 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOI Alias Discovery in Delivery Addresses using User Locations
Sep 20, 2021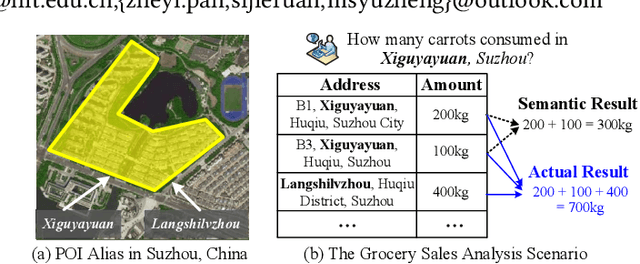
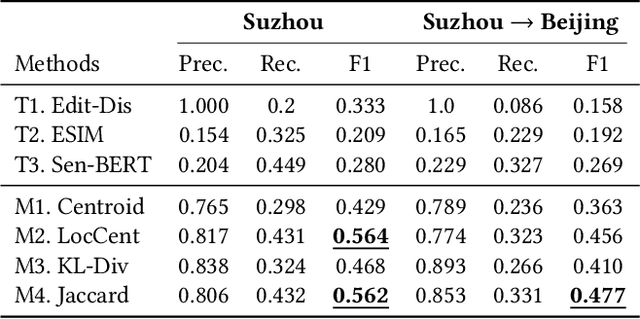
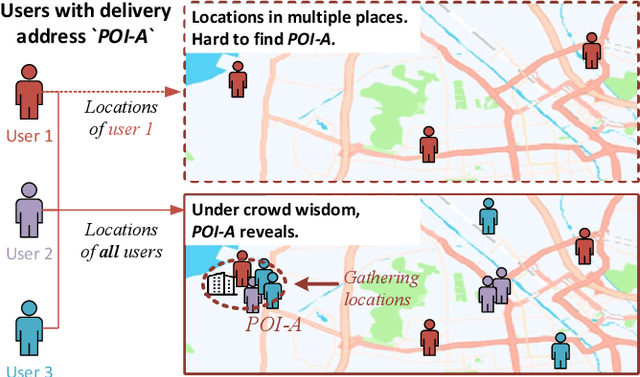
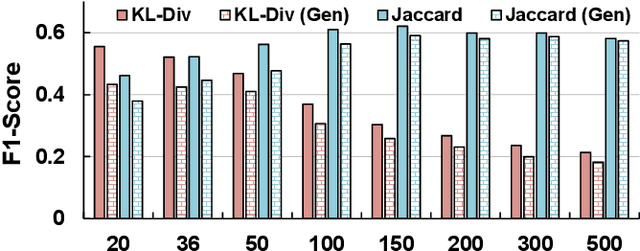
People often refer to a place of interest (POI) by an alias. In e-commerce scenarios, the POI alias problem affects the quality of the delivery address of online orders, bringing substantial challenges to intelligent logistics systems and market decision-making. Labeling the aliases of POIs involves heavy human labor, which is inefficient and expensive. Inspired by the observation that the users' GPS locations are highly related to their delivery address, we propose a ubiquitous alias discovery framework. Firstly, for each POI name in delivery addresses, the location data of its associated users, namely Mobility Profile are extracted. Then, we identify the alias relationship by modeling the similarity of mobility profiles. Comprehensive experiments on the large-scale location data and delivery address data from JD logistics validate the effectiveness.
Federated Forest
May 24, 2019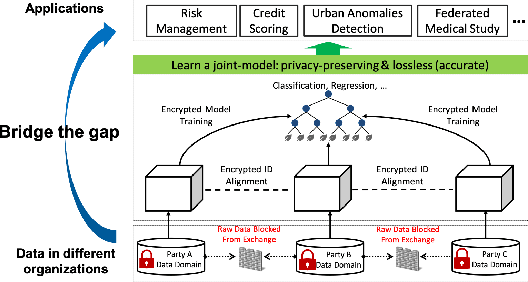
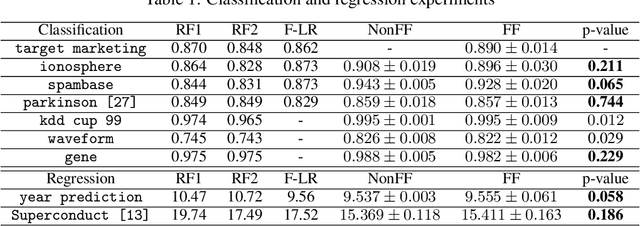
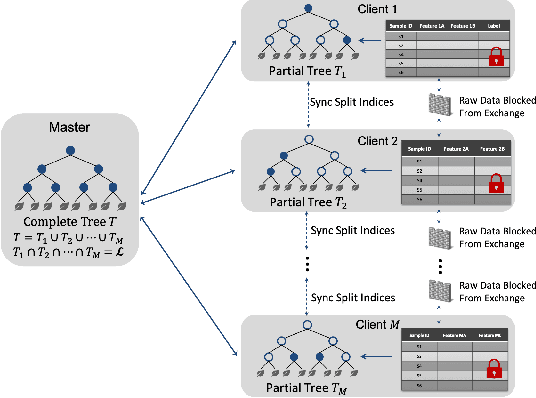
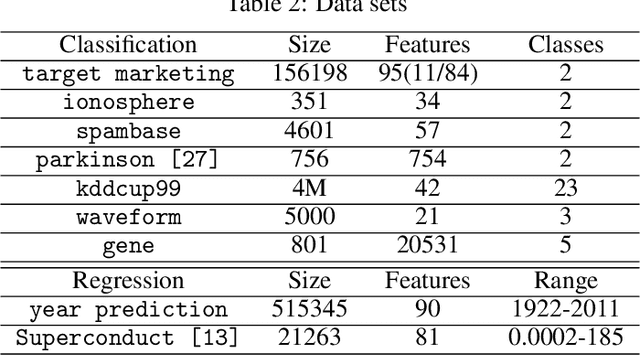
Most real-world data are scattered across different companies or government organizations, and cannot be easily integrated under data privacy and related regulations such as the European Union's General Data Protection Regulation (GDPR) and China' Cyber Security Law. Such data islands situation and data privacy & security are two major challenges for applications of artificial intelligence. In this paper, we tackle these challenges and propose a privacy-preserving machine learning model, called Federated Forest, which is a lossless learning model of the traditional random forest method, i.e., achieving the same level of accuracy as the non-privacy-preserving approach. Based on it, we developed a secure cross-regional machine learning system that allows a learning process to be jointly trained over different regions' clients with the same user samples but different attribute sets, processing the data stored in each of them without exchanging their raw data. A novel prediction algorithm was also proposed which could largely reduce the communication overhead. Experiments on both real-world and UCI data sets demonstrate the performance of the Federated Forest is as accurate as the non-federated version. The efficiency and robustness of our proposed system had been verified. Overall, our model is practical, scalable and extensible for real-life tasks.
Finding Similar Medical Questions from Question Answering Websites
Oct 14, 2018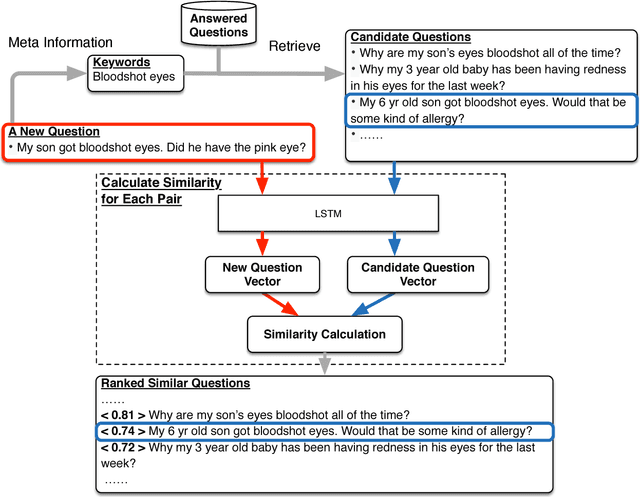

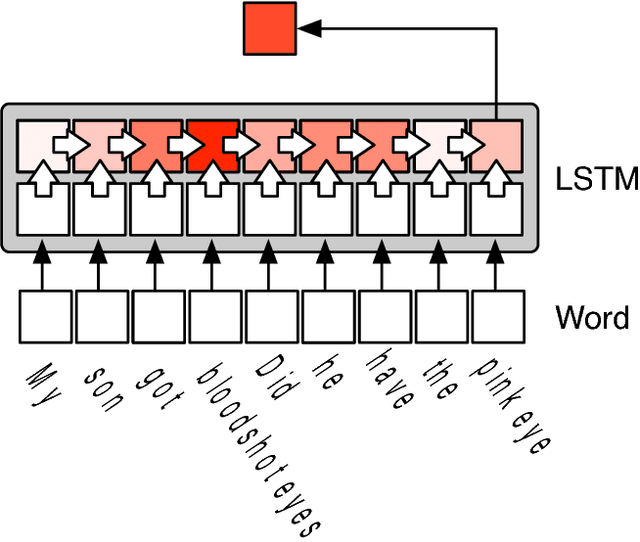

The past few years have witnessed the flourishing of crowdsourced medical question answering (Q&A) websites. Patients who have medical information demands tend to post questions about their health conditions on these crowdsourced Q&A websites and get answers from other users. However, we observe that a large portion of new medical questions cannot be answered in time or receive only few answers from these websites. On the other hand, we notice that solved questions have great potential to solve this challenge. Motivated by these, we propose an end-to-end system that can automatically find similar questions for unsolved medical questions. By learning the vector presentation of unsolved questions and their candidate similar questions, the proposed system outputs similar questions according to the similarity between vector representations. Through the vector representation, the similar questions are found at the question level, and the diversity of medical questions expression issue can be addressed. Further, we handle two more important issues, i.e., training data generation issue and efficiency issue, associated with the LSTM training procedure and the retrieval of candidate similar questions. The effectiveness of the proposed system is validated on a large-scale real-world dataset collected from a crowdsourced maternal-infant Q&A website.