 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Sparsity-Aware Privacy-Preserving K-means Clustering with Application to Fraud Detection
Aug 12, 2022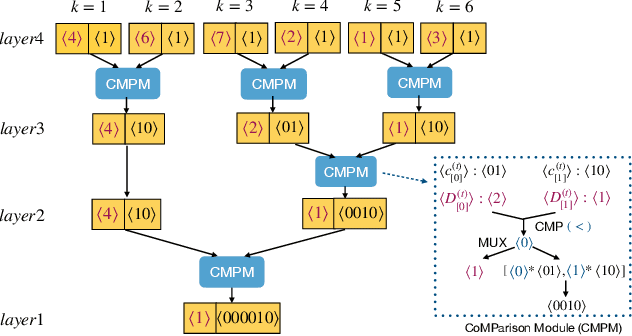
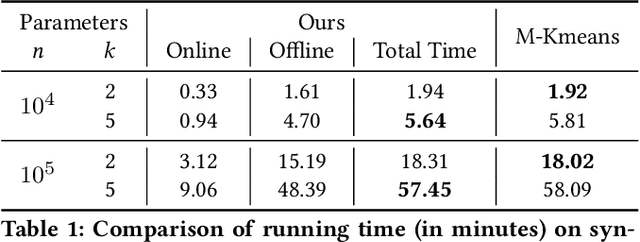
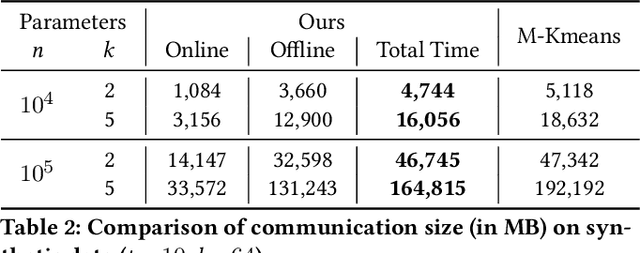
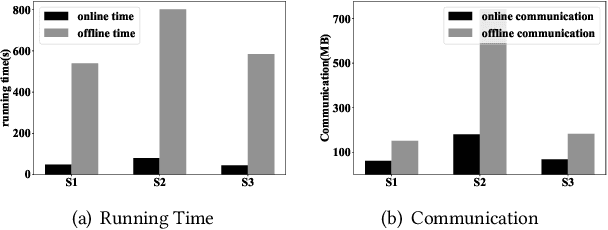
K-means is one of the most widely used clustering models in practice. Due to the problem of data isolation and the requirement for high model performance, how to jointly build practical and secure K-means for multiple parties has become an important topic for many applications in the industry. Existing work on this is mainly of two types. The first type has efficiency advantages, but information leakage raises potential privacy risks. The second type is provable secure but is inefficient and even helpless for the large-scale data sparsity scenario. In this paper, we propose a new framework for efficient sparsity-aware K-means with three characteristics. First, our framework is divided into a data-independent offline phase and a much faster online phase, and the offline phase allows to pre-compute almost all cryptographic operations. Second, we take advantage of the vectorization techniques in both online and offline phases. Third, we adopt a sparse matrix multiplication for the data sparsity scenario to improve efficiency further. We conduct comprehensive experiments on three synthetic datasets and deploy our model in a real-world fraud detection task. Our experimental results show that, compared with the state-of-the-art solution, our model achieves competitive performance in terms of both running time and communication size, especially on sparse datasets.
Industrial Scale Privacy Preserving Deep Neural Network
Mar 12, 2020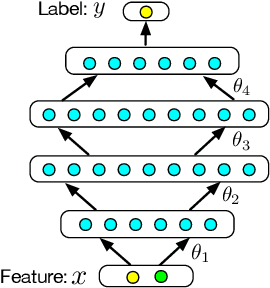
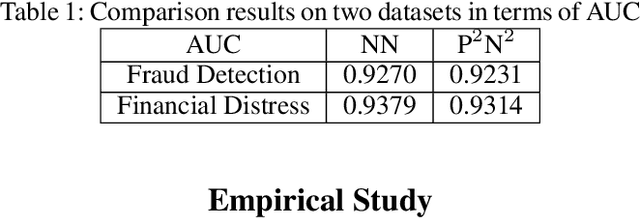
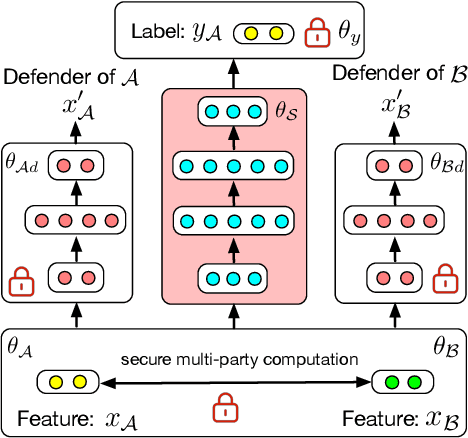
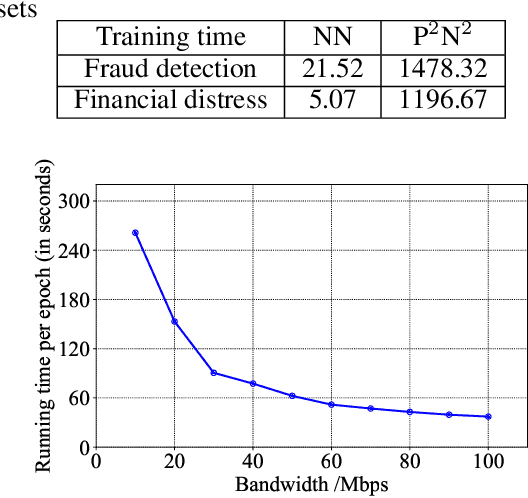
Deep Neural Network (DNN) has been showing great potential in kinds of real-world applications such as fraud detection and distress prediction. Meanwhile, data isolation has become a serious problem currently, i.e., different parties cannot share data with each other. To solve this issue, most research leverages cryptographic techniques to train secure DNN models for multi-parties without compromising their private data. Although such methods have strong security guarantee, they are difficult to scale to deep networks and large datasets due to its high communication and computation complexities. To solve the scalability of the existing secure Deep Neural Network (DNN) in data isolation scenarios, in this paper, we propose an industrial scale privacy preserving neural network learning paradigm, which is secure against semi-honest adversaries. Our main idea is to split the computation graph of DNN into two parts, i.e., the computations related to private data are performed by each party using cryptographic techniques, and the rest computations are done by a neutral server with high computation ability. We also present a defender mechanism for further privacy protection. We conduct experiments on real-world fraud detection dataset and financial distress prediction dataset, the encouraging results demonstrate the practicalness of our proposal.
Privacy Preserving PCA for Multiparty Modeling
Feb 09, 2020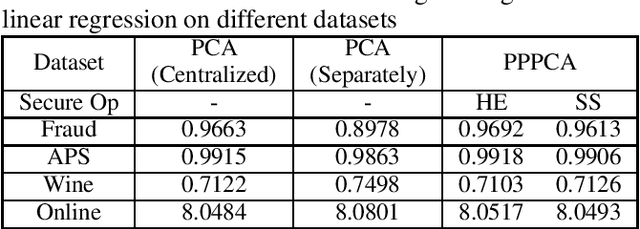
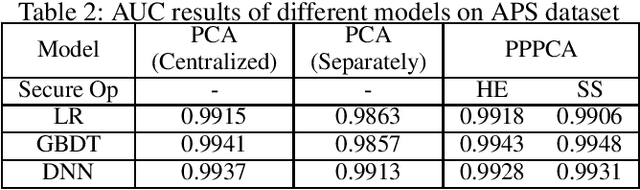
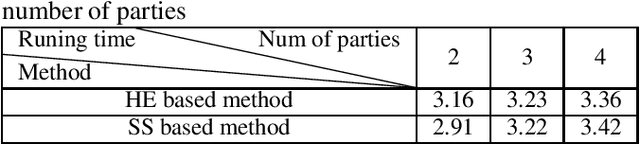
In this paper, we present a general multiparty modeling paradigm with Privacy Preserving Principal Component Analysis (PPPCA) for horizontally partitioned data. PPPCA can accomplish multiparty cooperative execution of PCA under the premise of keeping plaintext data locally. We also propose implementations using two techniques, i.e., homomorphic encryption and secret sharing. The output of PPPCA can be sent directly to data consumer to build any machine learning models. We conduct experiments on three UCI benchmark datasets and a real-world fraud detection dataset. Results show that the accuracy of the model built upon PPPCA is the same as the model with PCA that is built based on centralized plaintext data.
Federated Forest
May 24, 2019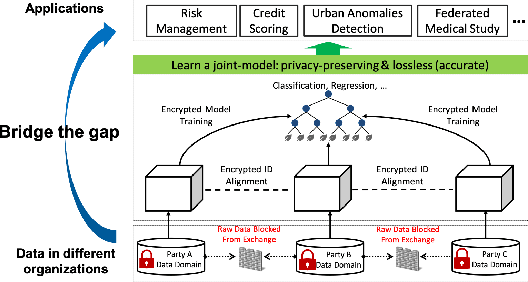
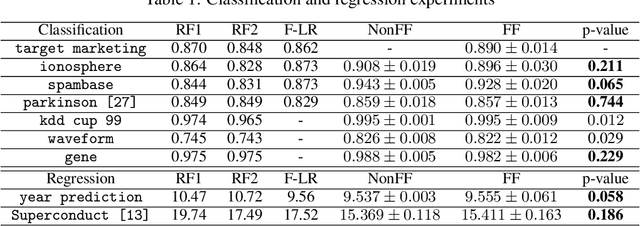
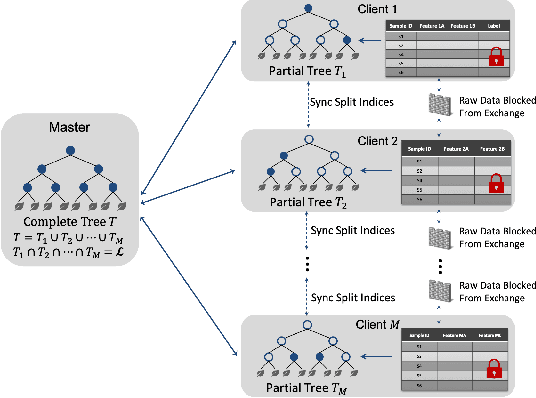
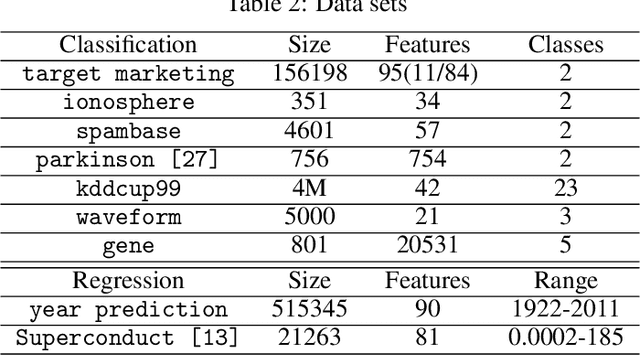
Most real-world data are scattered across different companies or government organizations, and cannot be easily integrated under data privacy and related regulations such as the European Union's General Data Protection Regulation (GDPR) and China' Cyber Security Law. Such data islands situation and data privacy & security are two major challenges for applications of artificial intelligence. In this paper, we tackle these challenges and propose a privacy-preserving machine learning model, called Federated Forest, which is a lossless learning model of the traditional random forest method, i.e., achieving the same level of accuracy as the non-privacy-preserving approach. Based on it, we developed a secure cross-regional machine learning system that allows a learning process to be jointly trained over different regions' clients with the same user samples but different attribute sets, processing the data stored in each of them without exchanging their raw data. A novel prediction algorithm was also proposed which could largely reduce the communication overhead. Experiments on both real-world and UCI data sets demonstrate the performance of the Federated Forest is as accurate as the non-federated version. The efficiency and robustness of our proposed system had been verified. Overall, our model is practical, scalable and extensible for real-life tasks.