 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Similar Medical Questions from Question Answering Websites
Paper and Code
Oct 14, 2018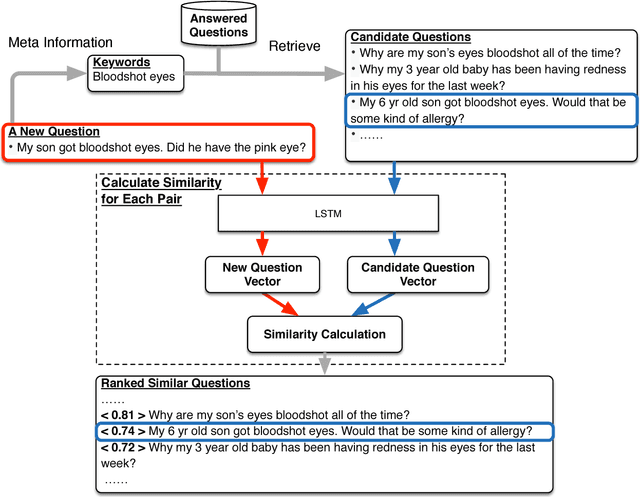

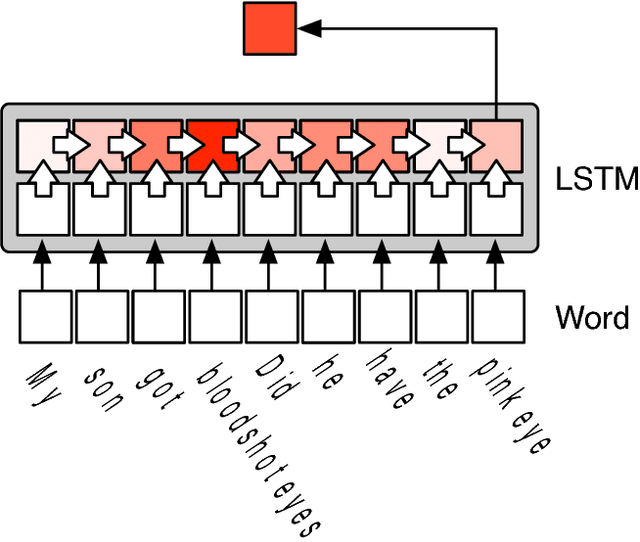

The past few years have witnessed the flourishing of crowdsourced medical question answering (Q&A) websites. Patients who have medical information demands tend to post questions about their health conditions on these crowdsourced Q&A websites and get answers from other users. However, we observe that a large portion of new medical questions cannot be answered in time or receive only few answers from these websites. On the other hand, we notice that solved questions have great potential to solve this challenge. Motivated by these, we propose an end-to-end system that can automatically find similar questions for unsolved medical questions. By learning the vector presentation of unsolved questions and their candidate similar questions, the proposed system outputs similar questions according to the similarity between vector representations. Through the vector representation, the similar questions are found at the question level, and the diversity of medical questions expression issue can be addressed. Further, we handle two more important issues, i.e., training data generation issue and efficiency issue, associated with the LSTM training procedure and the retrieval of candidate similar questions. The effectiveness of the proposed system is validated on a large-scale real-world dataset collected from a crowdsourced maternal-infant Q&A website.