 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolCLIP: A Molecular-Auxiliary CLIP Framework for Identifying Drug Mechanism of Action Based on Time-Lapsed Mitochondrial Images
Jul 10, 2025



Drug Mechanism of Action (MoA) mainly investigates how drug molecules interact with cells, which is crucial for drug discovery and clinical application. Recently, deep learning models have been used to recognize MoA by relying on high-content and fluorescence images of cells exposed to various drugs. However, these methods focus on spatial characteristics while overlooking the temporal dynamics of live cells. Time-lapse imaging is more suitable for observing the cell response to drugs. Additionally, drug molecules can trigger cellular dynamic variations related to specific MoA. This indicates that the drug molecule modality may complement the image counterpart. This paper proposes MolCLIP, the first visual language model to combine microscopic cell video- and molecule-modalities. MolCLIP designs a molecule-auxiliary CLIP framework to guide video features in learning the distribution of the molecular latent space. Furthermore, we integrate a metric learning strategy with MolCLIP to optimize the aggregation of video features. Experimental results on the MitoDataset demonstrate that MolCLIP achieves improvements of 51.2% and 20.5% in mAP for drug identification and MoA recognition, respectively.
Unveiling the Impact of Multimodal Features on Chinese Spelling Correction: From Analysis to Design
Apr 10, 2025
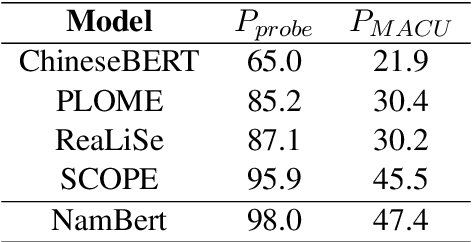
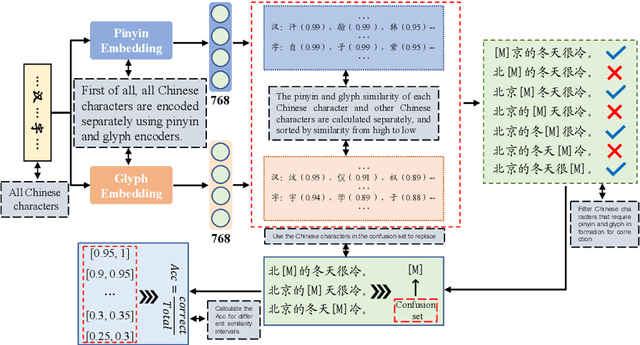
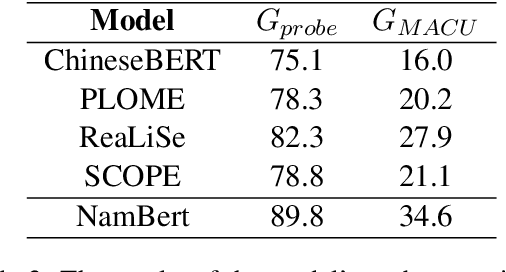
The Chinese Spelling Correction (CSC) task focuses on detecting and correcting spelling errors in sentences. Current research primarily explores two approaches: traditional multimodal pre-trained models and large language models (LLMs). However, LLMs face limitations in CSC, particularly over-correction, making them suboptimal for this task. While existing studies have investigated the use of phonetic and graphemic information in multimodal CSC models, effectively leveraging these features to enhance correction performance remains a challenge. To address this, we propose the Multimodal Analysis for Character Usage (\textbf{MACU}) experiment, identifying potential improvements for multimodal correctison. Based on empirical findings, we introduce \textbf{NamBert}, a novel multimodal model for Chinese spelling correction. Experiments on benchmark datasets demonstrate NamBert's superiority over SOTA methods. We also conduct a comprehensive comparison between NamBert and LLMs, systematically evaluating their strengths and limitations in CSC. Our code and model are available at https://github.com/iioSnail/NamBert.
Research on Domain-Specific Chinese Spelling Correction Method Based on Plugin Extension Modules
Nov 15, 2024



This paper proposes a Chinese spelling correction method based on plugin extension modules, aimed at addressing the limitations of existing models in handling domain-specific texts. Traditional Chinese spelling correction models are typically trained on general-domain datasets, resulting in poor performance when encountering specialized terminology in domain-specific texts. To address this issue, we design an extension module that learns the features of domain-specific terminology, thereby enhancing the model's correction capabilities within specific domains. This extension module can provide domain knowledge to the model without compromising its general spelling correction performance, thus improving its accuracy in specialized fields. Experimental results demonstrate that after integrating extension modules for medical, legal, and official document domains, the model's correction performance is significantly improved compared to the baseline model without any extension modules.