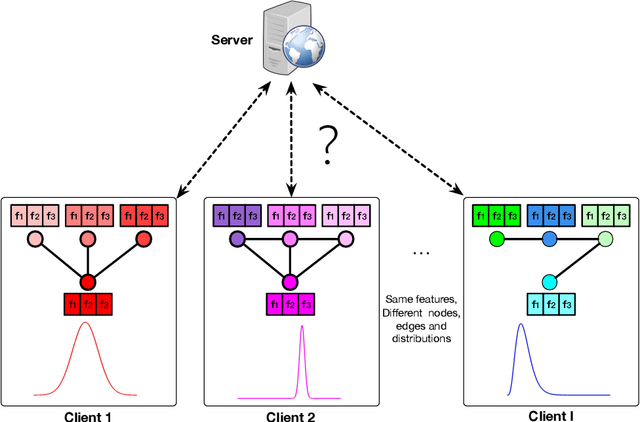
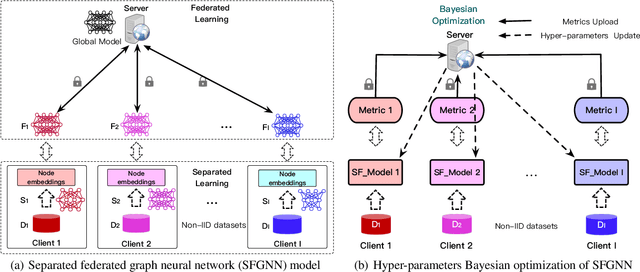
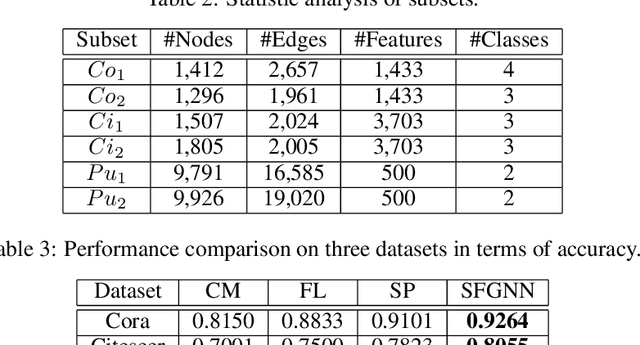
Graph Neural Networks (GNNs) have achieved remarkable performance by taking advantage of graph data. The success of GNN models always depends on rich features and adjacent relationships. However, in practice, such data are usually isolated by different data owners (clients) and thus are likely to be Non-Independent and Identically Distributed (Non-IID). Meanwhile, considering the limited network status of data owners, hyper-parameters optimization for collaborative learning approaches is time-consuming in data isolation scenarios. To address these problems, we propose an Automated Separated-Federated Graph Neural Network (ASFGNN) learning paradigm. ASFGNN consists of two main components, i.e., the training of GNN and the tuning of hyper-parameters. Specifically, to solve the data Non-IID problem, we first propose a separated-federated GNN learning model, which decouples the training of GNN into two parts: the message passing part that is done by clients separately, and the loss computing part that is learnt by clients federally. To handle the time-consuming parameter tuning problem, we leverage Bayesian optimization technique to automatically tune the hyper-parameters of all the clients. We conduct experiments on benchmark datasets and the results demonstrate that ASFGNN significantly outperforms the naive federated GNN, in terms of both accuracy and parameter-tuning efficiency.