 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Impact of Multimodal Features on Chinese Spelling Correction: From Analysis to Design
Paper and Code

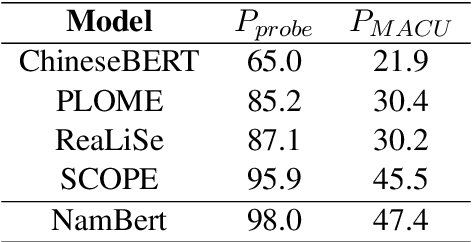
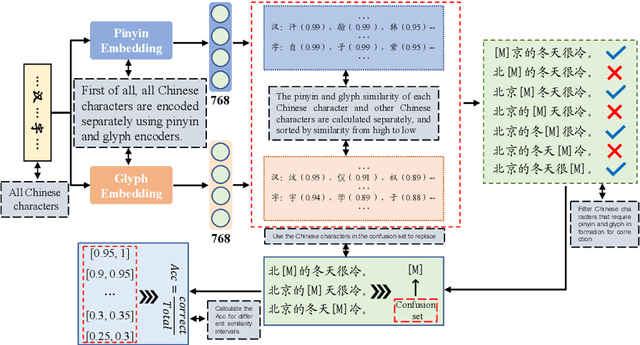
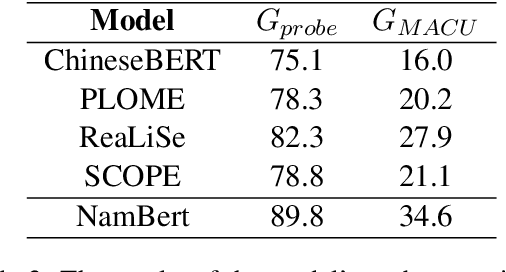
The Chinese Spelling Correction (CSC) task focuses on detecting and correcting spelling errors in sentences. Current research primarily explores two approaches: traditional multimodal pre-trained models and large language models (LLMs). However, LLMs face limitations in CSC, particularly over-correction, making them suboptimal for this task. While existing studies have investigated the use of phonetic and graphemic information in multimodal CSC models, effectively leveraging these features to enhance correction performance remains a challenge. To address this, we propose the Multimodal Analysis for Character Usage (\textbf{MACU}) experiment, identifying potential improvements for multimodal correctison. Based on empirical findings, we introduce \textbf{NamBert}, a novel multimodal model for Chinese spelling correction. Experiments on benchmark datasets demonstrate NamBert's superiority over SOTA methods. We also conduct a comprehensive comparison between NamBert and LLMs, systematically evaluating their strengths and limitations in CSC. Our code and model are available at https://github.com/iioSnail/NamBert.