 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStubborn: A Streamlined and Unified Reinforcement Learning Framework for Robust Motion Tracking and Fall Recovery for Humanoids
Jun 11, 2026Recent reinforcement learning approaches have shown great promise in improving humanoid motion tracking performance and achieving fall recovery under disturbances. However, most existing works treat motion tracking and fall recovery as different tasks and require multi-stage training with specialized recovery rewards and/or separate recovery policies. Moreover, existing reinforcement learning-based methods often terminate training episodes immediately after severe tracking failures, limiting recovery-oriented exploration in unstable or fallen states. To address the above issues, we propose Stubborn, a streamlined and unified reinforcement learning framework to achieve robust humanoid motion tracking and fall recovery. Specifically, Stubborn uses an asymmetric Actor-Critic architecture and consists of three major components. First, a yaw-aligned tracking representation is adopted to reduce sensitivity to global drift and heading disturbances while preserving gravity-related balance information. Second, we introduce a Bernoulli-based probabilistic termination mechanism that enables the policy to encourage exploration of fall-recovery behaviors under varying failure modes. Third, we propose a probabilistic termination and tracking-error-driven strategy that dynamically reshapes the sampling distribution based on tracking performance, increasing the training efficiency for difficult motion segments and unstable states. Extensive comparisons with SOTA methods and ablation studies show that Stubborn achieved competitive performance, and the proposed probabilistic termination mechanism and adaptive sampling strategy contributed to the performance and robustness gains. For real-world demonstrations, please refer to https://aislab-sustech.github.io/Stubborn/.
MUSCLE-NET: Predicted-Multiscale-Aware Network for Pedestrian Trajectory Forecasting
May 30, 2026Accurate pedestrian trajectory prediction is essential for safe navigation in autonomous driving and intelligent transportation systems. Despite substantial progress made by recent methods, most existing approaches are limited in fully exploiting diverse observations and often overlook the scale dependency of future motion, treating multiscale features uniformly regardless of underlying motion dynamics. This limits their robustness across diverse pedestrian behaviors. To address these challenges, we propose a Predicted-MUltiSCale-Aware Network (MUSCLE-NET) for Pedestrian Trajectory Forecasting that integrates complementary multimodal cues with scale-adaptive prediction mechanisms. The proposed framework is built upon a Multiscale Multimodal Feature Extraction (MMFE) module, which combines multiscale representation, modality-aware recalibration, and directional cross-modal fusion to construct semantically aligned representations from bounding boxes, velocities, and pose information. Building on these features, a Multiscale Enhanced Hierarchical Prediction (MEHP) module performs prediction-aware future-motion refinement via a probabilistic coarse predictor, scale-aligned fusion, and progressive refinement, adaptively selecting scale-relevant cues to mitigate spatial drift. Extensive experiments on the JAAD and PIE benchmarks demonstrate that the proposed MUSCLE-Net achieves competitive performance and consistent gains compared with state-of-the-art trajectory prediction methods.
Atomicity for Agents: Exposing, Exploiting, and Mitigating TOCTOU Vulnerabilities in Browser-Use Agents
Feb 28, 2026Browser-use agents are widely used for everyday tasks. They enable automated interaction with web pages through structured DOM based interfaces or vision language models operating on page screenshots. However, web pages often change between planning and execution, causing agents to execute actions based on stale assumptions. We view this temporal mismatch as a time of check to time of use (TOCTOU) vulnerability in browser-use agents. Dynamic or adversarial web content can exploit this window to induce unintended actions. We present a large scale empirical study of TOCTOU vulnerabilities in browser-use agents using a benchmark that spans synthesized and real world websites. Using this benchmark, we evaluate 10 popular open source agents and show that TOCTOU vulnerabilities are widespread. We design a lightweight mitigation based on pre-execution validation. It monitors DOM and layout changes during planning and validates the page state immediately before action execution. This approach reduces the risk of insecure execution and mitigates unintended side effects in browser-use agents.
Web Verbs: Typed Abstractions for Reliable Task Composition on the Agentic Web
Feb 19, 2026The Web is evolving from a medium that humans browse to an environment where software agents act on behalf of users. Advances in large language models (LLMs) make natural language a practical interface for goal-directed tasks, yet most current web agents operate on low-level primitives such as clicks and keystrokes. These operations are brittle, inefficient, and difficult to verify. Complementing content-oriented efforts such as NLWeb's semantic layer for retrieval, we argue that the agentic web also requires a semantic layer for web actions. We propose \textbf{Web Verbs}, a web-scale set of typed, semantically documented functions that expose site capabilities through a uniform interface, whether implemented through APIs or robust client-side workflows. These verbs serve as stable and composable units that agents can discover, select, and synthesize into concise programs. This abstraction unifies API-based and browser-based paradigms, enabling LLMs to synthesize reliable and auditable workflows with explicit control and data flow. Verbs can carry preconditions, postconditions, policy tags, and logging support, which improves \textbf{reliability} by providing stable interfaces, \textbf{efficiency} by reducing dozens of steps into a few function calls, and \textbf{verifiability} through typed contracts and checkable traces. We present our vision, a proof-of-concept implementation, and representative case studies that demonstrate concise and robust execution compared to existing agents. Finally, we outline a roadmap for standardization to make verbs deployable and trustworthy at web scale.
Intention-Aware Diffusion Model for Pedestrian Trajectory Prediction
Aug 10, 2025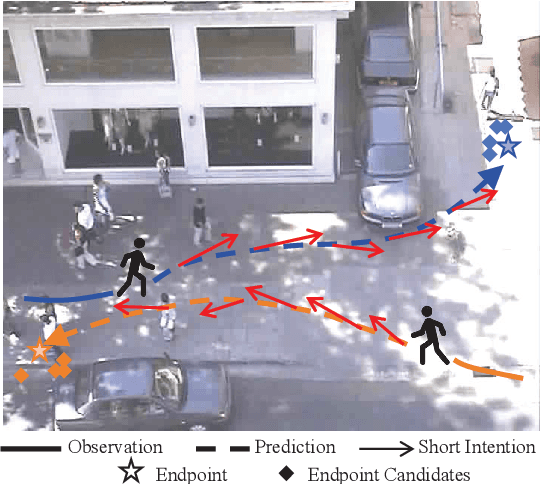
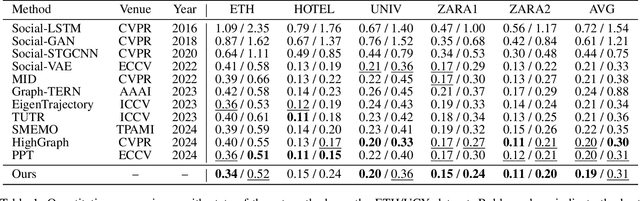
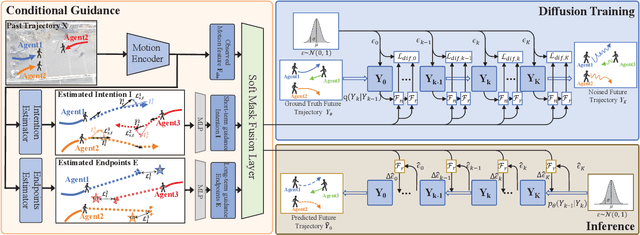
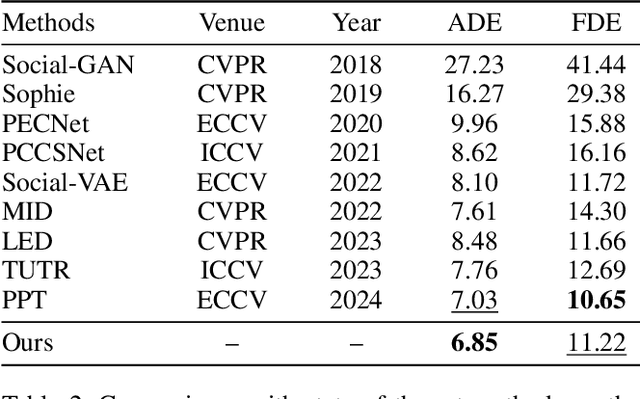
Predicting pedestrian motion trajectories is critical for the path planning and motion control of autonomous vehicles. Recent diffusion-based models have shown promising results in capturing the inherent stochasticity of pedestrian behavior for trajectory prediction. However, the absence of explicit semantic modelling of pedestrian intent in many diffusion-based methods may result in misinterpreted behaviors and reduced prediction accuracy. To address the above challenges, we propose a diffusion-based pedestrian trajectory prediction framework that incorporates both short-term and long-term motion intentions. Short-term intent is modelled using a residual polar representation, which decouples direction and magnitude to capture fine-grained local motion patterns. Long-term intent is estimated through a learnable, token-based endpoint predictor that generates multiple candidate goals with associated probabilities, enabling multimodal and context-aware intention modelling. Furthermore, we enhance the diffusion process by incorporating adaptive guidance and a residual noise predictor that dynamically refines denoising accuracy. The proposed framework is evaluated on the widely used ETH, UCY, and SDD benchmarks, demonstrating competitive results against state-of-the-art methods.
Intention Enhanced Diffusion Model for Multimodal Pedestrian Trajectory Prediction
Aug 06, 2025
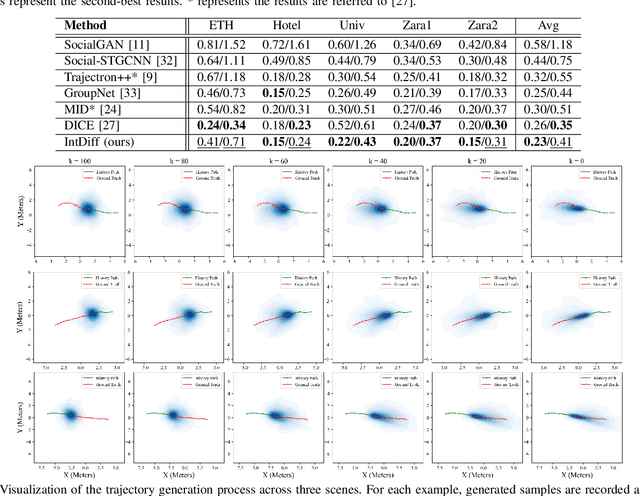
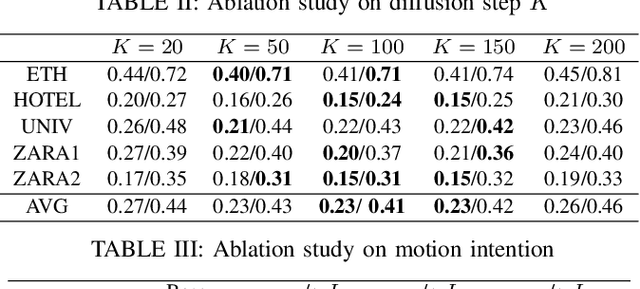

Predicting pedestrian motion trajectories is critical for path planning and motion control of autonomous vehicles. However, accurately forecasting crowd trajectories remains a challenging task due to the inherently multimodal and uncertain nature of human motion. Recent diffusion-based models have shown promising results in capturing the stochasticity of pedestrian behavior for trajectory prediction. However, few diffusion-based approaches explicitly incorporate the underlying motion intentions of pedestrians, which can limit the interpretability and precision of prediction models. In this work, we propose a diffusion-based multimodal trajectory prediction model that incorporates pedestrians' motion intentions into the prediction framework. The motion intentions are decomposed into lateral and longitudinal components, and a pedestrian intention recognition module is introduced to enable the model to effectively capture these intentions. Furthermore, we adopt an efficient guidance mechanism that facilitates the generation of interpretable trajectories. The proposed framework is evaluated on two widely used human trajectory prediction benchmarks, ETH and UCY, on which it is compared against state-of-the-art methods. The experimental results demonstrate that our method achieves competitive performance.
Unveiling the Impact of Multimodal Features on Chinese Spelling Correction: From Analysis to Design
Apr 10, 2025
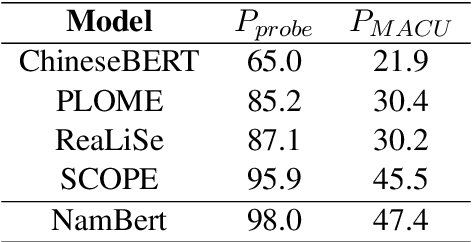
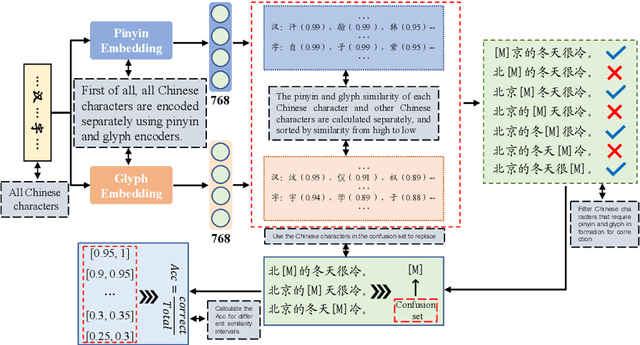
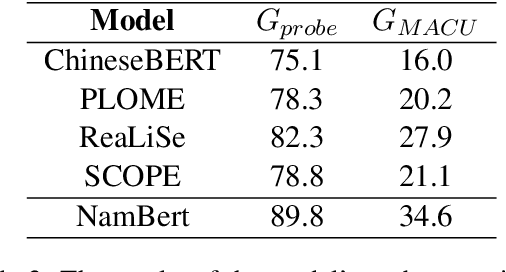
The Chinese Spelling Correction (CSC) task focuses on detecting and correcting spelling errors in sentences. Current research primarily explores two approaches: traditional multimodal pre-trained models and large language models (LLMs). However, LLMs face limitations in CSC, particularly over-correction, making them suboptimal for this task. While existing studies have investigated the use of phonetic and graphemic information in multimodal CSC models, effectively leveraging these features to enhance correction performance remains a challenge. To address this, we propose the Multimodal Analysis for Character Usage (\textbf{MACU}) experiment, identifying potential improvements for multimodal correctison. Based on empirical findings, we introduce \textbf{NamBert}, a novel multimodal model for Chinese spelling correction. Experiments on benchmark datasets demonstrate NamBert's superiority over SOTA methods. We also conduct a comprehensive comparison between NamBert and LLMs, systematically evaluating their strengths and limitations in CSC. Our code and model are available at https://github.com/iioSnail/NamBert.
GenEM: Physics-Informed Generative Cryo-Electron Microscopy
Dec 04, 2023


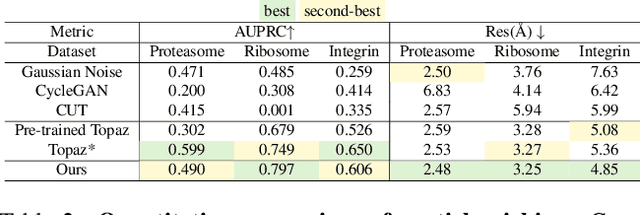
In the past decade, deep conditional generative models have revolutionized the generation of realistic images, extending their application from entertainment to scientific domains. Single-particle cryo-electron microscopy (cryo-EM) is crucial in resolving near-atomic resolution 3D structures of proteins, such as the SARS-COV-2 spike protein. To achieve high-resolution reconstruction, AI models for particle picking and pose estimation have been adopted. However, their performance is still limited as they lack high-quality annotated datasets. To address this, we introduce physics-informed generative cryo-electron microscopy (GenEM), which for the first time integrates physical-based cryo-EM simulation with a generative unpaired noise translation to generate physically correct synthetic cryo-EM datasets with realistic noises. Initially, GenEM simulates the cryo-EM imaging process based on a virtual specimen. To generate realistic noises, we leverage an unpaired noise translation via contrastive learning with a novel mask-guided sampling scheme. Extensive experiments show that GenEM is capable of generating realistic cryo-EM images. The generated dataset can further enhance particle picking and pose estimation models, eventually improving the reconstruction resolution. We will release our code and annotated synthetic datasets.
Discovering Predictable Latent Factors for Time Series Forecasting
Mar 18, 2023Modern time series forecasting methods, such as Transformer and its variants, have shown strong ability in sequential data modeling. To achieve high performance, they usually rely on redundant or unexplainable structures to model complex relations between variables and tune the parameters with large-scale data. Many real-world data mining tasks, however, lack sufficient variables for relation reasoning, and therefore these methods may not properly handle such forecasting problems. With insufficient data, time series appear to be affected by many exogenous variables, and thus, the modeling becomes unstable and unpredictable. To tackle this critical issue, in this paper, we develop a novel algorithmic framework for inferring the intrinsic latent factors implied by the observable time series. The inferred factors are used to form multiple independent and predictable signal components that enable not only sparse relation reasoning for long-term efficiency but also reconstructing the future temporal data for accurate prediction. To achieve this, we introduce three characteristics, i.e., predictability, sufficiency, and identifiability, and model these characteristics via the powerful deep latent dynamics models to infer the predictable signal components. Empirical results on multiple real datasets show the efficiency of our method for different kinds of time series forecasting. The statistical analysis validates the predictability of the learned latent factors.
Federated Forest
May 24, 2019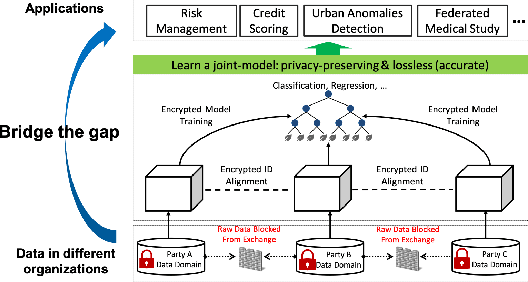
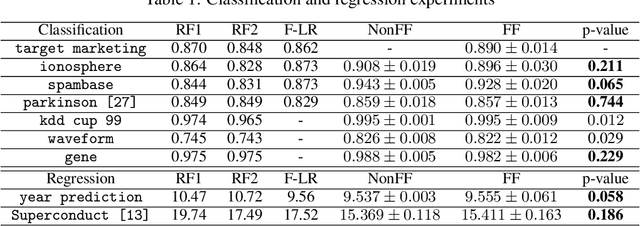
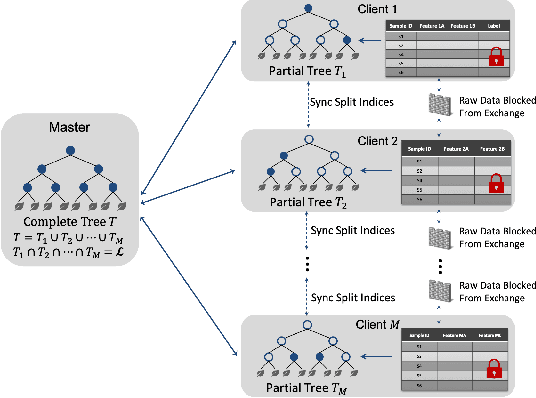
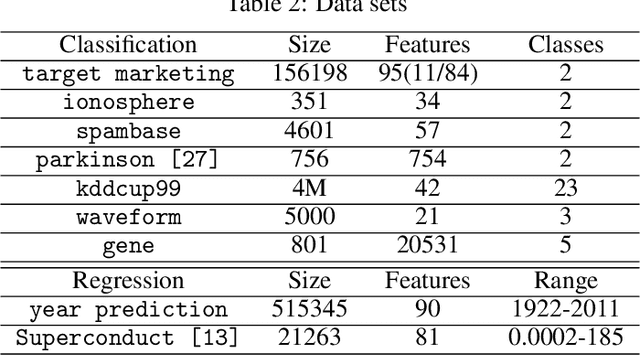
Most real-world data are scattered across different companies or government organizations, and cannot be easily integrated under data privacy and related regulations such as the European Union's General Data Protection Regulation (GDPR) and China' Cyber Security Law. Such data islands situation and data privacy & security are two major challenges for applications of artificial intelligence. In this paper, we tackle these challenges and propose a privacy-preserving machine learning model, called Federated Forest, which is a lossless learning model of the traditional random forest method, i.e., achieving the same level of accuracy as the non-privacy-preserving approach. Based on it, we developed a secure cross-regional machine learning system that allows a learning process to be jointly trained over different regions' clients with the same user samples but different attribute sets, processing the data stored in each of them without exchanging their raw data. A novel prediction algorithm was also proposed which could largely reduce the communication overhead. Experiments on both real-world and UCI data sets demonstrate the performance of the Federated Forest is as accurate as the non-federated version. The efficiency and robustness of our proposed system had been verified. Overall, our model is practical, scalable and extensible for real-life tasks.