 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Sparsity-Aware Privacy-Preserving K-means Clustering with Application to Fraud Detection
Paper and Code
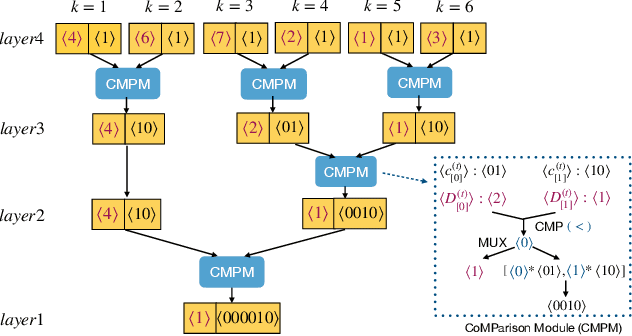
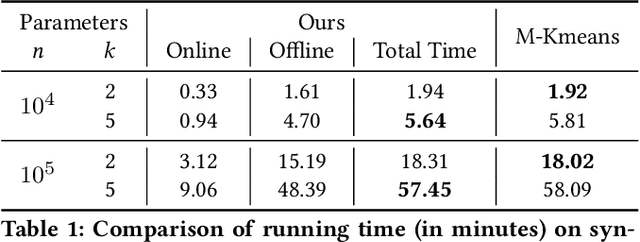
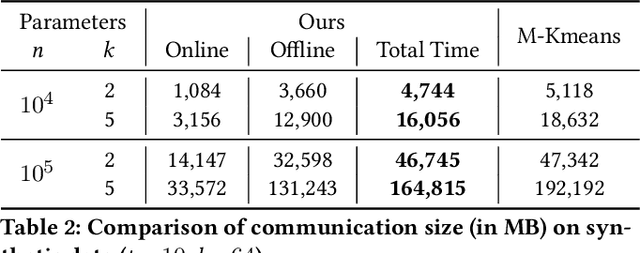
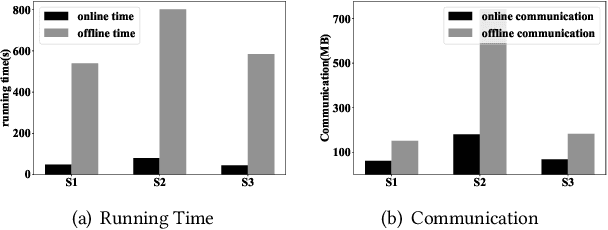
K-means is one of the most widely used clustering models in practice. Due to the problem of data isolation and the requirement for high model performance, how to jointly build practical and secure K-means for multiple parties has become an important topic for many applications in the industry. Existing work on this is mainly of two types. The first type has efficiency advantages, but information leakage raises potential privacy risks. The second type is provable secure but is inefficient and even helpless for the large-scale data sparsity scenario. In this paper, we propose a new framework for efficient sparsity-aware K-means with three characteristics. First, our framework is divided into a data-independent offline phase and a much faster online phase, and the offline phase allows to pre-compute almost all cryptographic operations. Second, we take advantage of the vectorization techniques in both online and offline phases. Third, we adopt a sparse matrix multiplication for the data sparsity scenario to improve efficiency further. We conduct comprehensive experiments on three synthetic datasets and deploy our model in a real-world fraud detection task. Our experimental results show that, compared with the state-of-the-art solution, our model achieves competitive performance in terms of both running time and communication size, especially on sparse datasets.