 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Sparsity-Aware Privacy-Preserving K-means Clustering with Application to Fraud Detection
Aug 12, 2022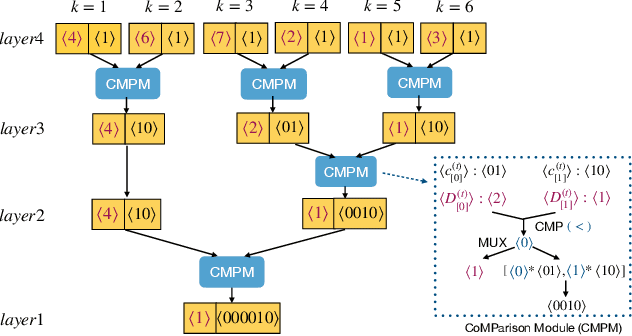
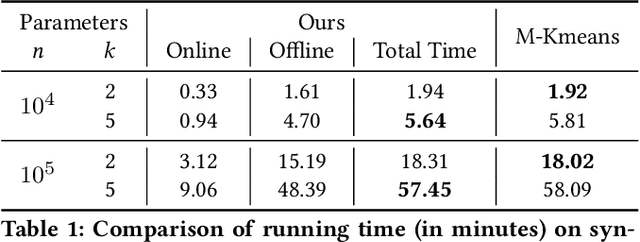
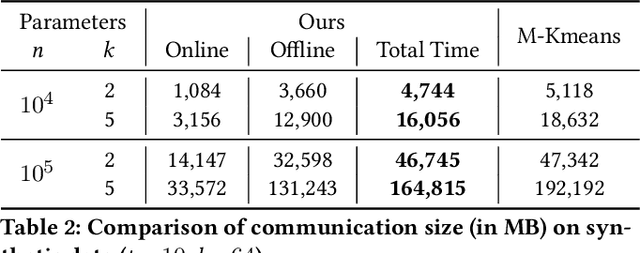
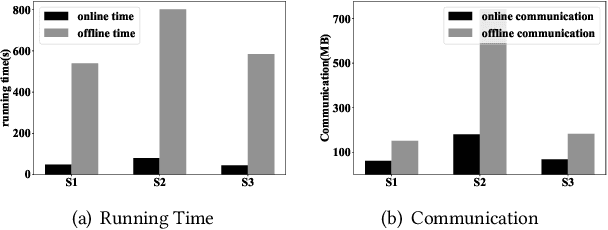
K-means is one of the most widely used clustering models in practice. Due to the problem of data isolation and the requirement for high model performance, how to jointly build practical and secure K-means for multiple parties has become an important topic for many applications in the industry. Existing work on this is mainly of two types. The first type has efficiency advantages, but information leakage raises potential privacy risks. The second type is provable secure but is inefficient and even helpless for the large-scale data sparsity scenario. In this paper, we propose a new framework for efficient sparsity-aware K-means with three characteristics. First, our framework is divided into a data-independent offline phase and a much faster online phase, and the offline phase allows to pre-compute almost all cryptographic operations. Second, we take advantage of the vectorization techniques in both online and offline phases. Third, we adopt a sparse matrix multiplication for the data sparsity scenario to improve efficiency further. We conduct comprehensive experiments on three synthetic datasets and deploy our model in a real-world fraud detection task. Our experimental results show that, compared with the state-of-the-art solution, our model achieves competitive performance in terms of both running time and communication size, especially on sparse datasets.
Exploiting Data Sparsity in Secure Cross-Platform Social Recommendation
Feb 15, 2022


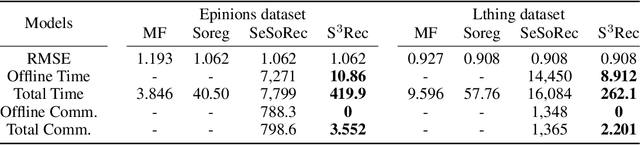
Social recommendation has shown promising improvements over traditional systems since it leverages social correlation data as an additional input. Most existing work assumes that all data are available to the recommendation platform. However, in practice, user-item interaction data (e.g.,rating) and user-user social data are usually generated by different platforms, and both of which contain sensitive information. Therefore, "How to perform secure and efficient social recommendation across different platforms, where the data are highly-sparse in nature" remains an important challenge. In this work, we bring secure computation techniques into social recommendation, and propose S3Rec, a sparsity-aware secure cross-platform social recommendation framework. As a result, our model can not only improve the recommendation performance of the rating platform by incorporating the sparse social data on the social platform, but also protect data privacy of both platforms. Moreover, to further improve model training efficiency, we propose two secure sparse matrix multiplication protocols based on homomorphic encryption and private information retrieval. Our experiments on two benchmark datasets demonstrate the effectiveness of S3Rec.
Practical and Light-weight Secure Aggregation for Federated Submodel Learning
Nov 02, 2021
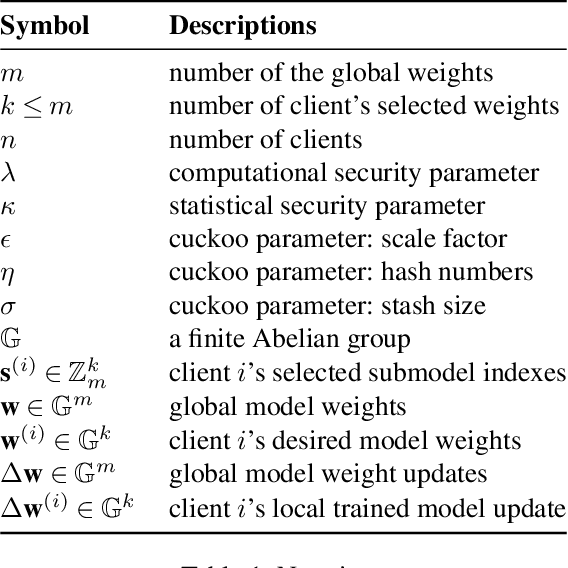
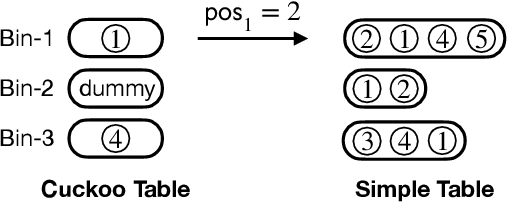

Recently, Niu, et. al. introduced a new variant of Federated Learning (FL), called Federated Submodel Learning (FSL). Different from traditional FL, each client locally trains the submodel (e.g., retrieved from the servers) based on its private data and uploads a submodel at its choice to the servers. Then all clients aggregate all their submodels and finish the iteration. Inevitably, FSL introduces two privacy-preserving computation tasks, i.e., Private Submodel Retrieval (PSR) and Secure Submodel Aggregation (SSA). Existing work fails to provide a loss-less scheme, or has impractical efficiency. In this work, we leverage Distributed Point Function (DPF) and cuckoo hashing to construct a practical and light-weight secure FSL scheme in the two-server setting. More specifically, we propose two basic protocols with few optimisation techniques, which ensures our protocol practicality on specific real-world FSL tasks. Our experiments show that our proposed protocols can finish in less than 1 minute when weight sizes $\leq 2^{15}$, we also demonstrate protocol efficiency by comparing with existing work and by handling a real-world FSL task.
Survey and Open Problems in Privacy Preserving Knowledge Graph: Merging, Query, Representation, Completion and Applications
Nov 20, 2020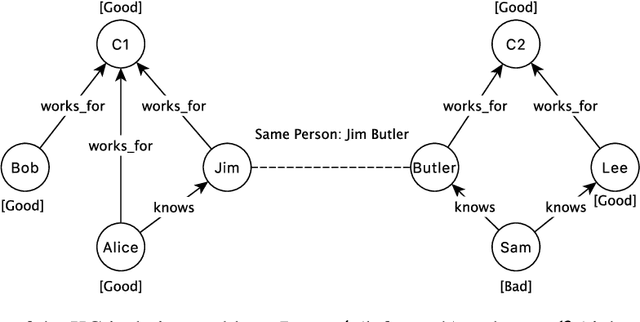

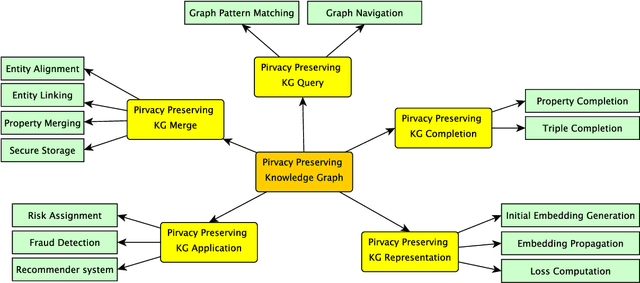

Knowledge Graph (KG) has attracted more and more companies' attention for its ability to connect different types of data in meaningful ways and support rich data services. However, the data isolation problem limits the performance of KG and prevents its further development. That is, multiple parties have their own KGs but they cannot share with each other due to regulation or competition reasons. Therefore, how to conduct privacy preserving KG becomes an important research question to answer. That is, multiple parties conduct KG related tasks collaboratively on the basis of protecting the privacy of multiple KGs. To date, there is few work on solving the above KG isolation problem. In this paper, to fill this gap, we summarize the open problems for privacy preserving KG in data isolation setting and propose possible solutions for them. Specifically, we summarize the open problems in privacy preserving KG from four aspects, i.e., merging, query, representation, and completion. We present these problems in details and propose possible technical solutions for them. Moreover, we present three privacy preserving KG-aware applications and simply describe how can our proposed techniques be applied into these applications.